TensorFlow中的并行执行引擎——StreamExecutor框架
背景
[作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor]
欢迎大家关注我的公众号,“互联网西门二少”,我将继续输出我的技术干货~

在前一篇文章中,我们梳理了TensorFlow中各种异构Device的添加和注册机制,通过使用预先定义好的宏,各种自定义好的Device能够将自己注册到全局表中。TensorFlow期望通过这种模式,能够让Device的添加和注册于系统本身更好的解耦,从而体现了较好的模块化特性。在这篇文章中,我们选择直接去窥探TensorFlow底层架构较为复杂的一个部分——StreamExecutor框架。我们已经知道TensorFlow是一个异构的并行执行框架,对于异构Device的管理是一件非常复杂的事,不仅包括Device的添加、注册、删除、属性的管理,还必须要对Device的并行执行过程做进一步抽象形成统一的框架,才能实现更好的解耦。通过阅读这部分源码不但可以对执行引擎的管理有很深的理解,还可以体验学习到各种设计模式。如果想要对TensorFlow底层甚至是XLA做一些性能上的深度优化,那么这一部分则是必须要了解的内容。
Stream
Stream存在于计算机相关的各种技术中,比如在操作系统、流式计算、计算机网络传输或是CUDA编程中都有涉及。Stream从抽象角度来看其本质是定义了一个操作序列,处于同一个Stream的操作必须按顺序执行,不同Stream之间的并无顺序关系。在TensorFlow中存在一些高性能的并行编程设备,所以需要有一套抽象框架对这些设备的执行过程管理起来,这就是StreamExecutor的用武之地了。
StreamExecutor简介
其实StreamExecutor本身就是一个在Google内部为并行编程模型开发的单独的库,感兴趣的可以直接参考GitHub。在TensorFlow中的StreamExecutor是一个开源StreamExecutor的简版,并且并不是以第三方库的形式出现,而是在源码中单独放了一个stream_executor的文件夹,里面的代码非常的精简,目录结构部分截图如下图所示。
StreamExecutor为TensorFlow的执行层面提供了较为统一的抽象,而在底层各种Device的执行管理细节却完全不同。我们可以看到stream_executor下面有cuda和host两个子目录,他们分别是GPU执行引擎和CPU执行引擎所使用的子模块。下面我们先从统一的抽象层面来梳理该框架的结构。
StreamExecutor对外提供的句柄——Stream对象
为了隐藏StreamExecutor框架管理的复杂性,它对外暴露的handler必须足够简单。事实也确实如此,StreamExecutor通过暴露Stream对象作为操作底层的handler。一般而言,在TensorFlow的框架中都是使用Stream对象来调用底层计算库,进行设备间数据拷贝操作等过程。比如调用Stream对象的ThenMemcpy即可完成异步的数据传输拷贝过程,调用ThenConvolveXXX等函数即可完成DNN库中的卷积调用。事实上,TensorFlow中很多Op的C++实现中,其Compute函数内就是通过使用Stream对象来完成某些实际计算或数据拷贝的过程,下图展示了Stream对象、StreamExecutor框架以及其他模块的关系。

Stream对象是通过持有StreamInterface的具体实现对象来获得实际平台的Stream,进而通过Stream这个统一的handler完成与底层的交互,下面试这一子模块的类图结构。
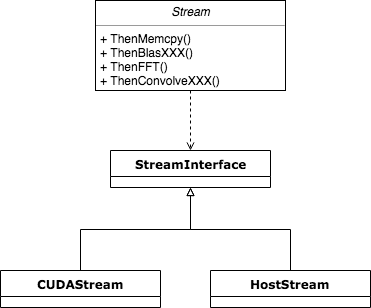
StreamExecutor框架内的层次结构
熟悉GPU编程的同学都知道,CUDA程序的编写是相对复杂的,不但要针对某种任务设计特定的并行编程思路,还要管理Event,Stream等较为底层的对象。为了能够减轻StreamExecutor用户的使用负担,也为了能够给上层调用者即TensorFlow引擎提供更加统一的接口,一些抽象分层的工作是非常有必要的。总体上StreamExecutor框架由三个层次组成,从上到下依次为Platform层(平台描述)、StreamExecutor Core层(执行引擎)和LibrarySupport层(基础库)。如果需要为TensorFlow添加新的计算设备种类,不但要向TensorFlow中注册Device的定义,还需要在StreamExecutor框架中提供负责管理该Device计算的代码。

Platform层
在StreamExecutor中Platform指的是计算所使用设备平台的抽象,每种Device对应一种Platform。比如GPU对应的是CudaPlatform,而CPU对应的是HostPlatform等。一旦获得了某种Device的Platform,就可以获取和该Platform对应的StreamExecutor Core以及相应的LibrarySupport。在TensorFlow的代码实现中,所有Platform类都是通过宏定义和MultiPlatformManager管理类的静态方法主动注册到系统中的,下面是这一层次的类图表示。
