LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
在人工智能迅速发展的今天,多模态系统正成为推动视觉语言任务前沿发展的关键。CLIP(对比语言-图像预训练)作为其中的典范,通过将文本和视觉表示对齐到共享的特征空间,为图像-文本检索、分类和分割等任务带来了革命性突破。然而其文本编码器的局限性使其在处理复杂长文本和多语言任务时显得力不从心。
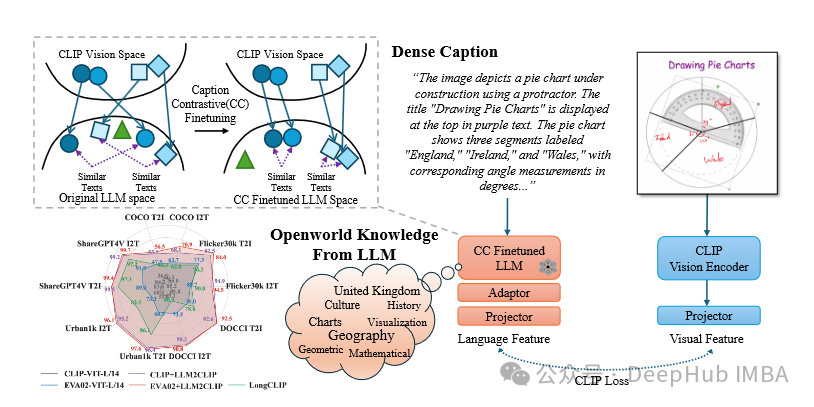
大型语言模型(LLM),如 GPT-4 和 LLaMA,则展示了卓越的语言理解和生成能力。这种强大的语言能力能否与 CLIP 结合,解决其文本编码器的短板?微软团队提出的 LLM2CLIP 框架便是这一创新的成果。
该论文提出了一种创新的方法,通过将 LLM 强大的语言知识与 CLIP 的视觉能力相结合,显著提升多模态任务的性能。通过整合 LLM 和 CLIP,LLM2CLIP 解决了传统 CLIP 在文本理解、语言支持和任务泛化方面的瓶颈。
https://avoid.overfit.cn/post/1ce67e3778c64bf2919b19dae39c4d71

 浙公网安备 33010602011771号
浙公网安备 33010602011771号