惊了!随机淘汰竟然能打败LRU?这种“2随机选择”策略逆袭成为缓存管理黑马!
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
你以为LRU是最优的缓存策略?2-随机告诉你:真相没这么简单!
在很多开发者眼中,LRU(Least Recently Used) 缓存替换策略几乎是圣杯般的存在——谁最近没用,就淘汰谁。看起来合理:最近访问的数据,很可能还会被再次使用,这和我们日常遇到的“热点数据”逻辑一脉相承。
然而,一个经典计算机体系结构教授却曾大胆提出:“其实用随机淘汰(random eviction),也没那么差。”
起初听起来有些离谱。随机?这不是让缓存命中率靠运气吗?但如果我们把问题稍微泛化一下,做一点微创新,比如:从缓存中随机挑两个候选项,然后淘汰它们中“最久未使用”的那一个(2-random LRU),结果会不会更有意思?
答案是:非常有意思。
实测数据:2-random vs. 传统淘汰策略
以下是基于 SPEC CPU 测试集,在一台类似 Intel Sandy Bridge 的架构上,使用三层缓存(L1: 64KB、L2: 256KB、L3: 2MB)进行测试的结果。所有缓存采用相同的替换策略:
| 替换策略 | L1 (64KB) | L2 (256KB) | L3 (2MB) |
|---|---|---|---|
| 2-random | 0.91 | 0.93 | 0.95 |
| FIFO | 0.96 | 0.97 | 1.02 |
| LRU | 0.90 | 0.90 | 0.97 |
| Random | 1.00 | 1.00 | 1.00 |
注:数据为与 Random 策略的相对 Miss Rate,越低越好。
可以看到,2-random 在大多数场景下表现逼近甚至超过了 LRU,尤其是在 L3 缓存这种大容量场景下更为明显。
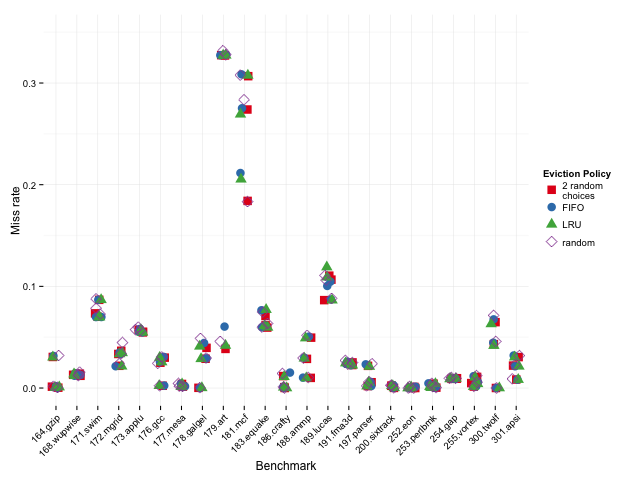
如图所示,当缓存 Miss 率较高时,2-random 反而优于 LRU。
为什么 L3 中 LRU 不一定是最优?
