OO第三单元总结-JML
综述
“人生而自由,却无往不在枷锁之中。”
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为。
基于规格来实现程序,能够形式化验证程序的正确性,在检查各个模块时,也可以通过本模块的约束进行检查和验证。
设计策略
首先是关于JML一些语法的理解。行注释的表示方式为 //@annotation,块注释的方式为 /* @ annotation @*/。
requires子句定义该方法的前置条件(pre-condition)- 副作用范围限定,
assignable列出这个方法能够修改的类成员属性,\nothing是个关键词,表示这个方法不对任何成员属性进行修改 ensures子句定义了后置条件
以及其他例如任意、存在等表达式。
作业中,构建社交网络。关于如何合理存储相关的信息,由于输入信息中有个一个很重要的唯一的ID,注意到这一点,HashMap具有独特的优势。整体结构如下
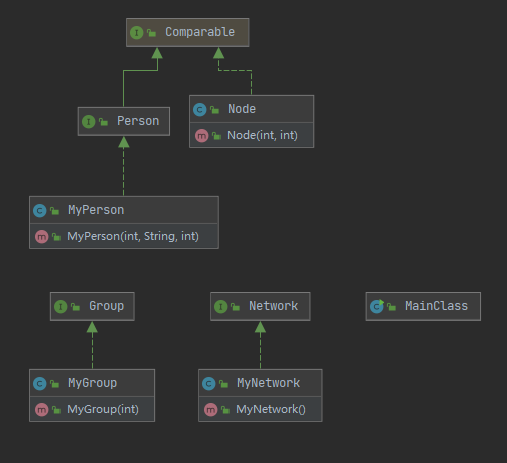
Network
需要实现几个比较核心的方法,以及相关数据的存储。正如上文所说,由于独特的ID,所以这里大量使用到HashMap。
- people
- groups
- messages
- emojis
均使用HashMap进行管理。
isCircle()
判断两点之间是否连通,关于这个方法,由于第一次作业中数据量不是特别大,采用dfs深度优先搜索进行判断。后续作业中指令条数较大,修改为并查集。
@Override
public /*@pure@*/ boolean isCircle(int id1, int id2) throws PersonIdNotFoundException {
if (!contains(id1)) {
throw new MyPersonIdNotFoundException(id1);
}
if (!contains(id2)) {
throw new MyPersonIdNotFoundException(id2);
}
if (id1 == id2) {
return true;
}
return isConnected(id1, id2);
}
isConnected抽离出来,主要是为了qbs重复使用,在第二次修改为并查集时也变得更加方便。
queryBlockSum()
查询块数,在判断连通分量时第一次作业也采用dfs,同时记录visited已访问结点,避免重复遍历。(如果没有任何优化,在互测中发现dfs超时的情况),在后两次作业中,通过查找并查集即可得到,时间复杂度迅速下降。
sendIndirectMessage()
间接消息,寻找最短路径算法。
- 使用迪杰斯特拉算法,并进行堆优化。
- 新增一个
Node类,用于实现Comparable接口。 - 利用
HashSet记录已经访问过的结点,避免重复运算。
Group群聊
这里在记录Person[]数组时,采用冗余存储,分别存储在HahsMap和ArrayList中,以空间换时间,适用于不同方法。
private final HashMap<Integer, Person> people;
private final ArrayList<Person> personArrayList;
不过不同的实现有些不同,这里采用ArrayList主要是为了配合Network里面的一些方法,否则的话使用价值不大。
qureyValueSum()
这个方法需要仔细思考,如果直接把JML翻译过来,实际上是一个二重循环,有很高的风险,在极坏的情况下(稠密),有很高的时间复杂度。
@Override
/*@ ensures \result == (\sum int i; 0 <= i && i < people.length;
@ (\sum int j; 0 <= j && j < people.length &&
@ people[i].isLinked(people[j]); people[i].queryValue(people[j])));
@*/
public /*@pure@*/ int getValueSum() {
return valueSum;
}
于是采取另一种设计,将valueSum作为一个属性,每一次权值发生改变时进行维护,具体在什么地方呢?由于Network中没有删人的操作,所以只有有人加入群聊、退出群聊、加好友时需要维护。这样一来,虽然有的方法变成了O(n),但是避免了二重循环。
基于JML规格的测试方法
JML规格实际上也给模块化测试提供了便利,在进行测试时,检查满足前置条件时,整个方法能不能按照规格实现变量assignable,后置条件ensures以及抛出相关异常等。
在验证时,可以利用不变式书写repOK方法进行测试。在验证时调用该方法,检查不变式是否满足。
for (int i = 0; i < 10; i++) {
