
新手能看懂的数据库操作(一)
数据库操作(一)

基于MySQL+Navicat进行操作
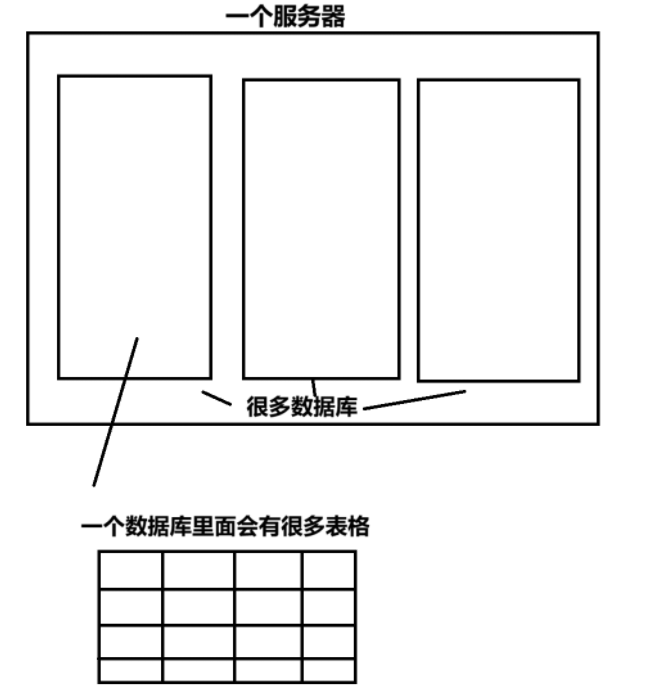
服务器、数据库、表
- 建立一个服务器之后,一个服务器当中会有很多个数据库,每个数据库内部又会有很多表格,所以我们先学习进入数据库,创建删减查看表格等操作。
![在这里插入图片描述]()
数据库相关操作
sql语句大小写没有区别,为了便于阅读统一小写书写
sql语句执行没有前后顺序之分,选中哪一(几)条就执行那一(几)条
1. 查看数据库
运行一个服务器之后,新建一个查询,输入:
show databases;
可以查看当前服务器下所有数据库的列表: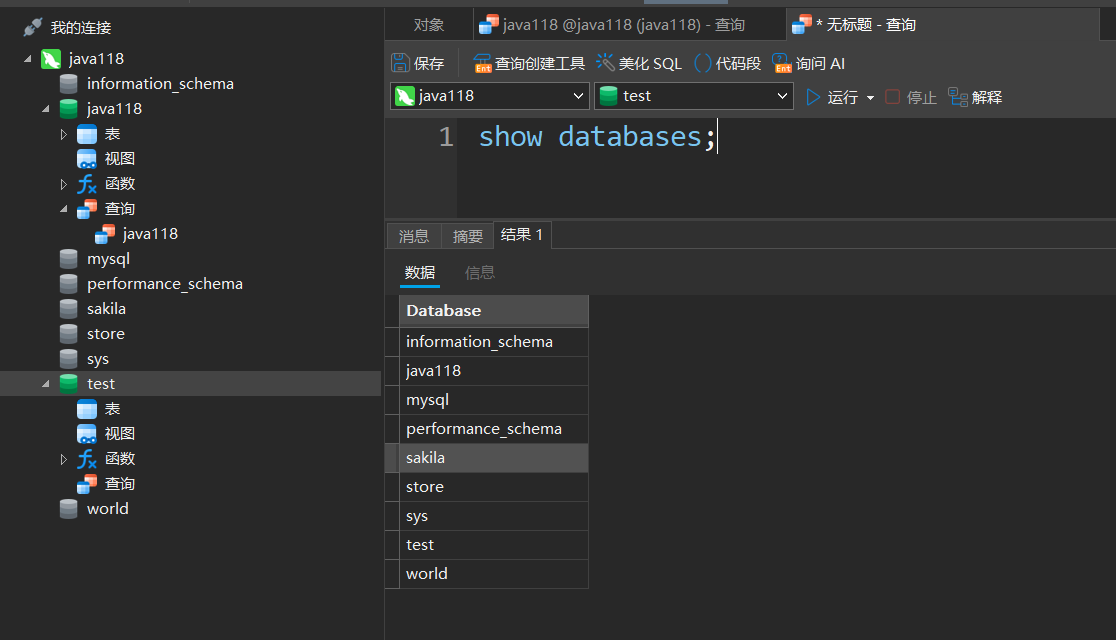
2.新建数据库
create database 数据库名字;
- 数据库名字不能与关键字重复
- 创建数据库用的是‘database’不是复数
![在这里插入图片描述]()
创建后再执行创建语句,会显示报错,所以可以加上判断数据库是否存在的语句:
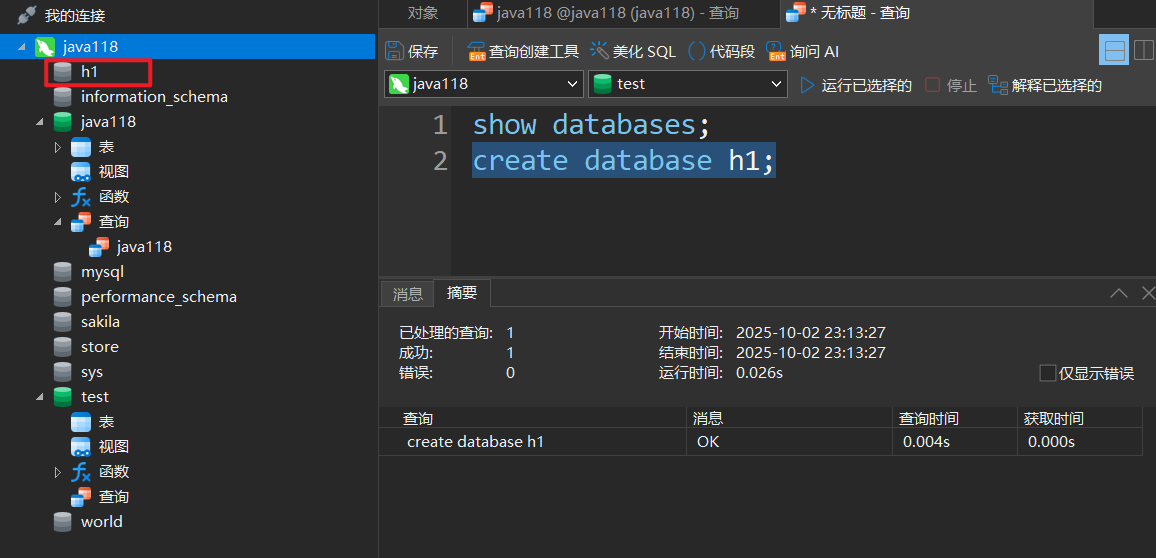
create database 数据库名字 if not exists;
- 但如果数据库里面有汉字的话,可以加上:
create database 数据库名字 charset utf8mb4 if not exists;
- MySQL中的utf8不是一个完整体,只是完整的utf8当中的一些子集,而使用utf8mb4是完整版的utf8(主要是缺少了emoji表情包)
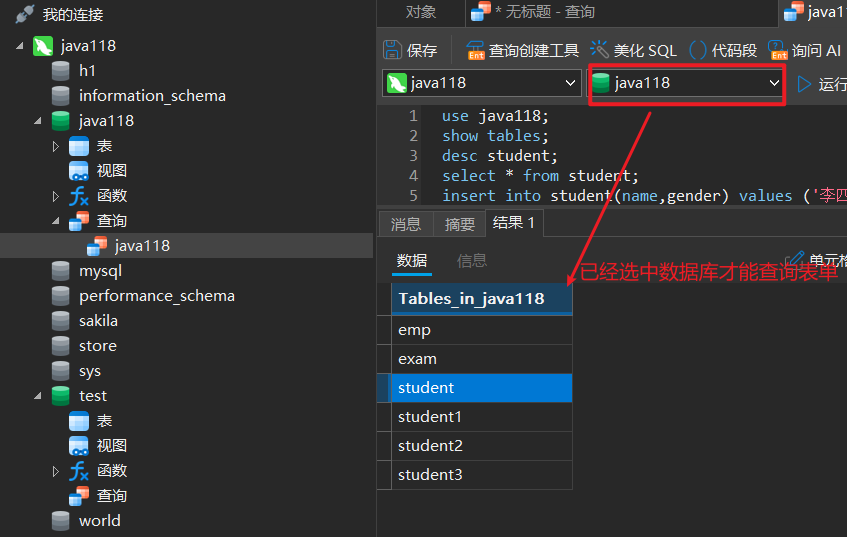
3.选中数据库
use 数据库名字;
- 先选中某个数据库,才能进行操作步骤
4.删除数据库
此为危险操作
drop 数据库名字;
*字符集编码
- 有很多,最常用的就是varchar,在后面创建表单数据的时候会用到
表相关操作
- 表的操作前提是已经使用了use 数据库名字然后才能对表进行操作
1.查看数据库中所有的表
show tables;
2.创建数据表
create table 表名(列名 类型,列名 类型......);
实列:
create table niubi(name varchar(20),age int);
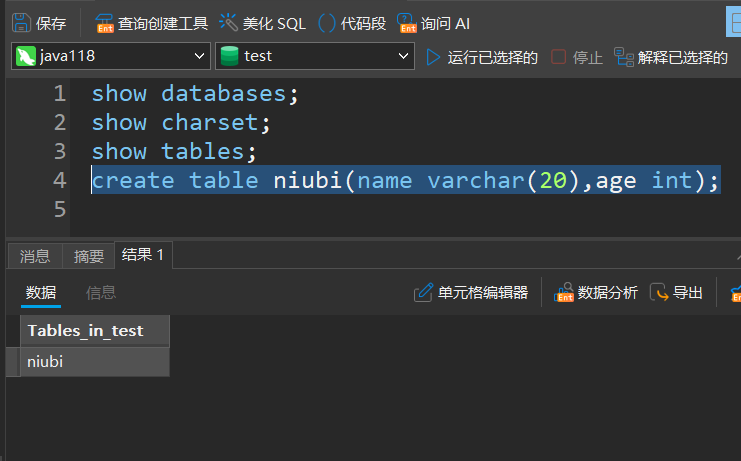
3.查看表结构
desc 表名;
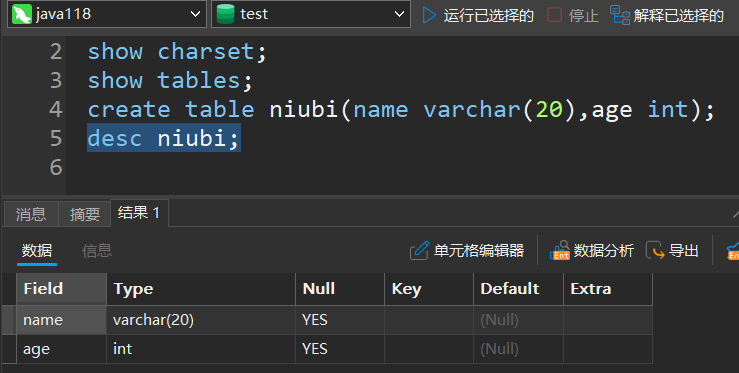
4.修改表
用到较少
alter table 表名动作 列名 类型;
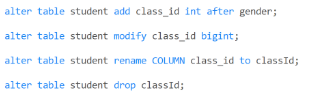
5.删除表
此为危险操作
drop table 表名;
*删除库和删除表
在数据库操作中,删除库(DROP DATABASE) 和删除表(DROP TABLE) 均属于高危不可逆操作,一旦执行且未及时恢复,会造成数据永久性丢失,对业务系统、数据安全和企业运营产生严重影响。以下将详细分析两者的危害,并论证“删除表的危害性更大”的核心逻辑。
一、删除库(DROP DATABASE)的核心危害
删除库操作会彻底删除整个数据库实例(包含库内所有表、视图、存储过程、触发器等所有对象),其危害主要体现在“范围性破坏”上,具体包括:
-
全量数据毁灭性丢失
数据库是业务数据的“容器”,删除库会直接清空该库下所有业务相关的表(如用户表、订单表、交易表)。例如,电商系统的“交易库”被删除后,用户信息、历史订单、支付记录会全部消失,且无法通过库内局部恢复手段挽回。 -
业务系统整体瘫痪
一个数据库通常对应一套或多套核心业务(如“用户中心库”对应登录、注册、个人信息管理模块)。库被删除后,依赖该库的所有业务模块会因“无数据可查/写”直接报错,导致系统完全不可用(如APP无法登录、网页无法加载核心内容)。 -
恢复成本极高且成功率低
恢复删除的库需依赖全量备份+增量日志(如MySQL的binlog、PostgreSQL的WAL日志),但存在两大痛点:- 备份依赖强:若备份策略缺失(如未开启定时全量备份)或备份文件损坏,数据无法恢复;
- 恢复周期长:全量备份通常体积庞大(如几十GB到TB级),恢复过程可能需要数小时甚至数天,期间业务完全中断。
-
合规与法律风险
若数据库包含用户隐私数据(如身份证号、手机号)、金融数据(如银行卡信息),删除库导致的数据丢失可能违反《数据安全法》《个人信息保护法》等法规,企业需承担行政处罚(如罚款),甚至面临用户诉讼。
二、删除表(DROP TABLE)的核心危害
删除表操作会删除数据库内指定的单个或多个表,其危害看似“范围更小”,但实际因“精准破坏业务核心链路”“恢复难度更高”“影响更隐蔽且持久”,危害性远超删除库,具体体现在以下4个维度:
1. 精准打击业务核心链路,影响更“致命”
数据库中不同表的“业务权重”差异极大:部分表是业务的“命脉”(如订单表、支付表),部分表是辅助性数据(如日志表、冗余备份表)。删除表操作可精准定位核心表,且单个核心表的丢失即可瘫痪关键业务,而无需破坏整个库:
- 例1:删除电商系统的“订单表(order)”,用户无法下单、商家无法查看订单、财务无法对账——核心交易链路直接中断,但用户表(user)、商品表(goods)仍存在,系统看似“部分可用”,实则核心业务已停摆;
- 例2:删除银行系统的“账户余额表(account_balance)”,用户无法查询余额、转账功能失效,直接冲击金融业务核心,而删除库会导致所有表丢失,反而能快速定位“全量故障”,避免核心表丢失的“隐蔽性破坏”。
2. 恢复难度更高,数据一致性风险更大
删除表的恢复比删除库更复杂,且易导致数据不一致,主要原因包括:
- 备份粒度不匹配:企业通常以“库”为单位做全量备份(如每天凌晨备份整个“交易库”),若仅删除“订单表”,需从GB/TB级的库备份中“提取单个表”恢复,操作复杂且耗时(如MySQL需通过
