使用 Python TorchRL 进行多代理强化学习
随着多代理系统的出现,强化学习的复杂性不断增加。为了管理这种复杂性,像 TorchRL 这样的专门工具提供了一个强大的框架,可以开发和实验多代理强化学习(MARL)算法。本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
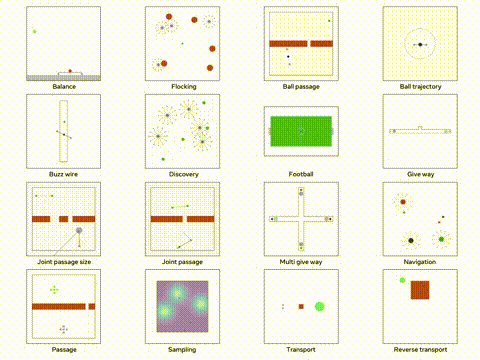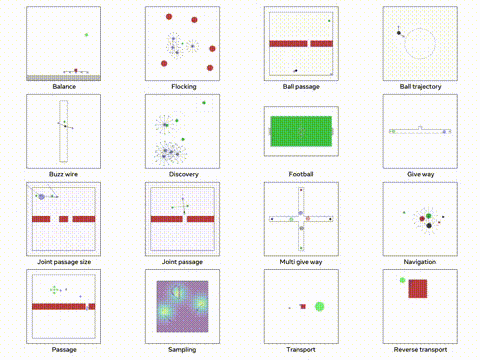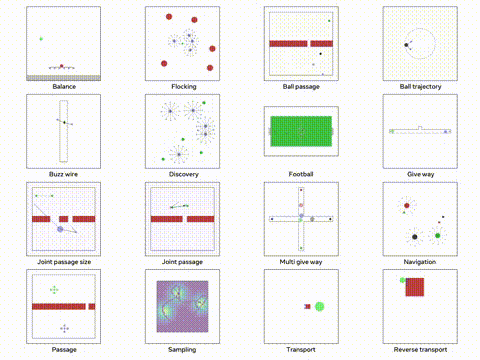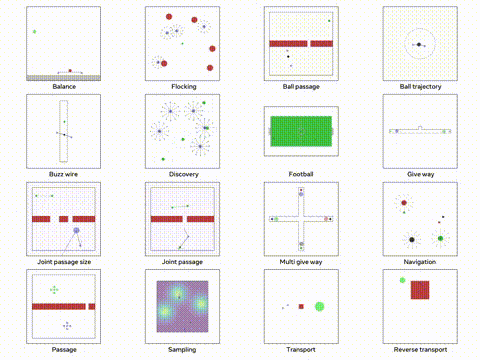
我们将使用 VMAS 模拟器,这是一个多机器人模拟器并且可以在 GPU 上进行并行训练。他的主要目标多个机器人必须导航到各自的目标,同时避免碰撞。
随着多代理系统的出现,强化学习的复杂性不断增加。为了管理这种复杂性,像 TorchRL 这样的专门工具提供了一个强大的框架,可以开发和实验多代理强化学习(MARL)算法。本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
我们将使用 VMAS 模拟器,这是一个多机器人模拟器并且可以在 GPU 上进行并行训练。他的主要目标多个机器人必须导航到各自的目标,同时避免碰撞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号