
Graph Traversal & Shortest Path
Graph Traversal
Graph 是一种在数学与计算机科学中被广泛用到的数学对象. 一个graph由两个集合组成, 也即:\(G=(V, E)\), 其中 \(V\) 是包含着所有 顶点 的 顶点集, \(E\) 是包含所有 边 的 边集.
相关术语约定:
- 我们称两顶点 相邻(incident/adjacent) 当 \(E\) 中包含这两个顶点连成的边
- 对于 \(V\) 中两顶点 \(u,v\),
- 若一个图是 有向图, 则 \(E\) 中的边为 有序点对, 也即 \((u, v)\)
- 我们称u为边 的
- 若一个图是 无向图, 则 \(E\) 中的边为 无序点对, 也即 \(\{u, v\}\)
(或者替代成同时含有两条有向边 \((u,v), (v,u)\) )
- 若一个图是 有向图, 则 \(E\) 中的边为 有序点对, 也即 \((u, v)\)
- 我们用 度 degree 来表示每个顶点相连
- 对于有向边 \(e=(u, v)\)
- 我们称 \(u\) 是 \(e\) 的 尾 tail, \(v\) 是 \(e\) 的 头 head.
- \(e\) 是 \(u\) 的 出边 outgoing edge, 是 \(v\) 的 入边 incoming edge. 相对应的, 我们有 出度 out-degree 与 入度 in-degree
图一般分为 简单图 sample graph 与 复杂图 complex graph.
我们定义:
- 重边: 当边集 \(E\) 中存在多个头尾相同的重复边时, 我们说该图含有 重边
- 自环: 当一条边头尾为同一个顶点时, 我们称这条边为 自环 self-loop
一个简单图, 是不含有重边, 自环的图.
我们大部分时候都会着重讨论有向简单图
图的表示/储存
(我们这里假设是 简单有向图 , 无向图可以理解为存在两条 仅有方向相反的边)
(我们用 \(N,M\) 表示顶点数与边数)
1. 直接存边:
我们直接把所有相连的边以元组列表的形式储存. 这个方法很符合我们数学上对graph的定义, 但它的性能大部分时候十分糟糕, 比如我们想知道所有与顶点v相连的结点, 需要遍历整个边集, 所以需要特定的结构去优化.
2. 邻接矩阵 Adjacent Matrix
我们用二维数组A[][]表示两个顶点的相连情况. 其中A[u][v]的值表示顶点u到v的状态.
- 对于无权图, 我们可以用
bool数组,True与Flase来表示是否相连. - 对于有权图, 我们用数值来表示边的权值, 用一个极大的数来表示不相连
- 通常在实现最短路算法时, 我们使用
int的最大值inf表示不相连(也即 \(\approx\infty\))cpp:INT_MAXjava:Integar.MAX_VALUEpython: python的整数没有传统意义上的最大值, 我们通常使用sys.axsize(平台相关的最大正向索引值)来表示“无限大”的概念, 但这可能不是整数的上限
因为邻接矩阵需要固定的 \(\Theta(N^2)\) 的存储空间, 所以常用语稠密图, 也即边数接近 \(O(N^2)\) 的图.