mysqlbinlog解析增量日志,定位表删除前的操作,再重建表数据); - 关联数据断裂:数据库表之间普遍存在外键关联(如“订单表”关联“用户表”“商品表”),删除表后,即使恢复该表,也可能因增量日志中“关联表的更新记录”未同步,导致数据不一致(如订单表恢复后,商品表已更新的库存数据未匹配,出现“超卖”);
- 业务中断时间更长:删除库会导致“全业务不可用”,企业会优先启动最高级别的故障响应(如紧急调用所有运维资源恢复);而删除表可能仅导致“局部业务异常”(如仅下单功能失效,其他功能正常),易被延误处理,导致业务中断时间更长(如从发现问题到恢复可能耗时数小时,远超删除库的恢复时间)。
3. 故障定位更困难,扩大业务损失
删除库的故障表现是“全量数据不可用”,运维人员可瞬间定位“库被删除”,并立即启动恢复流程;而删除表的故障表现具有“隐蔽性”:
- 若删除的是“非核心辅助表”(如用户行为日志表),可能数天甚至数周后才被发现(如统计报表异常时才察觉),此时增量日志已被覆盖(如默认保留7天的binlog),数据完全无法恢复;
- 若删除的是“核心表的关联表”(如“订单明细表”),初期可能仅表现为“订单详情页加载失败”,运维人员可能误判为“前端bug”或“接口异常”,反复排查后才发现是表被删除,延误恢复时机,导致用户因“功能异常”流失(如用户多次尝试查看订单详情失败后,选择放弃使用平台)。
4. 对业务连续性的长期影响更深远
删除库的影响是“一次性全量破坏”,恢复后业务可整体重启,且数据一致性有保障(全量备份+完整增量日志可恢复到删除前的状态);而删除表的影响可能“长期持续”:
- 若核心表无法完全恢复(如部分增量日志丢失),需人工补录数据(如从业务日志、第三方系统导出数据),补录过程中易出现人为错误(如数据录入偏差),导致后续业务出现“数据脏读”“统计错误”(如财务对账不平、用户积分计算错误);
- 部分表删除后,即使恢复,也可能因“表结构变更”(如删除前表已新增字段),导致与现有业务代码不兼容(如APP端调用新增字段时报错),需同步修改代码,进一步延长业务恢复周期。
三、核心结论:为何删除表的危害性更大?
删除库与删除表的危害本质都是“数据丢失”,但从业务影响精准度、恢复难度、故障定位效率、长期影响四个维度对比,删除表的危害性更突出,核心逻辑可总结为:
| 对比维度 | 删除库(DROP DATABASE) | 删除表(DROP TABLE) | 结论(危害性更高) |
|---|---|---|---|
| 业务影响范围 | 全量业务不可用(范围大但明确) | 精准打击核心业务(范围小但致命) | 删除表 |
| 恢复难度 | 依赖库全量备份+增量日志,步骤清晰 | 需从库备份中提取单表,关联数据易断裂 | 删除表 |
| 故障定位效率 | 全量不可用,瞬间定位 | 局部异常,易延误排查 | 删除表 |
| 长期业务影响 | 恢复后数据一致性有保障 | 易出现数据补录错误、代码兼容问题 | 删除表 |
简言之:删除库是“一次性毁灭”,可快速响应并控制损失;删除表是“精准打击+隐蔽破坏”,恢复难、定位慢、影响久,对业务的伤害更深远。
四、如何规避删除操作的风险?
无论删除库还是删除表,核心防范措施均围绕“权限管控”“操作审计”“备份恢复”三大维度:
- 严格权限管控:禁用普通账号的
DROP权限,仅给核心运维人员分配“临时授权”(如通过堡垒机申请,操作后立即回收); - 操作前强制校验:执行
DROP操作前,必须触发“二次确认”(如输入库/表名全称+验证码),并检查是否有近期备份; - 完善备份策略:采用“全量备份+增量备份+异地备份”(如每天全量、每小时增量,备份文件同步至异地机房),确保数据可恢复;
- 开启操作审计:记录所有
DROP操作的账号、时间、IP(如通过MySQL的general log、阿里云RDS的操作日志),便于故障追溯。
增删改查(CRUD)
1.新增
insert into 表名 values(参数一,参数二,参数三......);
- 注意:SQL为弱类型语言,即使values后面写的值和建表时对应的类型匹配不上,但是MySQL还是会进行转换,如果转化成果,就插入,如果转换失败,就会报错
- 例子:
INSERT INTO exam (id,name, chinese, math, english) VALUES
(1, '唐三藏', 67, 98, 56),
(2, '孙悟空', 87, 78, 77),
(3, '猪悟能', 88, 98, 90),
(4, '曹孟德', 82, 84, 67),
(5, '刘玄德', 55, 85, 45),
(6, '孙权', 70, 73, 78),
(7, '宋公明', 75, 65, 30);
指定列新增
insert into 表名(列名,列名......) values(参数一,参数二......),(一次可以插入行);
2.查询
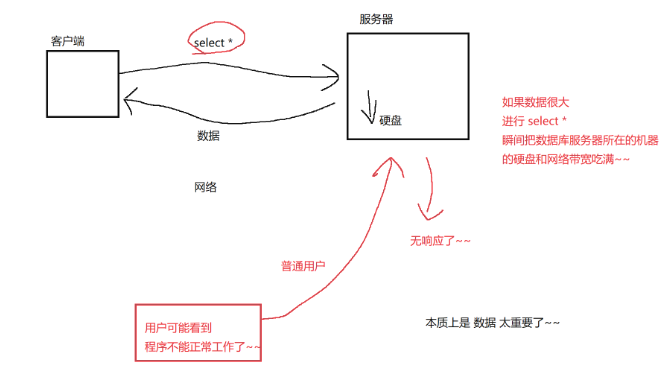
全列查询
select * from 表名
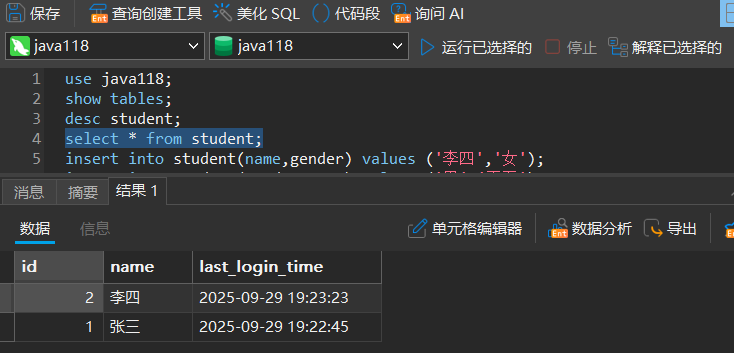
- 数据量大的时候,不建议全列查询,因为涉及到大量的硬盘访问和网络访问。
![在这里插入图片描述]()
指定列查询
select 列名,列名... from 表名;
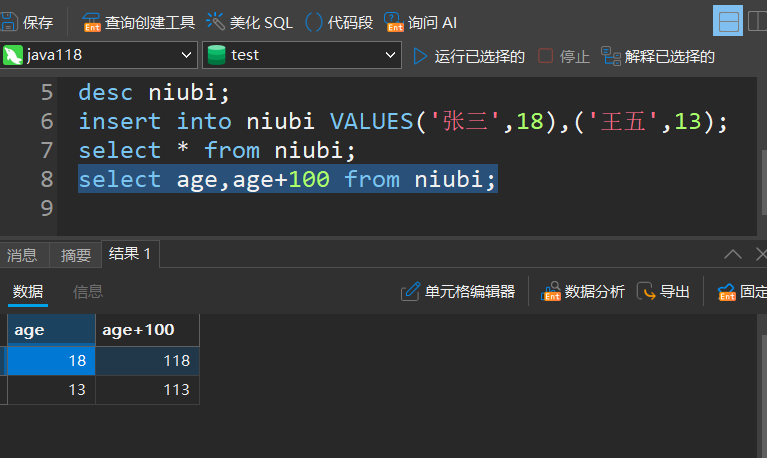
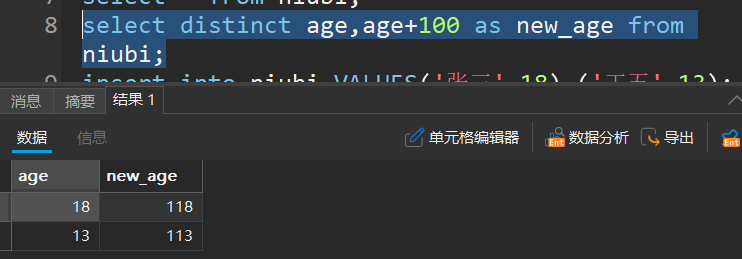
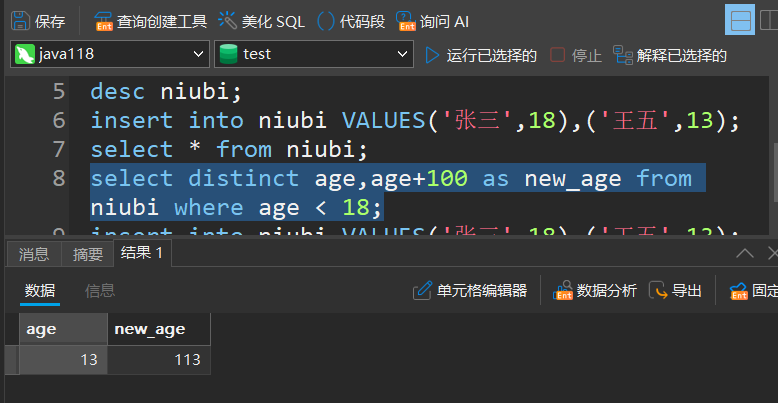
- 可以建立新的查询如上面的age+100,此操作不会改变原列表当中的值
查询带有别名
select 表达式 as 别名 from 表名;
比如给上面例子中的age+100加上别名: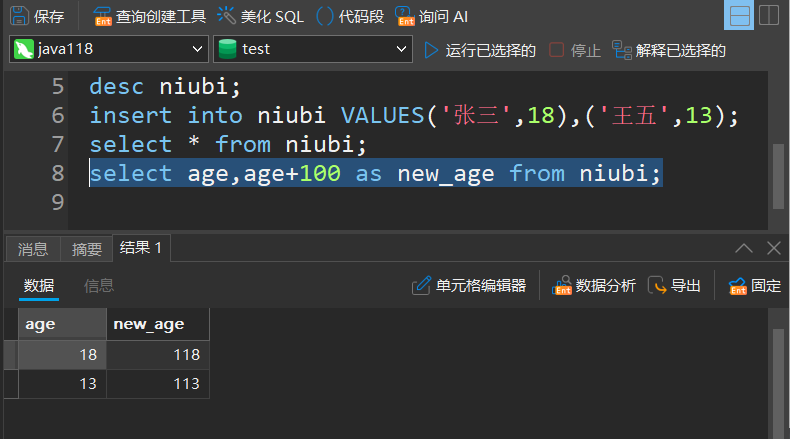
查询结果去重
如果查询出来有重复的,比如: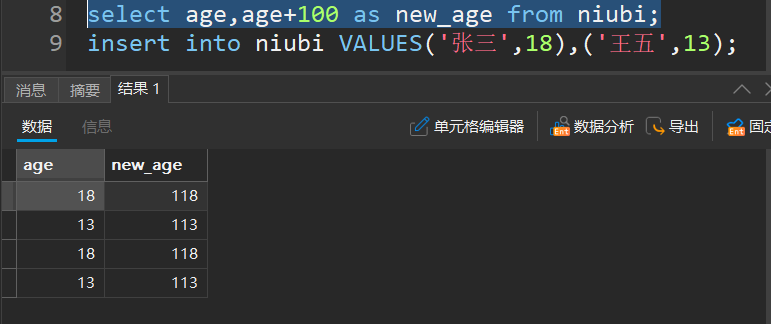
可以使用:
select distinct 列名 from 表名;