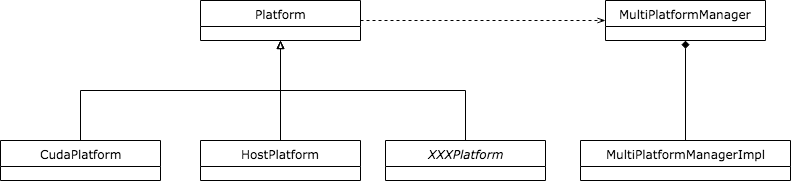
CudaPlatform和HostPlatform继承自公共父类Platform,如果有新的Platform出现,依然可以沿用这样的设计直接继承并给出实现。所有的Platform都通过MultiPlaftormManager调用RegsiterPlatform函数主动注册到系统中并做初始化,下面代码段是CudaPlaftorm的注册过程,注册使用了Initializer模块及相应的宏定义,这些代码比较简单,这里就不再详细展开了。
1 static void InitializeCudaPlatform() { 2 // Disabling leak checking, MultiPlatformManager does not destroy its 3 // registered platforms. 4 5 std::unique_ptr<cuda::CudaPlatform> platform(new cuda::CudaPlatform); 6 SE_CHECK_OK(MultiPlatformManager::RegisterPlatform(std::move(platform))); 7 } 8 9 } // namespace stream_executor 10 11 REGISTER_MODULE_INITIALIZER(cuda_platform, 12 stream_executor::InitializeCudaPlatform()); 13 14 // Note that module initialization sequencing is not supported in the 15 // open-source project, so this will be a no-op there. 16 REGISTER_MODULE_INITIALIZER_SEQUENCE(cuda_platform, multi_platform_manager); 17 REGISTER_MODULE_INITIALIZER_SEQUENCE(multi_platform_manager_listener, 18 cuda_platform);
MultiPlatformManager提供了两种获取具体Platform的方式,一种是通过name,另一种是通过Id,如下代码段所示。
1 // Retrieves the platform registered with the given platform name (e.g. 2 // "CUDA", "OpenCL", ...) or id (an opaque, comparable value provided by the 3 // Platform's Id() method). 4 // 5 // If the platform has not already been initialized, it will be initialized 6 // with a default set of parameters. 7 // 8 // If the requested platform is not registered, an error status is returned. 9 // Ownership of the platform is NOT transferred to the caller -- 10 // the MultiPlatformManager owns the platforms in a singleton-like fashion. 11 static port::StatusOr<Platform*> PlatformWithName(absl::string_view target); 12 static port::StatusOr<Platform*> PlatformWithId(const Platform::Id& id);
StreamExecutor Core层
从源代码上看这一层非常复杂,因为它涉及到的类最多,但是当我们把Platform层和Library层分开看待后,这一层就变得非常简单了。对于外部使用者来说,获取Platform就是为了获取对应的执行引擎。对于TensorFlow这种存在多种Platform和执行引擎的异构框架来说,必须为每一种执行引擎提供完整的实现,这具有一定的复杂度。为了让代码结构更有层次感,也为了向Platform层隐藏底层的设计复杂度,该层选择只向上层暴露StreamExecutor类,而涉及到具体实现的StreamExecutorInterface以及各种具体的实现将由StreamExecutor类统一控制,这种代理的方式让这一层的架构更加干净,下面是涉及到这一层的类图。
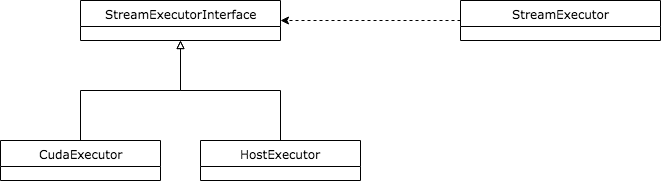
