关于API网关(二)成本
成本就是钱,钱是不得不考虑的头等问题。
按照我的理解,网关系统的成本主要体现在3个方面:带宽、机器、人
下面详细说一下。
1. 带宽成本
这一点和其他系统不太一样,其他系统基本都在内网,不太会涉及到带宽成本。但是API网关是内网和公网连接的地方,是所有流量的出入口,带宽成本巨大。像一些直播类、视频类的业务,带宽成本占总成本的比例是相当高的。
说了半天,怎么节约带宽成本呢?
节约带宽,说到底,就是减少数据传输量。可以从下面几点着手:
1.1 压缩数据
数据压缩是很常见的一种手段,要传输的数据经过压缩之后,既可以减小带宽,又可以提高传输速度。
一般来说,API网关对外提供HTTP协议的接口,数据交互的格式大多是JSON或者XML,开启数据压缩(如gzip)和不开启,数据大小会相差很多。
理论上,数据压缩是有极限的,那是不是在极限范围之内,数据压缩的越厉害越好呢?也不是,数据压缩也是有成本的,压缩比越大,耗费在数据压缩和解压的上的时间就越长。所以,数据压缩,本质上是一个时间换空间的问题,看需要,取一个合适的压缩比就好。
1.2 减少交互次数
比如一个查询店铺信息的功能,店铺信息包括名称地址、店铺等级、粉丝数。这三个信息分别由三个独立的服务提供。你可以有两种办法实现这个功能:
分别请求三个接口,返回这三个信息后,客户端再组装。
只请求一个接口,数据由API网关分别从三个服务获取,组装好之后,一并返回。

显然是第二种更划算,传输的数据总量更小。当然,也不是说,交互的次数越少越好,否则一次请求的时间就会太长,影响用户体验,而且过多的聚合接口,有时会返回客户端并不需要的数据,白白浪费。所以,不能一味地为了聚合而聚合,而是要在保证API设计合理的前提下,尽可能减小数据次数,以达到降低带宽成本的目的。
1.3 HTTPS
为了数据传输安全,现在的API基本上都是对外提供https服务了,我们知道,https是在tcp层和http层之间加了一层TLS协议,主要是用来做证书、协议协商、秘钥等数据的交换。数据是安全了,但是也给每次请求增加了很多额外的数据。不要小看这些数据,在很多场景下,真正的业务数据,甚至还没有证书大。对流量很大的网关系统来说,这是一笔不小的带宽成本。

一个很自然的想法是,能不能只在初次请求时进行安全数据的交换(握手),以后的交互,跳过这一阶段,这样既能降低数据传输的大小,也能提高响应速度。