条件查询
select 列名 from 表名 where 条件;
| 类别 | 运算符/语法 | 说明 | 示例 |
|---|---|---|---|
| 比较运算符 | = |
等于 | select * from users where age = 18; |
!= 或 <> |
不等于 | select * from products where price != 0; |
|
> |
大于 | select * from orders where total > 1000; |
|
< |
小于 | select * from orders where total < 100; |
|
>= |
大于等于 | select * from students where score >= 60; |
|
<= |
小于等于 | select * from students where score <= 59; |
|
| 范围运算符 | between ... and ... |
在指定范围内(包含边界) | select * from orders where create_time between '2023-01-01' and '2023-12-31'; |
in (值1, 值2, ...) |
匹配列表中的任意值 | select * from users where city in ('北京', '上海'); |
|
not in (值1, 值2, ...) |
不匹配列表中的任何值 | select * from products where category not in ('零食', '饮料'); |
|
| 模糊匹配运算符 | like |
结合通配符进行模糊查询(% 匹配任意字符,_ 匹配单个字符) |
select * from users where name like '张%';(姓张的用户) |
not like |
不匹配模糊条件 | select * from articles where title not like '%测试%'; |
|
| 逻辑运算符 | and |
同时满足多个条件 | select * from products where price > 100 and stock > 0; |
or |
满足任意一个条件 | select * from orders where status = '已支付' or status = '已发货'; |
|
not |
对条件取反 | select * from users where not age > 30;(年龄不大于30) |
|
| 空值运算符 | is null |
判断字段值为 null(注意:null 不等于空字符串) |
select * from users where email is null;(未填写邮箱的用户) |
is not null |
判断字段值不为 null |
select * from orders where address is not null;(填写了地址的订单) |
|
| 特殊运算符 | exists |
子查询返回结果时满足条件 | select * from users u where exists (select 1 from orders o where o.user_id = u.id);(有订单的用户) |
not exists |
子查询无结果时满足条件 | select * from products p where not exists (select 1 from orders o where o.product_id = p.id);(无订单的商品) |
|
any/some/all |
与子查询结合,判断是否满足部分或全部条件(any/some 等价) |
select * from products where price > any (select price from products where category = '促销');(价格高于任意促销商品) |
模糊查询
下面给出是模糊查询(like 运算符)的几个常见例子,结合 % 和 _ 通配符使用,适用于不同场景:
-
查询以特定字符开头的数据
-- 查询姓张的用户(姓名以"张"开头,后面可跟任意字符) select * from users where name like '张%'; -
查询以特定字符结尾的数据
-- 查询邮箱以"@gmail.com"结尾的用户 select * from users where email like '%@gmail.com'; -
查询包含特定字符的数据
-- 查询地址中包含"科技园"的订单 select * from orders where address like '%科技园%'; -
查询特定长度且符合格式的数据
-- 查询11位手机号中,前3位是138,后4位是5678的号码(中间4位任意) select * from users where phone like '138____5678'; -
查询排除特定字符的数据(
not like)-- 查询标题中不含"测试"的文章 select * from articles where title not like '%测试%'; -
查询特定位置匹配的数据
-- 查询第二个字符是"明"的姓名(如"李明"、"王明"等) select * from users where name like '_明%'; -
处理包含通配符本身的数据
若需查询包含%或_的内容,需用转义符(如\,不同数据库可能不同):-- 查询商品名称中包含"50%"的商品(假设用\作为转义符) select * from products where name like '%50\%%' escape '\';
这些例子覆盖了模糊查询的常见场景,% 用于匹配任意长度字符(包括0个),_ 用于匹配单个字符,可根据实际需求组合使用。
NULL查询
