flink平台项目-cnblog
# flink平台项目
目录
- 架构
- 以前架构
- 现在架构的说明
- CDH&集群规模
- 人员配备
- 开发周期
- 为什么用flinkcdc
- 项目好处
- 千表入湖工具
- flink操作hive
- flink集成hive的步骤
- flinksql 数据源为kafka
- flink读写sql有两种模式
- Temporal Join(时态表join)
- lookup join
- 常见面试题
title: flink平台项目
date: 2023-01-30T11:26:01Z
lastmod: 2023-02-02T19:27:41Z
架构

以前架构

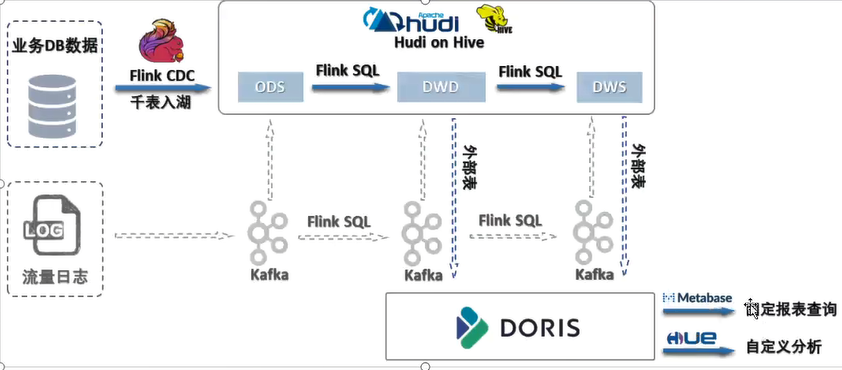
问题:
- 需要第三方组件进行持久化,需要增加维护的工作量
- kafka计算的各分层数据存储在kafka集群中,增加持久化的链路
- Debezium 定继单节点 出现单点故障
- hbase存储的时候, kv键值对 , rowkey是主键,使用rowkey查询非常快,但是与非主键数据拉宽,效率较低
比如id 是rowkey,name不是rowkey ,关联name的时候不是rowkey,关联的时候就不快(可以使用二级索引(phenx)加快)
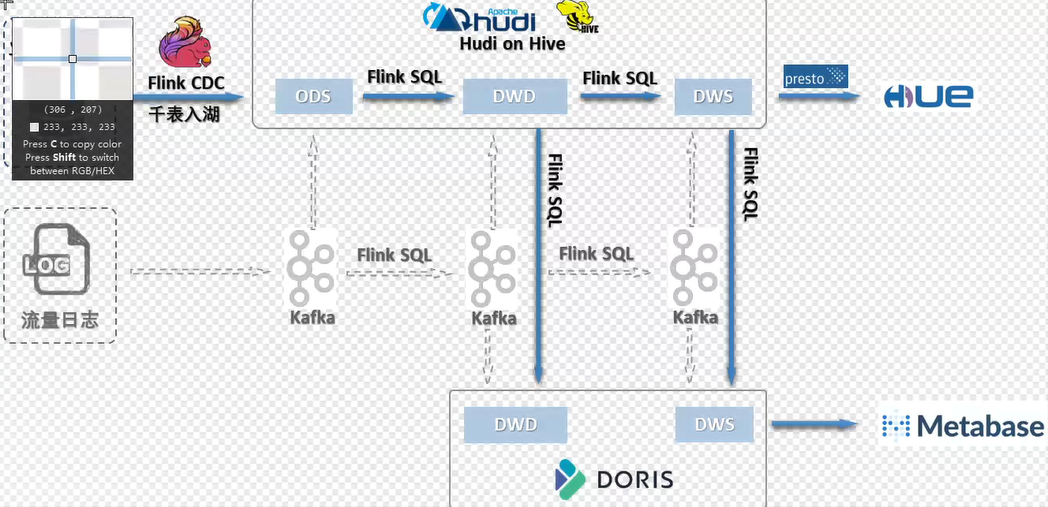
现在架构的说明
dinky 千表入湖
hudi = kafka + hive(操作的是hdfs)
海量数据不丢失
hudi分钟级 准实时. T+1延迟问题得到解决
读取schema不再需要严格定义schema类型
支持数据库表结构的变化
hudi新版本现在支持外部表 0.11.0 ,doris直接外部表读hudi数据,也就是只是hudi中存一份数据
CDH&集群规模
6.3 一台一万
阿里云主机(128G内存 20核cpu 40线程 8THDD 2TSSD) 每年5万

