Visual-RFT:基于强化学习的视觉语言模型微调技术研究
Visual-RFT 代表了视觉语言模型微调领域的技术创新,通过将基于规则的可验证奖励与强化学习相结合,有效克服了传统监督微调 (SFT) 在数据稀缺场景下的局限性。本文将深入剖析 Visual-RFT 的技术原理,结合原始研究论文中的图表解释其架构设计,并探讨该方法在实际应用场景中的潜力。
Visual-RFT 的核心理念在于促进模型通过渐进式推理进行学习,而非简单地记忆标准答案。该方法鼓励模型生成多样化的响应并进行自主推理,随后基于答案正确性的验证信号调整学习方向。这种强化微调机制在对象检测和图像分类等视觉任务中表现尤为突出,即使在极少量样本情况下(如一次性或少样本学习场景),模型仍能通过试错学习实现优异性能表现。
Visual-RFT 架构详解
下图展示了论文中的主要架构图(包含子图 (a)、(b) 和 (c)),系统呈现了 Visual-RFT 从数据输入到应用部署的完整技术流程: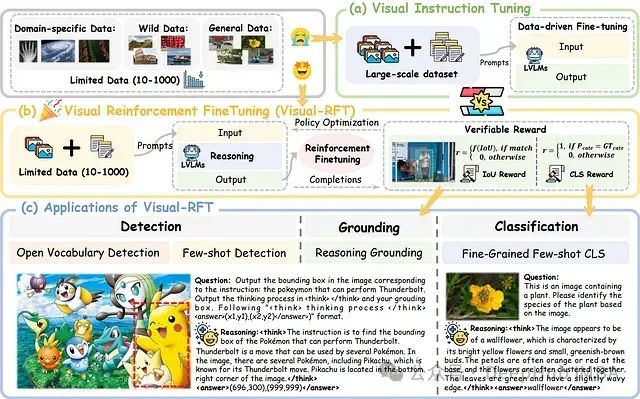
Visual-RFT 架构:(a) 视觉指令调整,(b) 视觉强化微调,以及 (c) Visual-RFT 的应用
https://avoid.overfit.cn/post/47909ebf77044bb6b46395dae26819d1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号