以下是针对 NULL 值查询的常见例子,注意 NULL 表示“未知”或“不存在”,不能用普通的 = 或 != 判断,必须使用 is null 或 is not null:
-
查询字段值为 NULL 的数据
-- 查询未填写邮箱的用户(email 字段为 NULL) select * from users where email is null; -
查询字段值不为 NULL 的数据
-- 查询填写了收货地址的订单(address 字段不为 NULL) select * from orders where address is not null; -
结合逻辑运算符查询
-- 查询年龄大于 18 且未设置头像的用户(avatar 字段为 NULL) select * from users where age > 18 and avatar is null; -
排除 NULL 值后的数据统计
-- 统计有手机号的用户数量(排除 phone 为 NULL 的记录) select count(*) as 有效用户数 from users where phone is not null; -
与其他条件组合查询
-- 查询状态为“待付款”且备注信息为 NULL 的订单 select * from orders where status = '待付款' and remark is null;
注意:NULL 与空字符串('')不同,is null 不会匹配空字符串。例如,若某条记录的 email 字段是空字符串(''),则 where email is null 不会查询到该记录,需用 where email = '' 单独判断。
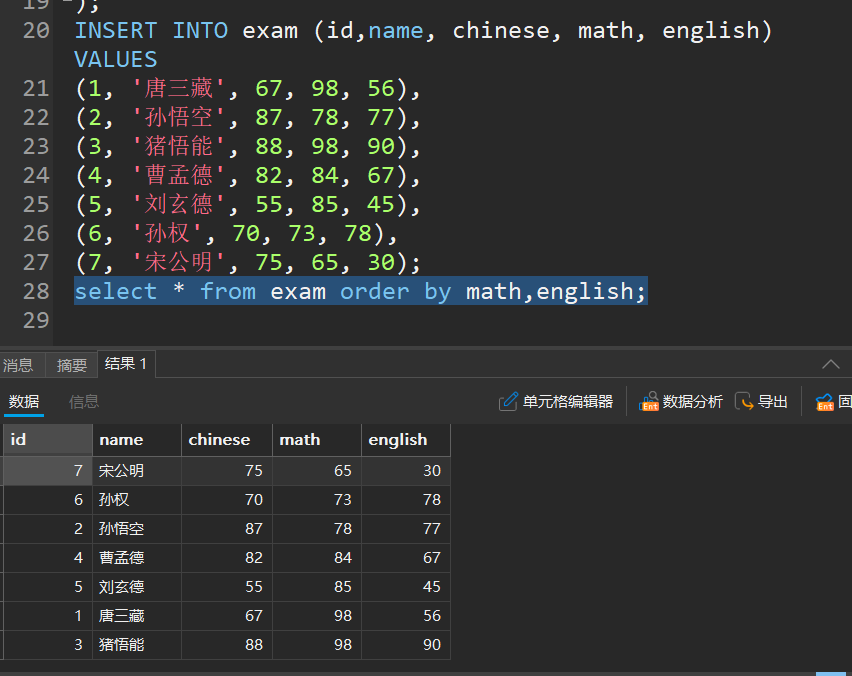
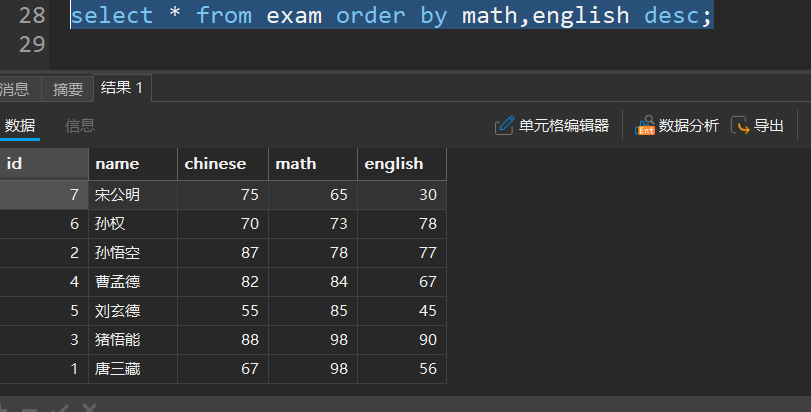
排序查询
select * from 表名 order by 列名,列名;
- 默认是升序排序
- order by 后面的列名,放到前面的优先级更高
- 可以在最后面加上desc表示降序排序,这里与前面的 desc+表名来查看表结构的desc不一样,此处为descending的缩写,前面为describe缩写
![在这里插入图片描述]()
![在这里插入图片描述]()
分页查询
MySQL的分页查询,可以实现网页上的“分页效果”
-- 查询第1页数据,每页显示10条(获取前10条记录)
select * from products limit 0, 10;
-- 查询第2页数据,每页显示10条(跳过前10条,获取接下来的10条)
select * from products limit 10, 10;
-- 按价格降序排序后,查询第3页数据,每页显示20条
select * from products order by price desc limit 40, 20;
3.修改
update 表名 set 列名 = 值 where 条件 order by 列名 limit N;
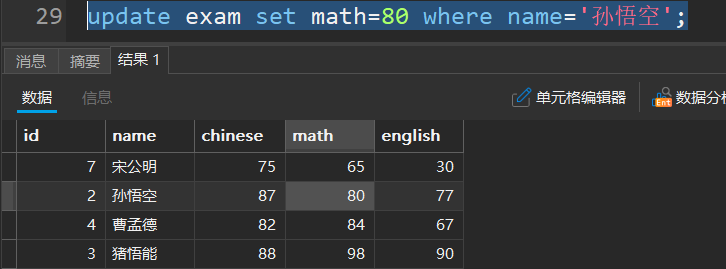
- update操作条件一定要设置好,不然就会把所有表中的列全部修改,也是一个危险操作
以下是数据库中修改数据(UPDATE)的常见例子,涵盖单表修改、多条件修改、批量修改等场景:
-
基本的单条件修改
-- 将id为100的用户状态改为"禁用" update users set status = '禁用' where id = 100; -
修改多个字段
-- 更新id为20的商品信息:价格调整为99.9,库存减10 update products set price = 99.9, stock = stock - 10 where id = 20; -
多条件组合修改
-- 对2023年之前注册且未认证的用户,发送提醒标记设为"需要提醒" update users set remind_flag = '需要提醒' where register_time < '2023-01-01' and is_verified = 0; -
根据子查询结果修改
-- 将所有"过期商品"的状态改为"下架"(子查询获取过期商品id) update products set status = '下架' where id in ( select id from products where expire_time < curdate() ); -
使用表达式修改
-- 对所有会员用户的积分增加100(原积分基础上累加) update users set points = points + 100 where user_type = '会员'; -
带限制条件的批量修改
-- 最多修改10条"待审核"状态的评论,将其改为"已审核" update comments set audit_status = '已审核' where audit_status = '待审核' limit 10; -- 部分数据库支持(如MySQL) -
修改为NULL值
-- 清除id为5的用户的邮箱信息(设为NULL) update users set email = null where id = 5;
注意:
- 修改操作务必加
WHERE条件,否则会更新表中所有记录,造成数据灾难 - 执行前建议先用
SELECT语句验证条件是否正确(如select * from users where id = 100;) - 重要修改操作建议先备份数据,或在事务中执行(可回滚)
4.删除
delete from 表名 where 条件 order by 列名 limit N;
以下是数据库中删除数据的常见操作示例,包括删除单条记录、批量删除、按条件删除等场景,操作时需特别谨慎:
-
删除单条记录(精确条件)
-- 删除id为5的用户记录 delete from users where id = 5; -
按条件批量删除
-- 删除2022年之前创建的过期订单 delete from orders where create_time < '2022-01-01' and status = '已过期'; -