对于稀疏图的存储, 我们很自然的想到可以只存储已经存在的边, 这就引出了下述几种方法(其实也就是方法1直接存边的优化)
- 通常在实现最短路算法时, 我们使用
3. 邻接表(也叫邻接链表) Adjacent List
我们用 \(|V|\) 个链表来存储每个顶点的相邻的顶点. 如:

对于一条有向边 \((u, v)\) , 他只会出现在邻接链表Adj[u]中, 所以邻接表使用的空间是 \(O(V+E)\)
对于有权图, 我们只需要稍加修改, 就可以储存:
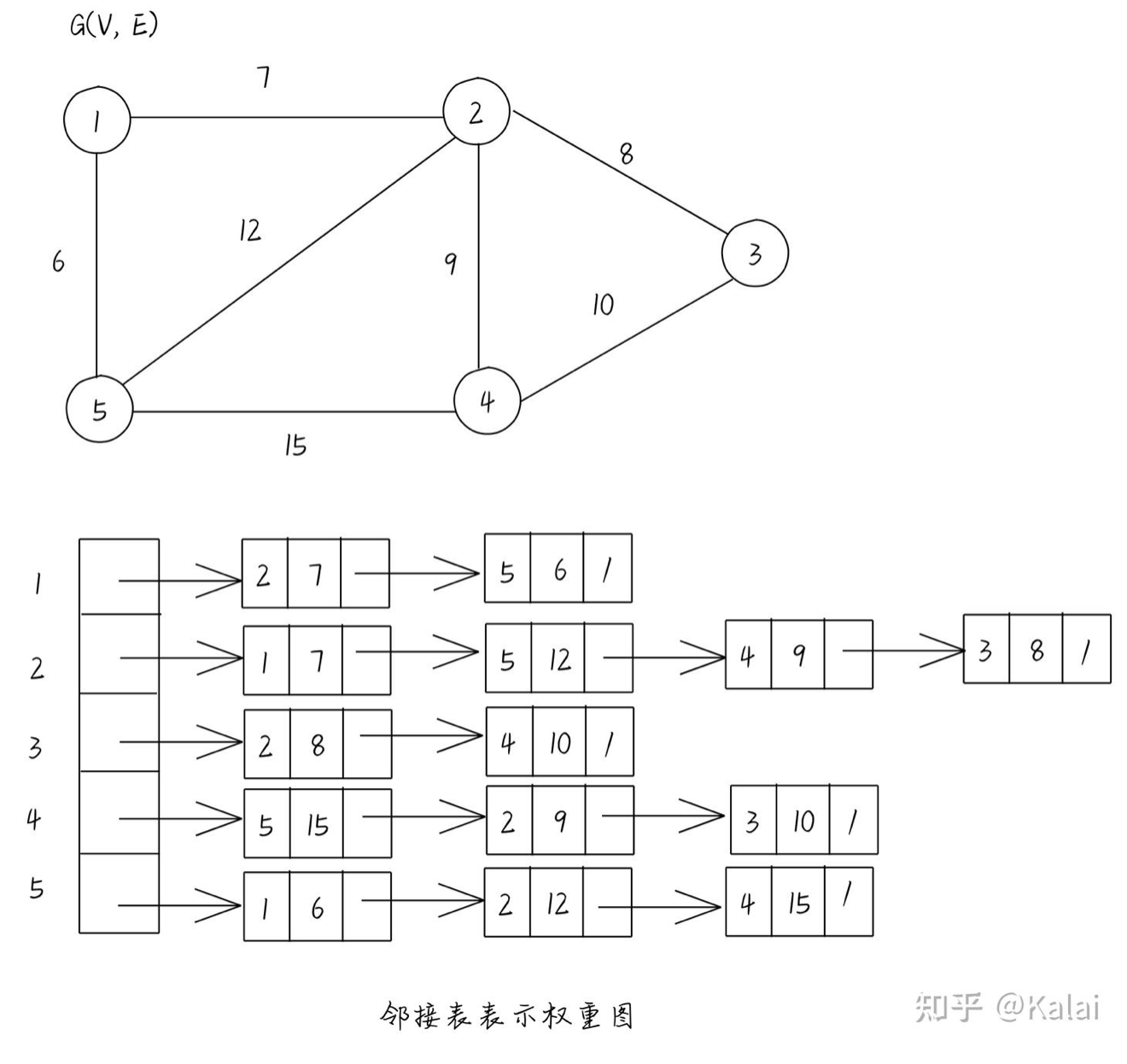
对于邻接表, 我们在输入时需要不断的动态拓展每个顶点邻接链表的大小, 在计算机底层的角度, 这会造成许多性能浪费. 所以我们考虑如何以静态的方式, 提前分配好空间, 避免性能浪费.
4. 链式前向星 Forward Star With Next Array
Also names "静态邻接表 Static Adjacency List"
我们用两个数组来表示这个图:
edge[M]: 用来存储全部 \(M\) 条边. 下标i表示第i条边
其中, 一条边的起点不在struct Edge{ int to, weight, next; }edge[M];edge[M]中存储, 而是在head[N]中记录该链表的头部.
to表示这条边的终点;
weight表示这条边的权重
next表示下一个条与这个边起点相同的边head[N]: 存储邻接关系. 下标i表示第一次出现以顶点i为起点的第一条边在edge中的下标.
当我们需要遍历一个顶点u的所有出边时, 只需要从edge[head[u]]出发, 不断通过next指针向后遍历所有以u为起点的边即可.
