合集-Cython专辑
摘要: 这篇文章介绍了Python-Cython-C三种语言的简单耦合,以Cython为中间接口,实现Python数据传到C语言的后端执行相关计算。这就相当于可以在Python中调用C语言中的指针功能来进行跨维度的数组运算,至于性能依然存在优化空间,这里仅仅做一个简单的功能演示。
阅读全文
这篇文章介绍了Python-Cython-C三种语言的简单耦合,以Cython为中间接口,实现Python数据传到C语言的后端执行相关计算。这就相当于可以在Python中调用C语言中的指针功能来进行跨维度的数组运算,至于性能依然存在优化空间,这里仅仅做一个简单的功能演示。
阅读全文
这篇文章介绍了Python-Cython-C三种语言的简单耦合,以Cython为中间接口,实现Python数据传到C语言的后端执行相关计算。这就相当于可以在Python中调用C语言中的指针功能来进行跨维度的数组运算,至于性能依然存在优化空间,这里仅仅做一个简单的功能演示。
阅读全文
摘要: 从Python接口调用GPU进行加速的方案有很多,包括Cupy和PyCuda以及之前介绍过的Numba,还可以使用MindSpore、PyTorch和Jax等成熟的深度学习框架,这里介绍了一种直接写CUDA Kernel函数的方案。为了能够做到CUDA-C和Python编程的分离,这里引入了Cython作为中间接口,这样一来Python开发者和C开发者可以去共同开发相应的高性能方法。
阅读全文
从Python接口调用GPU进行加速的方案有很多,包括Cupy和PyCuda以及之前介绍过的Numba,还可以使用MindSpore、PyTorch和Jax等成熟的深度学习框架,这里介绍了一种直接写CUDA Kernel函数的方案。为了能够做到CUDA-C和Python编程的分离,这里引入了Cython作为中间接口,这样一来Python开发者和C开发者可以去共同开发相应的高性能方法。
阅读全文
从Python接口调用GPU进行加速的方案有很多,包括Cupy和PyCuda以及之前介绍过的Numba,还可以使用MindSpore、PyTorch和Jax等成熟的深度学习框架,这里介绍了一种直接写CUDA Kernel函数的方案。为了能够做到CUDA-C和Python编程的分离,这里引入了Cython作为中间接口,这样一来Python开发者和C开发者可以去共同开发相应的高性能方法。
阅读全文
摘要: 本文介绍了一下使用Cython对Python/Numpy实现的函数进行加速的一个简单案例,模型使用的是一个弹性系数全同的谐振势,然后计算总势能。从计算结果来看,使用Cython确实可以获得更接近于C语言的速度,并且编程逻辑还可以大幅的保留Python的语法。
阅读全文
本文介绍了一下使用Cython对Python/Numpy实现的函数进行加速的一个简单案例,模型使用的是一个弹性系数全同的谐振势,然后计算总势能。从计算结果来看,使用Cython确实可以获得更接近于C语言的速度,并且编程逻辑还可以大幅的保留Python的语法。
阅读全文
本文介绍了一下使用Cython对Python/Numpy实现的函数进行加速的一个简单案例,模型使用的是一个弹性系数全同的谐振势,然后计算总势能。从计算结果来看,使用Cython确实可以获得更接近于C语言的速度,并且编程逻辑还可以大幅的保留Python的语法。
阅读全文
摘要: 本文介绍了一个在使用Cython进行Python高性能编程时有可能遇到的一个问题,就是找不到的对应的C语言的头文件,例如numpy中的一些头文件。解决思路就是先在本地找到相应的头文件路径,然后将其添加到编译器的环境变量中即可。
阅读全文
本文介绍了一个在使用Cython进行Python高性能编程时有可能遇到的一个问题,就是找不到的对应的C语言的头文件,例如numpy中的一些头文件。解决思路就是先在本地找到相应的头文件路径,然后将其添加到编译器的环境变量中即可。
阅读全文