实现这个功能,有两种办法,一种是SessionID,相当于会话建立之后,服务端下发给客户端一个代表本次会话的ID,后面客户端每次请求时带上这个id,表示我已经不需要进行秘钥等数据交换了。还有一种办法是SessionTicket,和SessionID原理差不多,都是为了跳过握手阶段的交互过程,不同的是,SessionTicket中包含了建立连接时的握手信息,也就是说,SessionID的实现是把握手信息存在服务端,SessionTicket是把握手信息存在客户端,其中利弊,大家可以想一想。

2. 服务器成本
网关系统作为全部流量的出入口,一般需要部署很多服务器,服务器是很贵的,因此,在系统设计和技术选型上,服务器成本也是需要考虑的重要因素之一。
因此,一些在技术上看起来是最优解的方案,考虑成本等因素后,工程上也许并不会采用。土豪们当俺没说。
这里说几个场景,当然,不一定适合每个人,大家一起看一下就好。
2. 1 尽可能压榨硬件资源
2.1.1 资源利用率
大多数API网关,因为主要任务是鉴权、限流、数据转换等CPU密集型的功能,因此,选择服务器时,可以大一点的CPU核数,小一些内存。
比如一台4核16G的机器,当CPU到了80%时,内存只到了30%,这就太浪费了。
不是说资源利用率越高越好,一般来说,业务峰值时刻,资源利用率40%比较好。
为啥是40%呢?那岂不是白白浪费60%,都是钱啊,心疼。
40%是因为,考虑到容灾,网关系统一般都是多机房(多地域)部署的,一旦某个机房出现问题,必须将流量切换到其他正常的机房,这时,该机房的流量就会上涨一倍,如果之前资源利用率是80%,那就要出现服务器崩溃了。

2.1.2 单机吞吐量
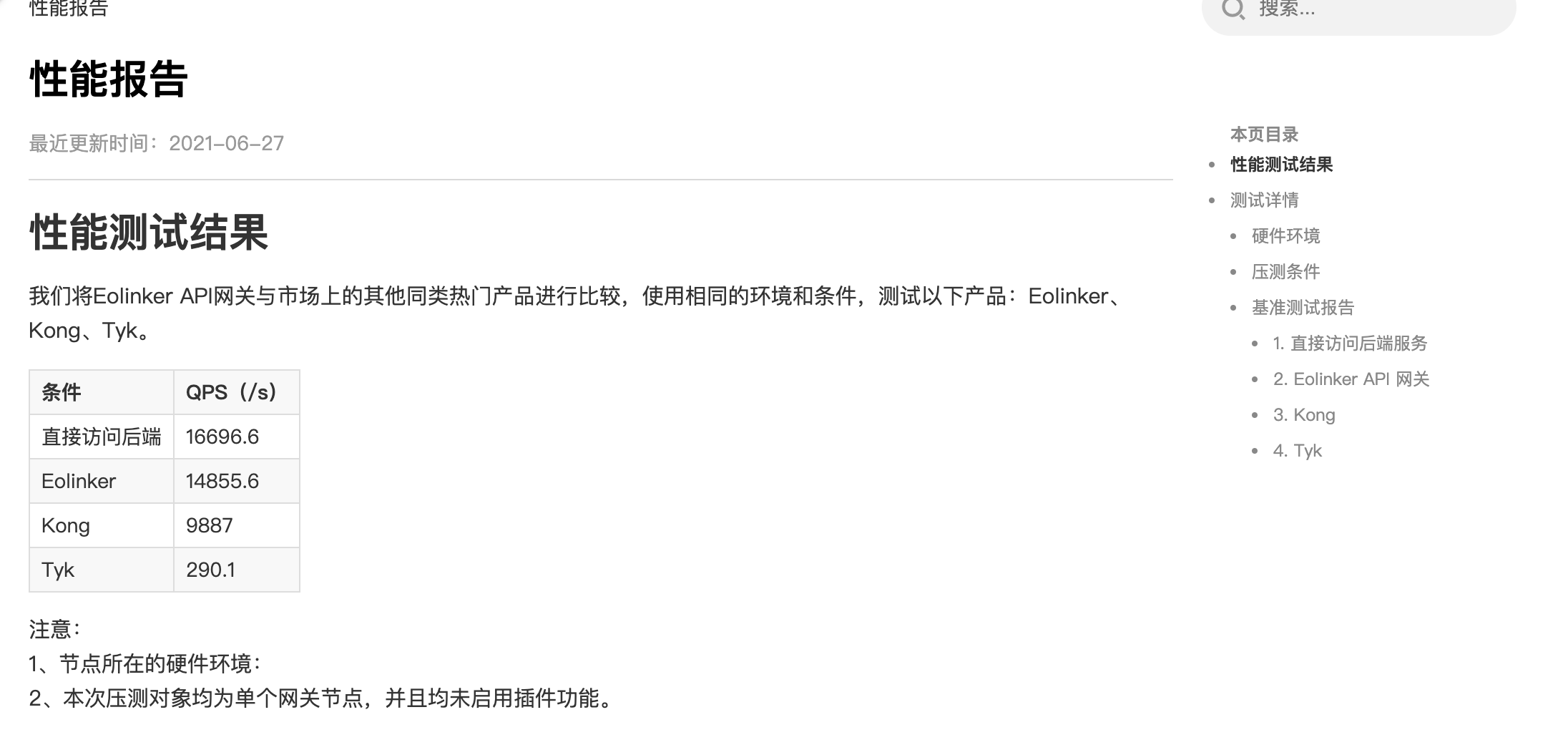
上一篇《关于API网关(二)性能》中,我们讲了关于吞吐量的问题。资源利用率一样的情况下,吞吐量越高,成本就越低。
这就涉及到技术选型的问题了。以性能著称的Nginx+Lua,是一个很好的组合。如果换成更加大众的Java的话,吞吐量估计就得下降一些了。
再说一个场景,比如这个网关系统是一个开放平台,类似微信公众平台,百度开放平台这种,用户注册是一个相对低频的功能,但是用户信息读取却是一个极高频的功能。用户信息可能包含用户的等级,用户的权限,用户的流量包,用户的qps限制等等,这些数据来自不止一个后端服务。比如网关峰值流量是100Wqps,那么,即使把这些信息全部放到Redis中,每个请求需要读取5次Redis,那么Redis集群的峰值QPS就是500W。这听起来挺。。。贵的。所以,解决办法就是每台机器都在本地把这些信息缓存一段时间,哪怕只有10s也是好的。然后你就可以换一个规模小一点,便宜一些的Redis集群了。