本质上链式前向星就是通过维护head[N]与edge.next指针, 从而事先为链表腾出紧凑的大块空间, 从而避免动态拓展空间带来的额外复杂度.
Shortest Path
在最短路问题中, 我们通常是在一个图中, 寻找从出发点 s 到目标点 t 的最短路径. 我们做一些符号约定:
1. 符号约定
\(E, V\): 分别指该图的 边集 和 顶点集
\(n, m\): 在复杂度分析中通常指图的 顶点数 和 边数
s: 最短路问题的出发点
D(u): 从源点 s 到u的 实际 最短路径(也即我们全部过程完成后的实际结果)
dis(u): 从源点 s 到u的 过程 最短路径(也即在算法过程中, 当前能得到的最短路径长度)
w(u, v): 边(u, v)的权值
我们只考虑有向正权简单图.
最短路算法
一般来讲, 对图的搜索分为 “盲目式搜索(Blind Search)” 和 “启发式搜索(Heuristic Search)”.
盲目与启发
1. 盲目式搜索
盲目式搜索, 也叫 无信息搜索(Uninformed Search), 是指在搜索过程中不使用任何关于目标位置或路径代价的额外信息, 仅根据问题的初始状态、目标状态和操作规则进行系统性探索。
假设我们想在一个迷宫上找到出口, 如果我们采用盲目式搜索, 就只能盲目的以 某种特定的遍历方式, 以最坏可能走遍整个迷宫的所有路线的代价, 找到出口.
- 如果我们不断以出发点为圆心, 螺旋的由近及远不断遍历周围所有可能的路线, 这就是BFS(breadth first search)
- 如果我们不断的沿着一个方向直到走到头, 然后退回一步到前一个岔口尝试另一个方向, 这就是DFS(depth first search)
- 如果我们贪心的不断记录从出发点到迷宫中上每个路口的最短距离, 并以此为基准继续更新其他点, 直到我们最终找到了出口, 这就是Dijkstra‘s algorithm.
etc.
1.1. 广度优先搜索 BFS
我们注意到, BFS只关心“部署”(这里是从一个结点到另一个结点), 而不关心每一步的权重, 所以我们只使用BFS无法解决有权图的最短路, 所以本示例仅解决每一条边权重均相等的情况以做演示
这里的“无法解决”指只能通过遍历所有路径才能最终以指数级别的时间复杂度找到最短路
有权图情况详见 3. Dijkstra‘s”
我们假设:
- 用连续的正整数表示结点编号
- 二维
bool数组edges[u][v]的值表示u,v两点间是否相连 bool数组is_visited[]表示结点是否已被访问过
(使用cpp, 因为笔者好久没写了, 复习一下)
int BFS(int s, int t){
queue<tuple<int, int>> vertics;
vertics.push({s, 0});
is_visited[s] = true;
while(vertics.size() > 0){
auto cur = vertics.front();
vertics.pop();
for(int i=0; i<N; i++){
if(edges[get<0>(cur)][i] && (!is_visited[i])){
if(i == t)return get<1>(cur) + 1;
is_visited[i] = true;
vertics.push({i, get<1>(cur) + 1});
}
}
}
return -1;
}
1.2. 深度优先搜索 DFS
分析同上, 不过由于函数递归是天然的stack, 我们使用递归(更简洁)
int DFS(int s, int t){
is_visited[s] = true;
if(s == t)return 0;
int dis = INT_MAX;
for(int i=0; i<N; i++){
if(edge[s][i] && (!is_visited[i])){
dis = min(dis, DFS(i, t))
}
}
is_visited[s] = false;
return (dis == INT_MAX ? INT_MAX : dis+1);
}
但是注意, 虽然BFS和DFS都是通过枚举所有路径寻找有向无权图最短路, 但通常DFS性能表现较差. 因为BFS第一次寻找到t时就已经是最短路了, 但DFS需要枚举出所有的路径(终点为t or 到头遇不到t)才能判断出最短的路径. 所以DFS不适合最短路算法, 这里仅作参考了解DFS思想
1.3. Dijkstra’s algorithm
D一串字母算法是通过特殊的顺序, 对BFS算法在有权图中的优化. 其本质上是使用贪心的思路, 与BFS类似的(优先遍历步数最少的), 优先遍历与源点“实际距离”最小的点, 从而保证了在有权图中的优异表现.