删除符合子查询结果的记录
-- 删除没有任何订单的用户(关联子查询) delete from users where not exists ( select 1 from orders where orders.user_id = users.id ); -
删除所有记录(清空表)
-- 清空商品表所有数据(保留表结构) delete from products;(注:
TRUNCATE TABLE products;也可清空表,但属于DDL操作,不可回滚,速度更快) -
带限制的删除(部分数据库支持)
-- 删除最多10条状态为"垃圾"的评论 delete from comments where type = '垃圾' limit 10; -- MySQL等支持,SQL Server可用top,Oracle可用rownum -
按关联条件删除
-- 删除属于"已关闭"分类下的所有文章 delete from articles where category_id in ( select id from categories where status = '已关闭' );
极度危险警告:
- 执行
delete时若忘记加where条件,会删除表中所有数据,且大部分数据库中此操作不可直接撤销 drop table(删表)和drop database(删库)属于更危险的操作,会直接删除表/库结构及所有数据- 重要操作前必须备份数据,建议在事务中执行(
begin; ... delete; ... commit;),确认无误后再提交
插入查询
把查询的结果,插入到另一个表里
insert into 表名1 select 列名 from 表名2;
聚合函数
- 统计表中有多少记录
select count(*) from 表名;
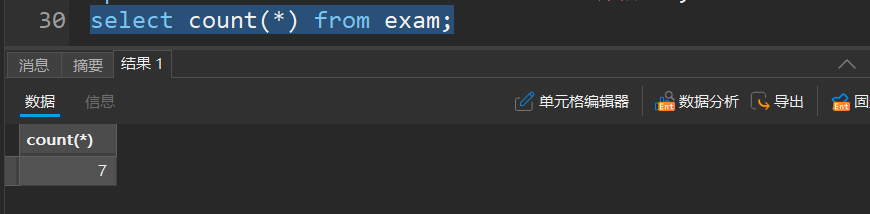
- count()括号内只能写一个参数,多了会报错
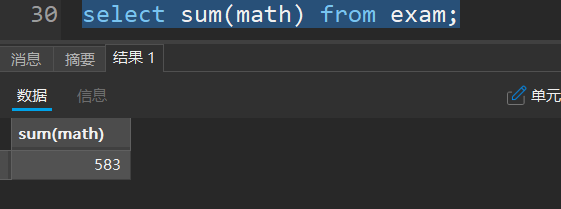
- 统计综合
例:统计所有学生中数学的总分
![在这里插入图片描述]()
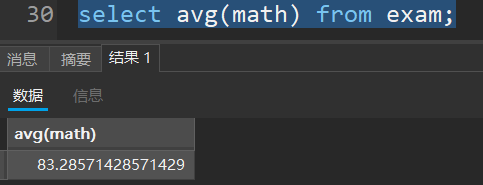
- 平均数
例:统计所有学生中数学的平均数:
![在这里插入图片描述]()
Group by 分组查询
select 表达式 from 表名 group by 列名;
例:按照职位划分
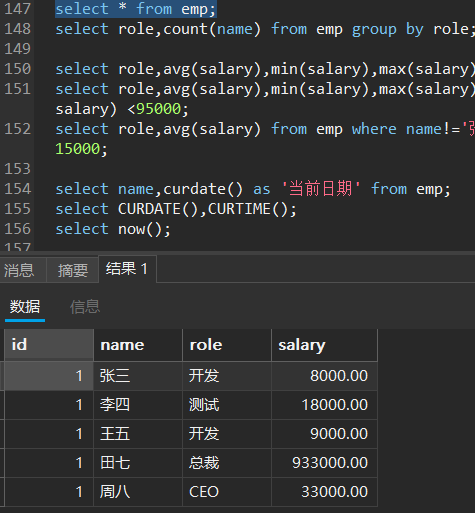
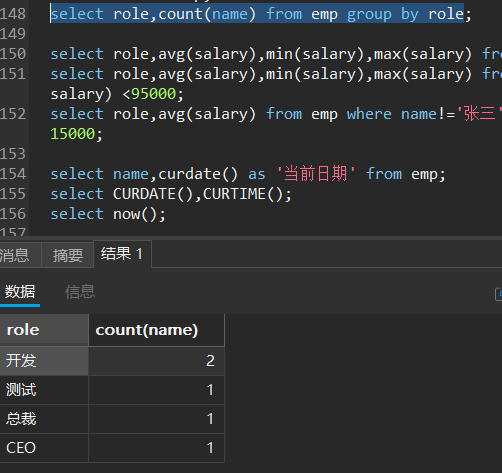
分组之后的查询方式——having
例:统计每个岗位的平均薪资后,保留平均薪资小于95000的:
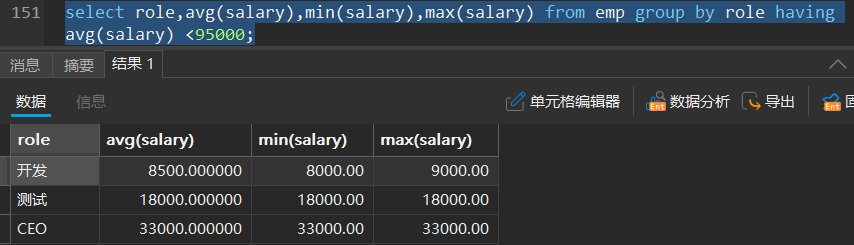
内置函数
- 内置函数与聚合函数:聚合函数只是内置函数的一部分
- 数据库中的内置函数用于处理数据、执行计算或格式化结果,以下是常见的几类内置函数及示例(基于SQL标准,不同数据库可能略有差异):
一、字符串函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
length(str) |
返回字符串长度 | length('hello') |
5 |
concat(str1, str2) |
拼接字符串 | concat('user', '123') |
‘user123’ |
upper(str) |
转为大写 | upper('Hello') |
‘HELLO’ |
lower(str) |
转为小写 | lower('HELLO') |
‘hello’ |
substr(str, start, len) |
截取子串(start从1开始) | substr('abcdef', 2, 3) |
‘bcd’ |
trim(str) |
去除首尾空格 | trim(' test ') |
‘test’ |
二、数值函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
abs(num) |
取绝对值 | abs(-10) |
10 |
round(num, n) |
四舍五入(n为小数位数) | round(3.1415, 2) |
3.14 |
ceil(num) |
向上取整 | ceil(2.1) |
3 |
floor(num) |
向下取整 | floor(2.9) |
2 |
mod(num1, num2) |
取余数 | mod(10, 3) |
1 |
pow(num, n) |
计算num的n次方 | pow(2, 3) |
8 |
三、日期时间函数
| 函数 | 说明 | 示例 | 结果(示例) |
|---|---|---|---|
now() |
返回当前日期时间 | now() |
‘2023-10-05 14:30:00’ |
curdate() |
返回当前日期 | curdate() |
‘2023-10-05’ |
curtime() |
返回当前时间 | curtime() |
‘14:30:00’ |
datediff(date1, date2) |
计算两个日期差值(天数) | datediff('2023-10-05', '2023-10-01') |
4 |
date_add(date, interval n unit) |
日期加n个单位(如天、月) | date_add('2023-10-05', interval 3 day) |
‘2023-10-08’ |
year(date) |
提取年份 | year('2023-10-05') |
2023 |
四、聚合函数(常用于GROUP BY)
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
count(col) |
统计非NULL值的数量 | select count(id) from users |