CudaExecutor和HostExecutor继承自StreamExecutorInterface后,由StreamExecutor持有,并暴露给上一层Platform使用。同各种Platform类似,每个具体的StreamExecutor也需要注册到系统中,但他们却没有依赖于任何控制类,直接通过宏定义将自己注册到全局工厂中,注册过程也是借助Initializer模块实现的。下面的代码段展示了CudaExecutor的注册过程。
1 void initialize_cuda_gpu_executor() { 2 *internal::MakeCUDAExecutorImplementation() = [](const PluginConfig &config) { 3 return new cuda::CUDAExecutor{config}; 4 }; 5 } 6 7 } // namespace stream_executor 8 9 REGISTER_MODULE_INITIALIZER(cuda_gpu_executor, { 10 stream_executor::initialize_cuda_gpu_executor(); 11 });
initialize_cuda_gpu_executor函数中定义了一个创建CUDAExecutor的匿名函数,而MakeCUDAExecutorImplementation函数实际上创建了一个全局的table,中间的等号赋值操作实际上就是把该匿名函数放到了全局instance中,这实际上就是一种简单的工厂模式,在StreamExecutor中存在多种类似的工厂,下面代码段展示了这些工厂的本质。
1 using StreamExecutorFactory = 2 std::function<StreamExecutorInterface *(const PluginConfig &)>; 3 using EventFactory = std::function<EventInterface *(StreamExecutor *)>; 4 using StreamFactory = std::function<StreamInterface *(StreamExecutor *)>; 5 using TimerFactory = std::function<TimerInterface *(StreamExecutor *)>; 6 using KernelFactory = std::function<KernelInterface*()>; 7 8 StreamExecutorFactory* MakeCUDAExecutorImplementation();
StreamExecutor框架使用Cache机制避免为同一种StreamExecutor Core被重复创建,这个Cache就是ExecutorCache,下面代码展示了Platform从Cache获取StreamExecutor Core的内容,当Cache中不存在所需要的StreamExecutor时,会创建新的对象并放入cache中,并以config作为key。
1 port::StatusOr<StreamExecutor*> CudaPlatform::GetExecutor( 2 const StreamExecutorConfig& config) { 3 return executor_cache_.GetOrCreate( 4 config, [&]() { return GetUncachedExecutor(config); }); 5 }
Library层
这一层提供的是各种底层加速库的接入,当前该层主要负责接入Dnn,Blas,Rng和Fft模块,每个模块和对应的类说明如下表所示 。
| 子模块名称 | 功能说明 |
| DNNSupport | DNN计算模块,主要包含DNN计算的基本操作。在GPU实现中,它将作为CuDNN的封装 |
| RngSupport | 随机数生成模块 |
| BlasSupport | 基础线性代数库模块,主要包含矩阵系列的计算,在CPU实现中它可以是Eigen,mkl等;在GPU实现中,它将作为CuBLAS的封装 |
| FFTSupport | FFT系列运算模块 |
因为这些基础库同StreamExecutor类似,都具有平台属性,例如在CUDAHostPlatform中使用的Blas库应为CuBLAS,而HostPlatform中对应的可能是OpenBlas,MKL等。虽然StreamExecutorInterface创建出来的各种Library指针均由StreamExecutor持有,但是他们却由StreamExecutorInterface的实现类负责创建,所以从逻辑上看他们处于StreamExecutor Core的下一层,下图展示了Library层的类图。

Library层将这些基础库统一作为插件(Plugin)来管理,用以应对未来出现的各种各样的基础库。他们通过PluginRegister模块注册。和StreamExecutor Core中的管理方式相同,依然要先创建插件的Factory,Factory的创建也通过宏实现。以CudnnSupport为例,通过向通用初始化模块Intializer传入initialize_cudnn函数并调用,将创建CudnnSupport的函数作为DnnFactory放到PluginRegister模块中,至此完成了DnnFactory的创建。使用时,只需要拿到PluginRegister的key(即要求拿到何种插件)即可取出对应的LibrarySupport。下面展示了CudnnSupport的工厂注册代码。