1.3.1 idea
其核心思路很简洁:
- 初始化优先队列
- 我们先将
s压入最小堆优先队列PQ, 其key为 \(0\) - 将图中剩余的 \(n-1\) 个顶点全部压入
PQ,key设置为\(+\infty\)
- 我们先将
- 我们取出
PQ的最优先元素顶点p, 对所有以p为起点的 出边 进行 松弛(relax) 操作
松弛:
这个操作在多个最短路算法中都会用到, 本质上类似dp的状态转移.
我们对某条边(p, q)进行松弛操作, 当满足条件:
dis(p) + w(p, q) < dis(q)
此时我们更新从源点到q的估计最小距离.
那么我们很轻易的就可以写出这个算法的建议代码了:
1.3.2 implement
我们用 edgeTo[]记录最短路径的 前驱结点 , 也即在我们最后得到的最短路径中, 到达结点u的最短路径的前一个结点是edgeTo[u]
def relax(e):
u, v = e.start, e.end
if not PQ.contions(v): return
if dis[u] + e.weight < dis[v]:
dis[v] = dis[u] + e.weight
edgeTo[v] = u
PQ.change_priority(v, dis[v])
def dijkstra(vertices, s, t):
PQ = PriorityHeap()
PQ.add(s, 0)
infinity = float('inf')
for u in vertices:
if u != s: PQ.add(u, infinity)
while PQ.size() > 0:
cur = PQ.pop()
#留待优化
for e in edge(cur): relax(e)
return dis[t]
1.3.3 Short-circuiting优化
我们注意到, 当一个顶点 u 被弹出 PQ 时, 从源点到 u 的最短距离就已经被优化成 实际最短距离 , 也即D(u) = dis(u). 这也是我们在relax()时, 不去松弛终点不在PQ中的边的原因. 出于此, 如果我们只想知道源点s到t的距离, 只需要等到t被弹出后, 就可以结束算法, 而不需要继续进行后续的过程.
也即, 我们在上述代码的“留待优化”行添加
if(cur == t)return dis[t]
即可
1.3.4 正确性
每次的弹出dis()最小顶点的操作, 本质上是一种贪心算法, 我们选取当前已知的从s出发到达最近的点, 进行松弛.
我们采用数学归纳法来证明: 每当我们对 PQ 进行弹出堆顶操作时, 源点 s 到堆顶顶点 v 有 dis(v) = D(v)
base case: 对于第一个元素, 是源点 s 自己, 距离显然为0
接下来我们采用 反证法 : 我们假设 p 是第一个满足 dis(p) != D(p) 的堆顶顶点
那么说明存在一条path: (s, ..., p), 其权长小于我们已找到的最短路径
首先我们能证明, 该路径上的所有点, 都不在我们的最小堆PQ里.
- 否则由源点到该在堆中的路径中间点
v的长度:dis[v]已经大于原最短路径dis[p], 也即D(p)>dis(p), 与最短矛盾
那么, 由于我们的假设, 该路径上的倒数第二个点q(到p的 前驱结点 )满足D(q) = dis(q), 那么很明显当我们遍历到q被弹出时, dis[p]必定会被relax为dis[q]+w(q, p), 此时我们有 dis(p) = D(p)
综上, 我们证明了该算法的正确性.