本文介绍了一个在使用Cython进行Python高性能编程时有可能遇到的一个问题,就是找不到的对应的C语言的头文件,例如numpy中的一些头文件。解决思路就是先在本地找到相应的头文件路径,然后将其添加到编译器的环境变量中即可。
阅读全文
摘要: 这篇文章介绍了在Cython中定义结构体,并在Python的Numpy数组/MemoryView和自定义结构体之间进行数据转换的方法。Cython有着非常Pythonic的编程范式,又具有接近于C语言的性能,对于Python开发者而言确实是一个很棒的工具。
阅读全文
这篇文章介绍了在Cython中定义结构体,并在Python的Numpy数组/MemoryView和自定义结构体之间进行数据转换的方法。Cython有着非常Pythonic的编程范式,又具有接近于C语言的性能,对于Python开发者而言确实是一个很棒的工具。
阅读全文
这篇文章介绍了在Cython中定义结构体,并在Python的Numpy数组/MemoryView和自定义结构体之间进行数据转换的方法。Cython有着非常Pythonic的编程范式,又具有接近于C语言的性能,对于Python开发者而言确实是一个很棒的工具。
阅读全文
摘要: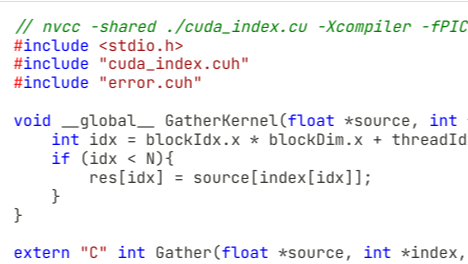 本文使用了Cython作为封装函数,封装一个CUDA C实现的Gather算子,然后通过Python去调用,用这种方法实现一个比较Pythonic的CUDA Gather函数的实现和调用。
阅读全文
本文使用了Cython作为封装函数,封装一个CUDA C实现的Gather算子,然后通过Python去调用,用这种方法实现一个比较Pythonic的CUDA Gather函数的实现和调用。
阅读全文
本文使用了Cython作为封装函数,封装一个CUDA C实现的Gather算子,然后通过Python去调用,用这种方法实现一个比较Pythonic的CUDA Gather函数的实现和调用。
阅读全文
摘要: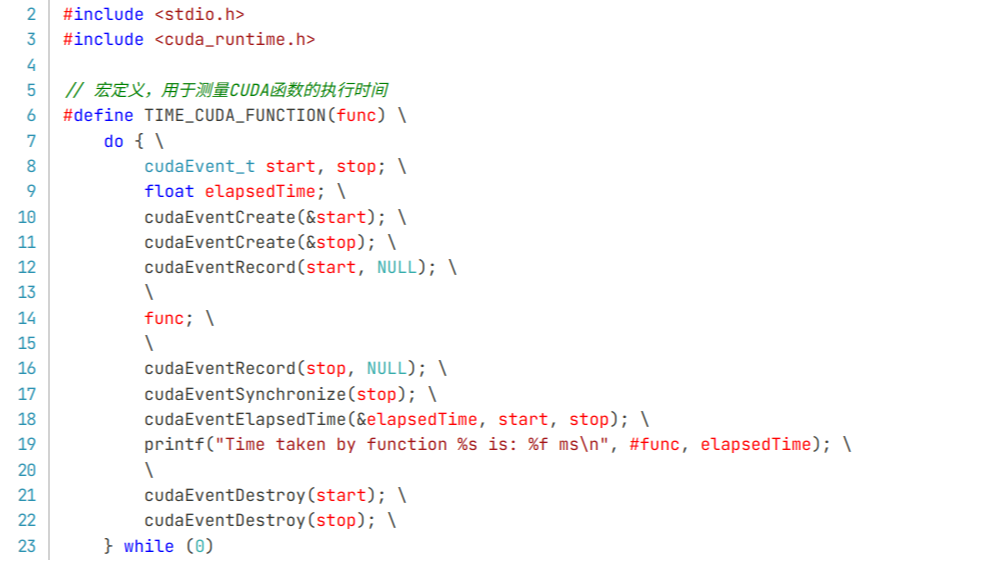 这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。
阅读全文
这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。
阅读全文
这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。
阅读全文
摘要: 以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。
阅读全文
以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。
阅读全文
以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。
阅读全文
摘要: 本文介绍了使用CUDA和Cython来实现一个CUDA加法算子的方法,并介绍了使用CUDA参数来估算性能极限的算法。经过实际测试,核函数部分的算法性能优化空间已经不是很大了,更多时候可以考虑使用Stream来优化Host和Device之间的数据传输。
阅读全文
本文介绍了使用CUDA和Cython来实现一个CUDA加法算子的方法,并介绍了使用CUDA参数来估算性能极限的算法。经过实际测试,核函数部分的算法性能优化空间已经不是很大了,更多时候可以考虑使用Stream来优化Host和Device之间的数据传输。
阅读全文
本文介绍了使用CUDA和Cython来实现一个CUDA加法算子的方法,并介绍了使用CUDA参数来估算性能极限的算法。经过实际测试,核函数部分的算法性能优化空间已经不是很大了,更多时候可以考虑使用Stream来优化Host和Device之间的数据传输。
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号