1 void initialize_cudnn() { 2 port::Status status = 3 PluginRegistry::Instance()->RegisterFactory<PluginRegistry::DnnFactory>( 4 cuda::kCudaPlatformId, cuda::kCuDnnPlugin, "cuDNN", 5 [](internal::StreamExecutorInterface* parent) -> dnn::DnnSupport* { 6 cuda::CUDAExecutor* cuda_executor = 7 dynamic_cast<cuda::CUDAExecutor*>(parent); 8 if (cuda_executor == nullptr) { 9 LOG(ERROR) << "Attempting to initialize an instance of the cuDNN " 10 << "support library with a non-CUDA StreamExecutor"; 11 return nullptr; 12 } 13 14 cuda::CudnnSupport* dnn = new cuda::CudnnSupport(cuda_executor); 15 if (!dnn->Init().ok()) { 16 // Note: Init() will log a more specific error. 17 delete dnn; 18 return nullptr; 19 } 20 return dnn; 21 }); 22 23 if (!status.ok()) { 24 LOG(ERROR) << "Unable to register cuDNN factory: " 25 << status.error_message(); 26 } 27 28 PluginRegistry::Instance()->SetDefaultFactory( 29 cuda::kCudaPlatformId, PluginKind::kDnn, cuda::kCuDnnPlugin); 30 } 31 32 } // namespace stream_executor 33 34 REGISTER_MODULE_INITIALIZER(register_cudnn, 35 { stream_executor::initialize_cudnn(); });
再看总体类图
在StreamExecutor框架中还存在其他模块,比如XLA的支持,比如Event的管理,在逐个梳理StreamExecutor框架的三个层次后再看其余部分就非常清晰明了了,下面的两张图展示了整体类图和一些继承结构。

StreamExecutor的调用栈
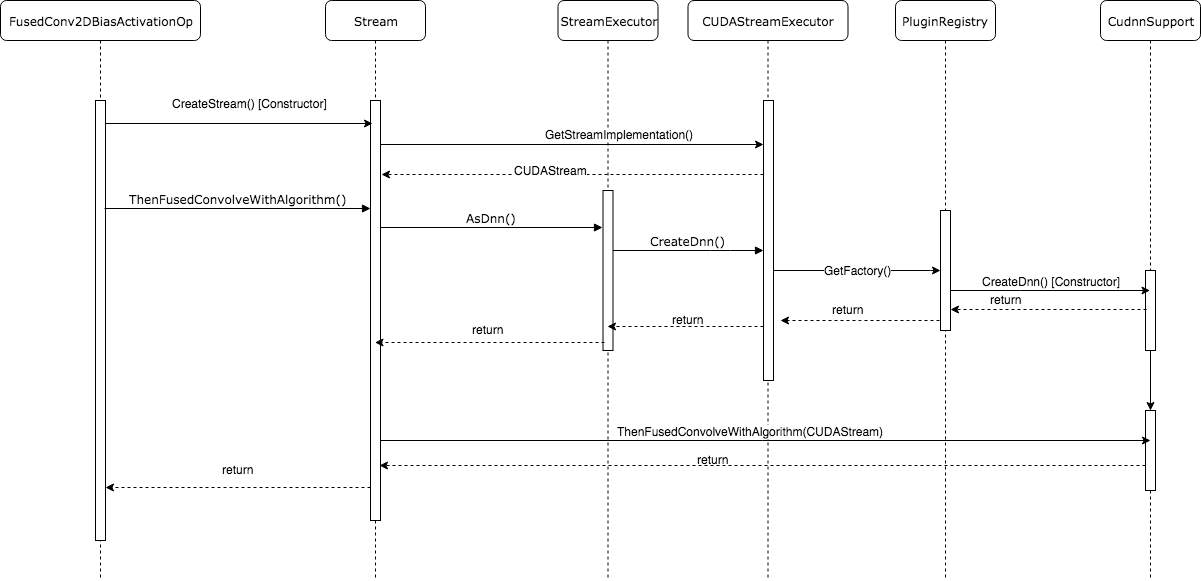
在完整的理解了StreamExecutor框架的内部结构和外部句柄后,我们就可以非常清晰地trace其调用栈了。最后,我们以调用Cudnn中的FusedConvolveWIthAlgorithm为例,画出完整的调用时序图。FusedConvolveWIthAlgorithm是将Convolution计算,Bias计算以及Activation计算fuse在一起的优化版本CUDA kernel,它的效率相对于分开调用相比更高。
总结
StreamExecutor是一个相对独立的项目,在TensorFlow中所使用的StreamExecutor是精简之后的版本。正是因为异构框架管理每种Device的并行执行过程非常繁杂,所以需要StreamExecutor向上层调用者隐藏底层的复杂性。在架构设计上,StreamExecutor选择向上层暴露简单的Stream对象handler实现了这一封装。事实上,TensorFlow中所有需要调用与Device相关的第三方高性能计算库的Op都使用Stream这一handler轻松完成Op的编写。从StreamExecutor框架内部看,可以分为Platform层、StreamExecutor Core层和LibrarySupport层,每层的核心组件都通过Initializer模块和宏定义主动注册到系统Factory中,从上层Op对Stream的调用栈中也可以清晰地感受到这层次分明的架构设计。掌握并理解StreamExecutor的调用栈是非常重要的,因为无论是为TensorFlow底层做XLA优化还是为某些Op提供Int8计算支持,都需要改写这一部分。将来我们在梳理XLA整体框架时还会回过头来窥探StreamExecutor框架中的其他部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号