总用户数 |
sum(col) |
计算总和 | select sum(price) from orders |
订单总金额 |
avg(col) |
计算平均值 | select avg(score) from students |
平均分数 |
max(col) |
取最大值 | select max(create_time) from logs |
最新日志时间 |
min(col) |
取最小值 | select min(age) from users |
最小年龄 |
五、其他常用函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
if(cond, a, b) |
条件判断(cond为真返回a,否则b) | if(10>5, 'yes', 'no') |
‘yes’ |
case when cond then a else b end |
多条件判断 | case when score>=60 then '及格' else '不及格' end |
‘及格’或’不及格’ |
coalesce(expr1, expr2...) |
返回第一个非NULL值 | coalesce(null, 'default') |
‘default’ |
cast(expr as type) |
数据类型转换 | cast('2023-10-05' as date) |
日期类型’2023-10-05’ |
| 以下是数据库内置函数的实际用法示例,涵盖字符串处理、数值计算、日期操作和聚合分析等场景: |
1. 字符串函数示例
-- 1. 拼接用户姓名和ID(如"张三(1001)")
select concat(name, '(', id, ')') as user_info from users;
-- 2. 将邮箱统一转为小写并截取@前的用户名
select lower(email), substr(email, 1, instr(email, '@')-1) as username from users;
-- 3. 计算用户名长度,筛选长度大于3的用户
select name from users where length(name) > 3;
-- 4. 去除地址两端空格后,查询包含"北京市"的记录
select * from addresses where trim(address) like '%北京市%';
2. 数值函数示例
-- 1. 计算商品价格的平均值并四舍五入保留2位小数
select round(avg(price), 2) as avg_price from products;
-- 2. 计算订单金额(数量×单价)并向上取整
select order_id, ceil(quantity * price) as total from order_details;
-- 3. 统计库存为偶数的商品(取模运算)
select * from products where mod(stock, 2) = 0;
-- 4. 计算折扣后价格(原价×0.85)并向下取整
select product_name, floor(price * 0.85) as discount_price from products;
3. 日期时间函数示例
-- 1. 查询今天注册的用户
select * from users where date(register_time) = curdate();
-- 2. 计算订单距今的天数(判断是否超过30天未支付)
select order_id, datediff(curdate(), create_time) as days from orders where status = '未支付' and datediff(curdate(), create_time) > 30;
-- 3. 给用户的会员有效期增加30天
update users set vip_expire = date_add(vip_expire, interval 30 day) where user_type = '会员';
-- 4. 按年份统计订单数量
select year(create_time) as order_year, count(*) as total from orders group by year(create_time);
4. 聚合函数与分组示例
-- 1. 按商品分类统计总销量、平均价格和最高单价
select
category,
sum(sales) as total_sales,
avg(price) as avg_price,
max(price) as max_price
from products
group by category;
-- 2. 统计每个用户的订单总数,只显示订单数≥5的用户
select
user_id,
count(order_id) as order_count
from orders
group by user_id
having order_count >= 5;
-- 3. 计算所有商品的库存总和,排除库存为NULL的记录
select sum(stock) as total_stock from products where stock is not null;
5. 条件与转换函数示例
-- 1. 根据分数判断等级(case when用法)
select
student_id,
score,
case
when score >= 90 then '优秀'
when score >= 60 then '及格'
else '不及格'
end as level
from students;
-- 2. 优先显示用户的手机号,若无则显示邮箱(coalesce用法)
select name, coalesce(phone, email) as contact from users;
-- 3. 判断商品是否售罄(if函数用法)
select