在之前的分析中, 我们一直保持的一个前提就是, 该图为非负权图, 当有负权时, 我们的很多推断便是不一定正确的. 对于此的解决方法, 我们之后会介绍 Johnson 全源最短路径算法
3.5 时间复杂度分析
在优先队列的实现版本中, 我们总共会进行 \(O(m)\) 次修改 PQ 的键值, \(O(n)\) 次pop操作. 理论上(采用斐波那契堆)最优的性能是 \(O(m+n\log n)\)
此外还有很多不同的实现方式, 会得到不同的时间复杂度

1.4 Floyd algorithm
我们定义一个三维数组f, f[n][x][y] 表示在仅经过前 \(k\) 个结点的情况下, 从结点x到y的最短距离.(x, y不一定在 \(k\) 的范围内)
那么很自然的, 我们要求出 f[n][s][t] 的值. 那么我们只需要类似动态搜索的, 递归的求出值便可:
- base caes:
f[0][x][y]有三种取值:- 当x=y时, 取0
- 当x与y直接相连时, 取该边的权值
- 当x与y不直接相连时, 取一个极大值
- recursion(或者状态转移方程):
f[k][x][y] = min(f[k-1][x][y], f[k-1][x][k] + f[k-1][k][y])
最小值中的前者表示不使用k的最短距离, 后者表示途径k的最短距离
代码示例:
def floyd(n, s, t):
inf = sys.maxsize
f = [[[inf for _ in range(n+1)] for _ in range(n+1)] for _ in range(n+1)]
for j in range(1, n+1):
for k in range(1, n+1):
if(j == k):f[0][j][k] = 0
elif(is_connected(j, k)): f[0][j][k] = weight(j, k)
for i in range(1, n+1):
for j in range(1, n+1):
for k in range(1, n+1):
f[i][j][k] = min(f[i-1][j][k], f[i-1][j][i] + f[i-1][i][k])
return f[n][s][t]
或者可以优化空间, 只使用二维数组:
def floyd(n, s, t):
inf = sys.maxsize
f = [[inf for _ in range(n+1)] for _ in range(n+1)]
for j in range(1, n+1):
for k in range(1, n+1):
if(j == k):f[j][k] = 0
elif(is_connected(j, k)): f[j][k] = weight(j, k)
for i in range(1, n+1):
for j in range(1, n+1):
for k in range(1, n+1):
f[i][j][k] = min(f[i-1][j][k], f[i-1][j][i] + f[i-1][i][k])
return f[s][t]
2. 启发式搜索
启发式搜索, 也叫有 信息搜索(Informed Search),是指在搜索过程中利用启发函数 h(n) 来估计从当前节点 n 到目标的代价, 从而优先探索 “更有希望” 的路径。
很自然的, 还是上述例子, 当我们确定了(估计到)出口的大致方位(h(n)), 例如出口在东方, 我们是可以直接向着这个方位开始搜索(直接走向出口的方向). 但我们目测的大致方位有时并不一定是正确的, 我们需要不断调整我们的h(n).
而对启发函数 \(h(n)\) 的选取, 通常有如下要求:
- 可采纳性 Admissible
也即, 启发函数的预估值不应大于实际最短距离.\[h(n)\le h^(n) \]其中, \(h^*(n)\)是实际最短距离
这样我们能确保我们找到的最短距离是最短的. - 一致性 consistency
对任意边(m,n), 我们有:\[h(n)\le h(m)+w(m,n) \](这也是Dijkstra, A进行“松弛操作”的理论基础)
这样可以保证A不需要重复访问节点
2.1. A* algorithm
事实上A* Algorithm与Dijkstra‘s Algorithm的思路类似. 但是此时我们使用结点的综合优先级H(n)作为评估每个结点的“预计代价”
我们定义:
其中:
- \(H(n)\)为综合优先级, 是我们评估某一节点的参考数据
- \(g(n)\)为从源点\(s\)到该结点的实际代价
- \(h(n)\)为从该结点到终点\(t\)的估计代价
2.1.1 思路
那么我们的思路也很明确了, 与Dijkstra‘s Algorithm类似地:
- 将所有结点放入优先队列
pq中(小根堆), 除源点外的h(n)均设置为正无穷(充分大即可) - 弹出堆顶结点, 对其所有出边进行松弛操作
- 此处的松弛是针对实际代价\(H(n)\)的
- 重复2直至我们弹出到终点
2.1.2 启发函数\(h(n)\)
对启发函数的选取是决定A* algorithm性能的关键.
- 在二维平面图中(例如平面地图), 我们常常利用x, y坐标的运算估算距离.
- 在网格地图中, 我们常使用Manhattan Distance: 我们定义 \(h(n) = |x_1-x_2|+|y_1-y_2|\)
- 在存在斜向移动的地图中, 我们使用Euclidean Distance: \(h(n) = \sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\)
- 对角线距离:
\[h(n) = d_{min} + (d_{max}-d_{min})\cdot(\sqrt{2}-1) \]其中, \(d_{min}=min(\Delta x, \Delta y)\), \(d_{max}=max(\Delta x, \Delta y)\) - 而在一般的图中, 我们没有潜在的几何信息, 所以一般直接设置\(h(n)=0\), 此时A*直接退化为Dijkstra's algorithm.
实现类似Dijkstra, 不再赘述.
(本文代码均为本人手打, 不代表参考链接作者代码水平)
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号