人员配备

开发周期

为什么用flinkcdc
支持全量+增量的功能
项目好处
链路短好维护
- 时效性
- 流批一体
- 复杂的链路
千表入湖工具
阿里云用ververica
flink操作hive
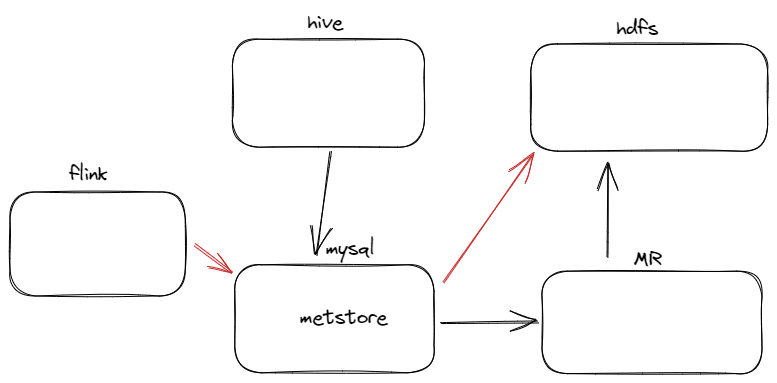
和spark-thrift类似
flink集成hive的步骤
flink 借用了hive 的metastore
- 将jar包上传到flink lib 目录下
- 配置sql-conf , 主要hive catelog ,后续的操作都是基于hive 库和表
-
catelog是什么: 指定读取哪里的元数据
-
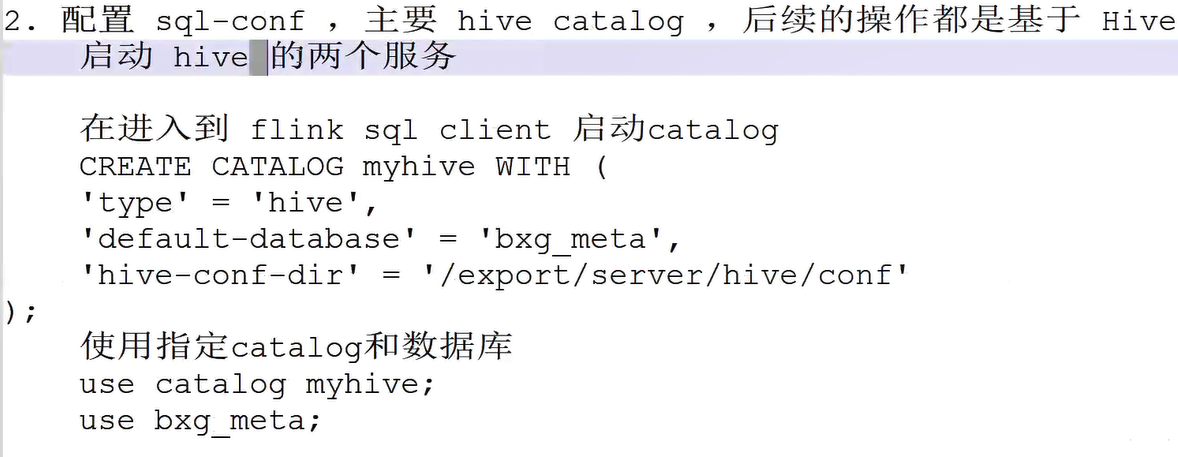
-
flinksql 数据源为kafka
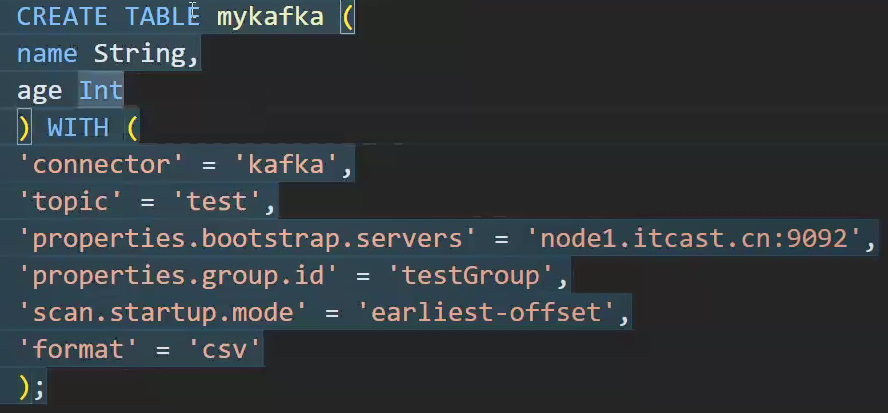
flink读写sql有两种模式
自带的模式

hive的模式

用处:

Temporal Join(时态表join)
单流驱动
一般指的是两个数据流
反应历史不同变化的维度数据
lookup join
指的是数据流和外部表 mysql redis 进行关联统计, 没有历史变化的信息
常见面试题



 浙公网安备 33010602011771号
浙公网安备 33010602011771号