Vision Transformer中的图像块嵌入详解:线性投影和二维卷积的数学原理与代码实现
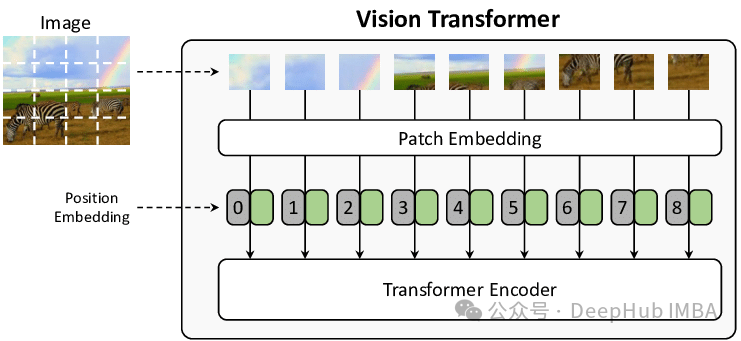
Transformer 架构因其强大的通用性而备受瞩目,它能够处理文本、图像或任何类型的数据及其组合。其核心的“Attention”机制通过计算序列中每个 token 之间的自相似性,从而实现对各种类型数据的总结和生成。在 Vision Transformer 中,图像首先被分解为正方形图像块,然后将这些图像块展平为单个向量嵌入。这些嵌入可以被视为与文本嵌入(或任何其他嵌入)完全相同,甚至可以与其他数据类型进行连接。通常图像块的创建步骤会与使用 2D 卷积的第一个可学习的非线性变换相结合,这对于初学者来说可能比较难以理解,所以本文将深入探讨这一过程。
https://avoid.overfit.cn/post/6d5b2b3506f044caa3cc49bf611a3632

 浙公网安备 33010602011771号
浙公网安备 33010602011771号