product_name,
if(stock > 0, '有货', '售罄') as stock_status
from products;
-- 4. 将订单金额从字符串类型转为数值型并计算总和
select sum(cast(amount_str as decimal(10,2))) as total from order_logs;
数据库的约束
数据库约束用于保证数据的完整性、一致性和有效性,以下是主键约束、外键约束、唯一约束、非空约束、检查约束这5类常见约束的具体例子,基于SQL标准语法(不同数据库细节略有差异):
1. 主键约束(PRIMARY KEY)
作用:唯一标识表中的每条记录,确保字段值非空且唯一(一张表只能有1个主键,可由多个字段组成联合主键)。
例子1:单字段主键(创建表时添加)
-- 创建用户表,以id作为主键(自增,确保唯一标识)
create table users (
id int auto_increment, -- auto_increment(MySQL)/ identity(SQL Server)实现自增
name varchar(50) not null,
phone varchar(20),
primary key (id) -- 主键约束:id非空且唯一
);
例子2:联合主键(多字段组合唯一)
-- 创建学生选课表,学生id+课程id组成联合主键(确保同一学生不会重复选同一课程)
create table student_course (
student_id int not null,
course_id int not null,
score int,
-- 联合主键:student_id和course_id组合唯一
primary key (student_id, course_id)
);
2. 外键约束(FOREIGN KEY)
作用:建立两张表的关联关系,确保从表(子表)的字段值必须在主表(父表)的关联字段中存在,避免数据孤立或无效关联。
例子:订单表关联用户表(确保订单归属的用户存在)
-- 1. 先创建主表(用户表,已存在主键id)
create table users (
id int auto_increment primary key,
name varchar(50) not null
);
-- 2. 创建从表(订单表),添加外键关联用户表的id
create table orders (
order_id int auto_increment primary key,
user_id int not null, -- 关联用户表的id
total decimal(10,2) not null,
-- 外键约束:user_id的值必须在users表的id中存在
foreign key (user_id) references users(id)
-- 可选:删除/更新主表记录时的处理规则
on delete restrict -- 若主表用户被删除,且有订单关联,则禁止删除(避免订单无归属)
on update cascade -- 若主表用户id更新,订单表的user_id同步更新
);
3. 唯一约束(UNIQUE)
作用:确保字段值在表中唯一(允许为空,但空值只能出现1次),常用于手机号、邮箱等需唯一标识的字段(区别于主键:一张表可多个唯一约束,且字段可空)。
例子:用户表的手机号和邮箱唯一
create table users (
id int auto_increment primary key,
name varchar(50) not null,
phone varchar(20) unique, -- 唯一约束:手机号不可重复(允许为空)
email varchar(50) unique, -- 唯一约束:邮箱不可重复(允许为空)
-- 若需“手机号或邮箱”组合唯一,可创建联合唯一约束
unique key uk_phone_email (phone, email)
);
4. 非空约束(NOT NULL)
作用:确保字段值不能为空(必须填写),常用于必填字段(如姓名、订单金额)。
例子:订单表的必填字段
create table orders (
order_id int auto_increment primary key,
user_id int not null, -- 非空:订单必须归属用户
order_time datetime not null, -- 非空:必须记录下单时间
total decimal(10,2) not null, -- 非空:订单金额不可为空
address varchar(200) not null -- 非空:收货地址必须填写
);
5. 检查约束(CHECK)
作用:限制字段值的取值范围或满足特定条件(如数值范围、格式规则),确保数据符合业务逻辑(部分数据库如MySQL 8.0+、PostgreSQL、Oracle支持)。
例子1:限制年龄范围(1-150岁)
create table users (
id int auto_increment primary key,
name varchar(50) not null,
age int,
-- 检查约束:age必须在1-150之间(否则插入/更新失败)
check (age between 1 and 150)
);
例子2:限制订单状态只能是指定值
create table orders (
order_id int auto_increment primary key,
status varchar(20) not null,
-- 检查约束:status只能是“待支付”“已支付”“已取消”中的一个
check (status in ('待支付', '已支付', '已取消'))
);
约束的常见操作补充
- 添加约束(表已创建时):
-- 给users表的phone字段添加唯一约束 alter table users add unique (phone); -- 给orders表添加外键约束(关联users表id) alter table orders add foreign key (user_id) references users(id); - 删除约束(表已创建时):
