个人项目:论文查重
|作业所属课程|https://edu.cnblogs.com/campus/gdgy/Networkengineering1834|
|---|---|---|
|作业要求|https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146|
|作业目标|写一个论文查重程序,|
一、github仓库
https://github.com/dddink/3118005283
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 20 |
| Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 100 | 150 |
| Analysis | 需求分析 (包括学习新技术) | 50 | 60 |
| Design Spec | 生成设计文档 | 15 | 20 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 40 | 30 |
| Coding | 具体编码 | 200 | 200 |
| Code Review | 代码复审 | 30 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 35 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 605 | 680 |
三、计算模块接口的设计与实现过程
类图结构如下:
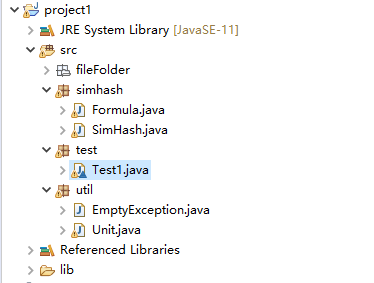
采用SimHash算法
- SimHash算法主要的工作就是将文本进行降维,生成一个SimHash值,也就是论文中所提及的“指纹”,通过对不同文本的SimHash值进而比较海明距离,从而判断两个文本的相似度。
- SimHash算法主要有五个过程:分词、Hash、加权、合并、降维。
- Simhash可以计算文本间的相似度,我们可以通过simhash算法计算出文档的simhash值,通过比较各个文本的simhash值之间的汉明距离的大小来判断其相似度,汉明距离越小,则相似度越大。一般大文本去重,大小<=3的即可判断为重复。
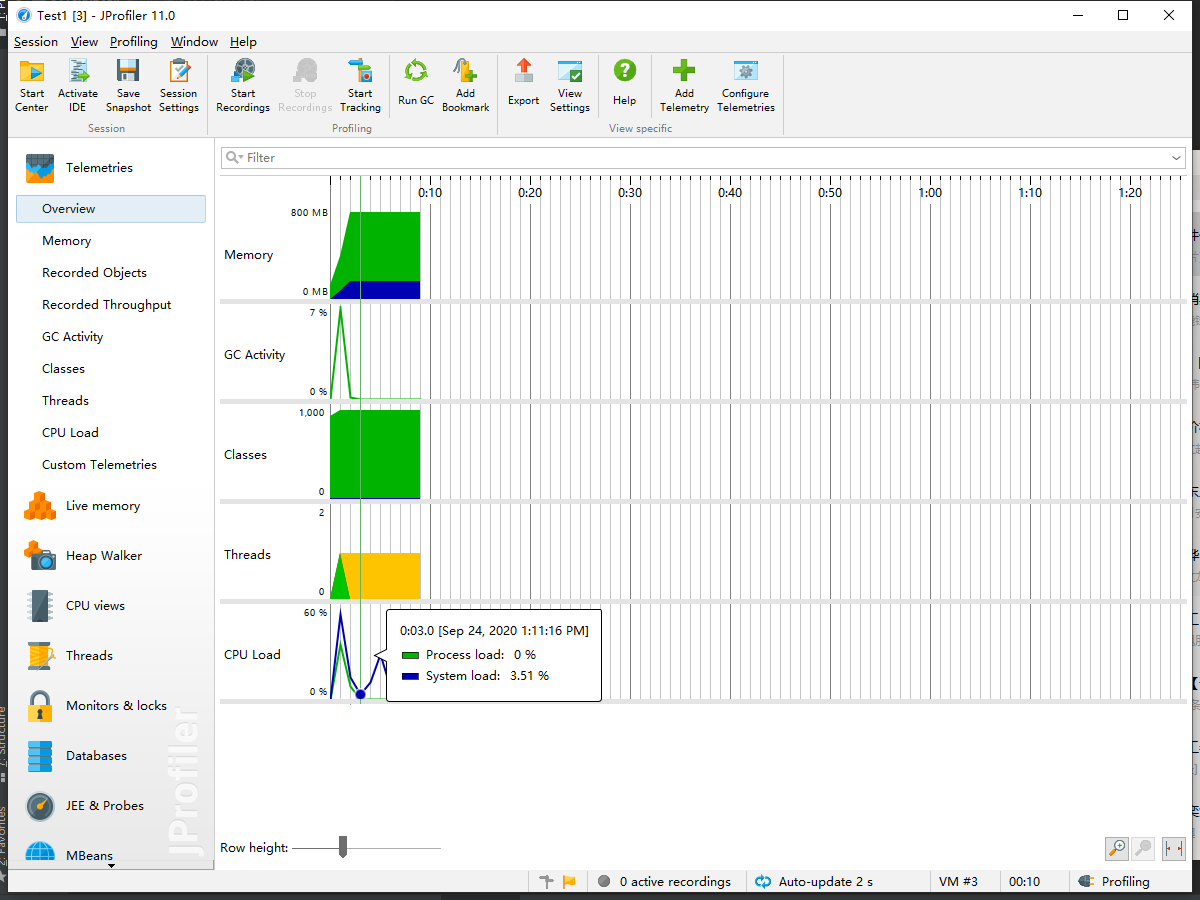
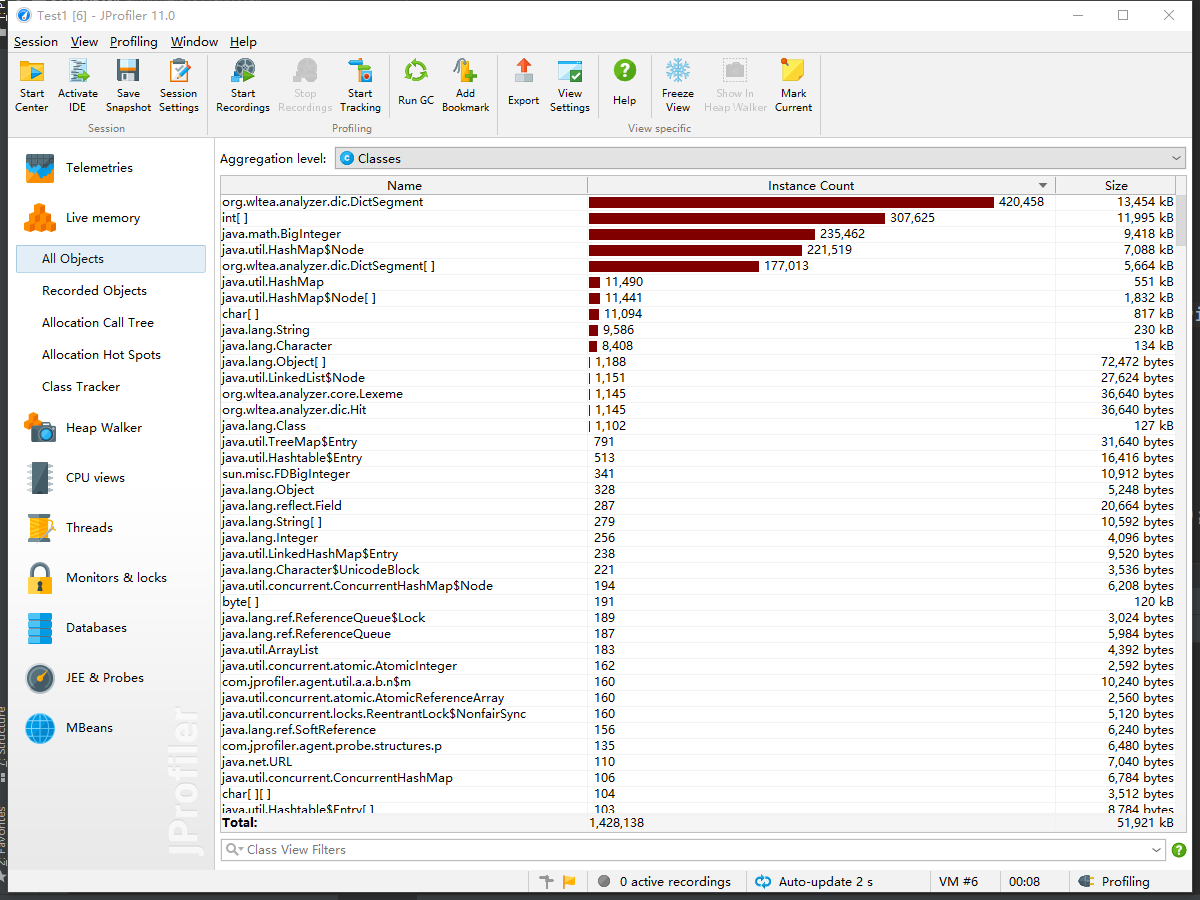
四、计算模块接口部分的性能改进
- 下面是用JProfile测试得到的结果图。
- 性能测试
- 内存消耗
五、测试相关
- 测试orig.txt和orig_0.8_add.txt的相似度

- 测试orig.txt和orig_0.8_del.txt的相似度

- 测试orig.txt和orig_0.8_dis_10.txt的相似度


 浙公网安备 33010602011771号
浙公网安备 33010602011771号