assertEquals(mySet.size(), size);
assertFalse(mySet.isIn(i));
mySet.insert(i);
size++;
assertTrue(mySet.repOK());
assertTrue(mySet.isIn(i));
assertEquals(mySet.size(), size);
}
检查完各个模块之后,尤其是对于比较复杂的结构,还需要看模块之间是否正确。例如在Network中错误使用Group或Person,虽然检查时Network执行正确,但其他结构可能发生错误。
容器选择和使用
正如上文所说,由于Person,Group等具有独特的ID,所以在选择容器时考虑使用HashMap,在数量较大时相对容易管理,查找速度快。然而因为笔者在Network中写了一些操作需要数组形式的配合才更有效率,所以在Group中实际上是冗余存储,备份了ArrayList,变相空间换时间。
其他的例如在记录Visited访问列表时,同样可以利用ID这个属性,使用HashSet存储以缩短查找的时间。
性能问题
没出现性能问题,核心策略是有一些复杂的函数能否降为几个相对简单的小函数,或者改变为更新时维护。
第一次作业
主要性能点在qbs,但由于数据量不是特别大,带visited记录的dfs也能通过。
private boolean dfs(int id1, int id2) {
Stack<Integer> stack = new Stack<>();
HashSet<Integer> visited = new HashSet<>();
int now;
MyPerson myPerson;
stack.push(id1);
while (!stack.isEmpty()) {
now = stack.pop();
visited.add(now);
if (now == id2) {
return true;
}
myPerson = (MyPerson) (people.get(now));
if (myPerson.getAcquaintance().containsKey(people.get(id2))) {
return true;
}
for (Map.Entry<Person, Integer> entry : myPerson.getAcquaintance().entrySet()) {
if (!visited.contains(entry.getKey().getId())) {
stack.push(entry.getKey().getId());
visited.add(entry.getKey().getId());
}
}
}
return false;
}
在设计中采用Visited记录已经访问的结点,避免重复搜索以降低复杂度,由于第一次的数据量比较小,所以没有出现性能的问题。
第二次作业
数据量增大,修改qbs方法。去掉原来的dfs,改为并查集,并在加入新的人、关系时维护并查集。这样qbs方法变为O(1),加人、加关系的复杂度受到维护并查集的时间影响。
另一个比较复杂的是qgvs,如果照搬JML,互测会被hack。还是采取更新时维护的方法,去掉二重循环遍历,在加人、加关系、删人时维护value值,qgvs的性能有极大提升,这三个操作的复杂度上升,但相对来讲可以接受。
第三次作业
sendIndirectMessage,采用堆优化的迪杰斯特拉算法,可以勉强过线。这里如果不用堆优化,或许就有超时的风险。新增类实现Comparable接口,重写compareTo方法。
@Override
public int compareTo(Node o) {
return distance - o.getDistance();
}
另外再记录已经访问的结点
while (!que.isEmpty()) {
int uid = que.poll().getId();
if (visit.contains(uid)) {
continue;
}
// 没访问过,进行...操作,并标记
}
架构设计
MyNetwork,实现Network接口,最外层的结构,实现对外访问的方法。储信息Person[]信息father[]连通分量信息group[]群聊信息message[]消息emoji[]表情
MyPerson,实现Person接口,进行人员信息的简单管理,内部有一些简单关于属性的访问和修改方法。MyGroup,实现Group接口,群聊信息的简单管理可以增删改查,年龄的平均值、方差,每次访问时计算。valueSum由于每次计算的复杂度较高,所以作为属性,在每次更新MyGroup时维护该变量。人员的信息采用冗余存储,用HashMap和ArrayList同时存储。
图模型主要由上述三个类就可以构建出来,为了最短路径的效率,新增的配合堆优化的Node类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号