-- 删除users表的phone字段唯一约束(需指定约束名,可通过show keys from users查看) alter table users drop index uk_phone; -- 删除orders表的外键约束(需指定约束名) alter table orders drop foreign key fk_orders_user;
自增主键
自增主键(Auto-Increment Primary Key)用于自动为每条新插入的记录生成唯一ID,避免手动维护主键的繁琐和重复风险。不同数据库的自增语法存在差异,以下是主流数据库的自增主键例子:
1. MySQL 自增主键(AUTO_INCREMENT)
MySQL 使用 AUTO_INCREMENT 关键字实现自增,需配合整数类型(如 int bigint),且自增字段必须是主键或唯一键。
例子1:创建表时指定自增主键
-- 创建用户表,id 为 int 类型自增主键(默认从1开始,每次+1)
create table users (
id int auto_increment, -- 自增字段
name varchar(50) not null,
phone varchar(20) unique,
primary key (id) -- 自增字段必须设为主键
);
-- 插入数据时无需指定 id(会自动生成)
insert into users (name, phone) values ('张三', '13800138000');
insert into users (name, phone) values ('李四', '13900139000');
-- 结果:两条记录的 id 分别为 1、2
例子2:自定义自增起始值(默认从1开始)
-- 创建订单表,id 从 10001 开始自增(适合需要“非1开头主键”的场景,如订单号)
create table orders (
order_id int auto_increment,
user_id int not null,
total decimal(10,2) not null,
primary key (order_id)
) auto_increment = 10001; -- 指定自增起始值
-- 插入第一条数据,order_id 自动为 10001
insert into orders (user_id, total) values (1, 99.9);
2. SQL Server 自增主键(IDENTITY)
SQL Server 使用 IDENTITY(种子, 增量) 实现自增,“种子”是起始值,“增量”是每次增加的数值(默认均为1)。
例子1:默认自增(从1开始,每次+1)
-- 创建商品表,product_id 为自增主键(IDENTITY(1,1) 可简写为 IDENTITY)
create table products (
product_id int identity(1,1) primary key, -- 自增主键(种子1,增量1)
product_name varchar(100) not null,
price decimal(10,2) not null,
stock int default 0
);
-- 插入数据无需指定 product_id
insert into products (product_name, price) values ('手机', 2999.00);
insert into products (product_name, price) values ('耳机', 199.00);
-- 结果:product_id 分别为 1、2
例子2:自定义种子和增量(从500开始,每次+2)
-- 创建日志表,log_id 从 500 开始,每次增加 2(适合特殊编号规则)
create table logs (
log_id int identity(500, 2) primary key, -- 种子500,增量2
log_time datetime default getdate(),
content varchar(500) not null
);
-- 插入两条数据,log_id 分别为 500、502
insert into logs (content) values ('用户1登录成功');
insert into logs (content) values ('用户2下单失败');
3. Oracle 自增主键(序列 + 触发器)
Oracle 12c 之前不直接支持自增关键字,需通过“序列(Sequence)+ 触发器(Trigger)”实现;12c 及以后支持 GENERATED AS IDENTITY 简化操作。
例子1:Oracle 12c+ 简化自增(类似 MySQL)
-- 创建学生表,student_id 为自增主键(默认从1开始,每次+1)
create table students (
student_id int generated as identity primary key, -- 自增关键字
student_name varchar(50) not null,
age int check (age between 5 and 50),
class varchar(20)
);
自增主键的核心注意事项
- 自增不可回滚:删除中间记录后,新插入的记录会继续使用下一个自增值(如删除 id=2 的记录,下次插入 id 为 3,不会补 2),可能出现主键不连续,属于正常现象。
- 类型选择:小数据量用
int(最大约21亿),大数据量用bigint(避免自增溢出)。 - 避免手动修改:不要手动更新自增主键值,可能导致主键重复或自增序列混乱。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号