SCOPE:面向大语言模型长序列生成的双阶段KV缓存优化框架
Key-Value (KV)缓存已成为大语言模型(LLM)长文本处理的关键性能瓶颈。当前研究尚未充分关注解码阶段的优化,这一阶段具有同等重要性,因为:
1、对需要完整上下文的场景,预填充阶段的过度压缩会显著降低模型的推理理解能力
2、在长输出推理任务中存在重要特征的显著偏移现象
这篇论文提出SCOPE框架,通过分离预填充与解码阶段的KV缓存优化策略,实现高效的缓存管理。该框架保留预填充阶段的关键KV缓存信息,同时引入基于滑动窗口的新型策略,用于解码阶段重要特征的高效选取。
关键发现
KV缓存的推理过程分析
LLM的每次请求包含两个独立阶段:预填充阶段处理完整输入提示以生成初始输出标记;解码阶段通过迭代方式逐个生成后续输出标记。
预填充阶段分析
下图展示了在完整解码缓存条件下,三个任务在不同预填充阶段压缩比率下的性能表现:
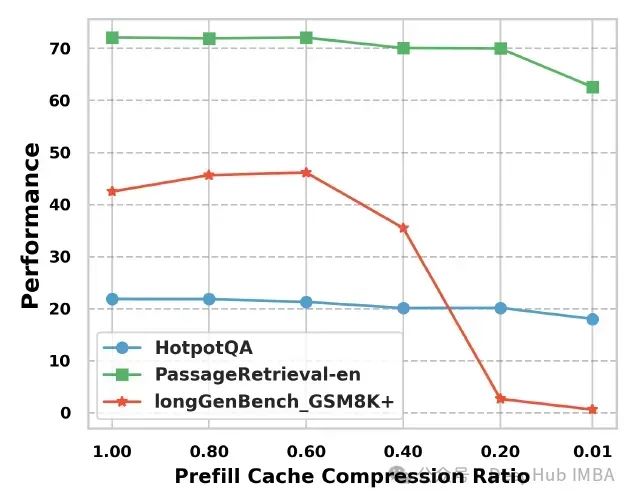
Long-Bench中的PassageRetrieval-en和HotpotQA任务表现出显著的压缩容忍度:即使在20%的预填充阶段压缩比率下,模型仍能保持与完整缓存相近的性能水平,证实了模型在高压缩率下维持上下文理解能力的鲁棒性。然而在LONGGENBENCH的GSM8k+任务中,同样的20%压缩率导致准确率下降约95%
实验结果表明:对于依赖完整上下文的推理任务,预填充阶段的过度压缩会导致显著的性能损失
https://avoid.overfit.cn/post/e5ac0b501a1e4a4fb62eedcf49cd8675

 浙公网安备 33010602011771号
浙公网安备 33010602011771号