所谓高并发,都是缓存扛过来的。
2. 2 冷热数据区分对待
网上很多前辈们都有介绍,不详细说了,举几个例子。
比如,日志保留1天占用30G磁盘,那么,你有个60G的磁盘就够用了。保留时间越长,需要的磁盘就越大,费用就越高。
比如,普通的机械磁盘就可以了,那么就不需要SSD。
比如,为了查询日志,你把日志收集到ES之类的搜索引擎中,一般来说,7天的日志就差不多了,再多的日志,可以保存到相对便宜的类似HDFS之类的大数据存储系统中。成本会比搜索引擎低。数据少了,你日志搜索起来也快,是吧。
比如,已经淘汰掉的数据,及时清理,用户已经注销了,那么用户信息就没必要占用Redis的存储空间了。
比如,接口已经下线了,那么关于这个接口的一切数据都可以清除掉。
等等等等。
LRU的思想,无处不在。
3. 人的成本
这里说的人的成本不是指我等程序员的工资,那是HR的事情。
站在研发的角度讲,人的成本就是我每天的时间都耗在哪里了。
API网关的研发,大多是比较兴奋和痛苦的。兴奋是因为维护这么大流量的系统,本身就是激动人心的事情。痛苦是因为,所有服务的入口都在你这里,这就意味着,你的主要工作其实是个客服。
各种用户的问题、各种后端服务的问题、各种接入、联调、上下线的咨询问题,等等等等。
所以说,对一个网关系统的程序员来说,想安静写会儿代码,绝对是一种奢求。因为,每天找你查问题的人,实在是太太太太多了。不止网关系统,基础平台类的研发都是半个客服。
吐槽完毕,问题还是得解决。
个人认为,除了答疑群,FQA,答疑机器人,值班机制等等治标不治本的措施外,最根本最有效的手段,其实在代码本身。
一个陈旧的,满是祖传代码的,绕来绕去的系统的维护成本是极高的。产品们有时抱怨,为啥这么简单的一个需求,研发要排期好多天,那是因为,研发的大部分精力都耗在客服事业上了。
客服工作是不可避免的,但是,一个神清气爽的系统的客服人员会幸福很多。
所以呢,为了降低客服成本,必须好好写代码。系统的维护成本降下来,研发才有时间做更多事情,而能做更多事情,正是管理者最希望看到的。
一点大一些的公司,则会选用一些成品的API网关系统,把客服的工作外包出去变成API网关公司的运维,这样本公司的研发就能腾出手来做一些更“高级”一点的事情,相对更划算一点。
像广州第一家上市的软件企业佳都科技,就是选用了Eolinker的goku网关,网关的问题一律交给他们解决,自己的开发重心则保持不变,保持快速的发展速度。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号