三级缓存系统下,L1 和 L2 命中的数据并不会进入 L3 的访问路径,这让 L3 无法判断某条缓存行是否“最近使用”。这种信息的不对称,让传统 LRU 策略在 L3 中失去优势。
而 2-random 不依赖精确访问时间,而是引入了一定“随机性+局部淘汰判断”机制,反而在这种模糊场景下表现更稳定。
单层 vs. 多层缓存策略对比
进一步的测试将单级缓存和多级层次缓存进行了对比(L3 尺寸从 512KB 到 16MB 变化):
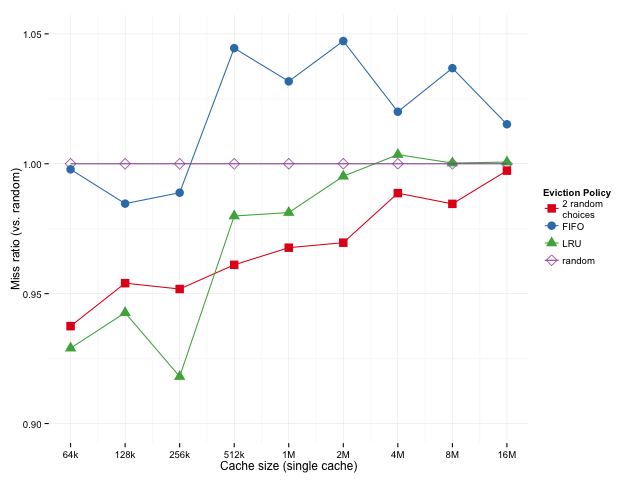
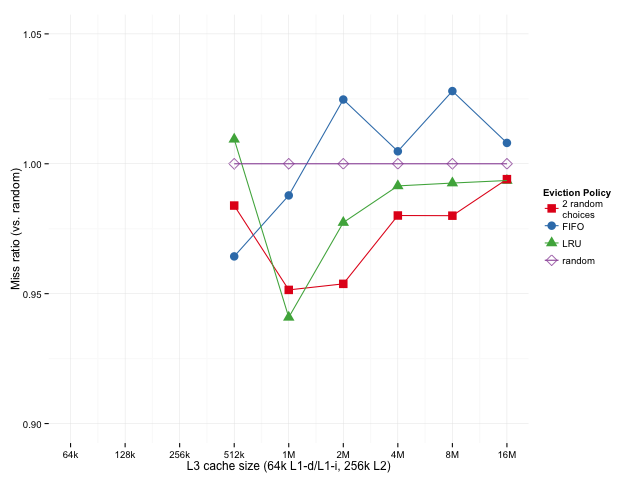
观察几何平均 Miss 比率,我们发现:
- 小缓存下 LRU 占优
- 大缓存下 2-random 更胜一筹
这种结论,在多级缓存架构下依旧成立。说明“2-random 适用于大缓存”不是偶然现象。
Miss Rate 分布也支持这个结论
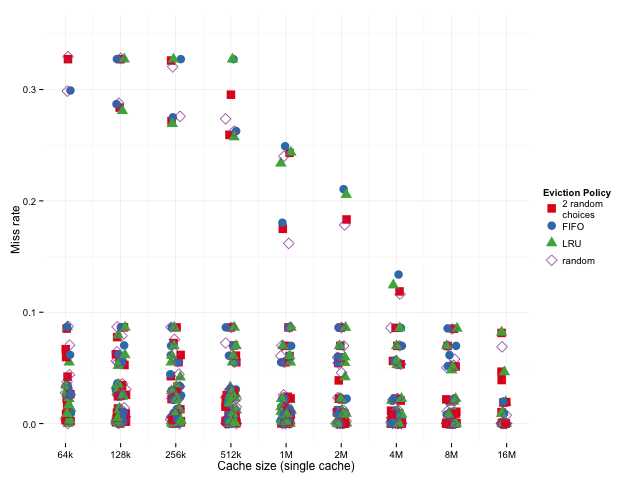
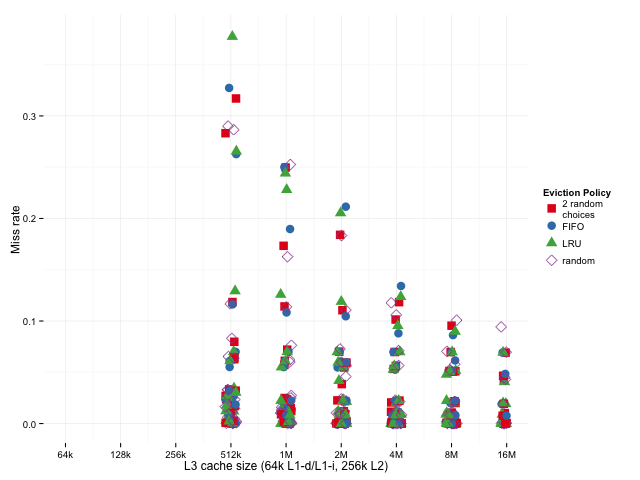
上图展示的是 Miss Rate 的分布情况。可以看到,当 Miss 率较高时,2-random 表现更稳定,而传统 LRU 则波动较大。
Pseudo-LRU 太重?试试 Pseudo-2-random!
在真实芯片中,完全精确的 LRU 实现代价不小,因此很多系统采用近似策略:Pseudo-LRU。
同样道理,我们也可以构造 Pseudo-2-random(模拟实现 80% 准确率的 2-random)。测试如下:
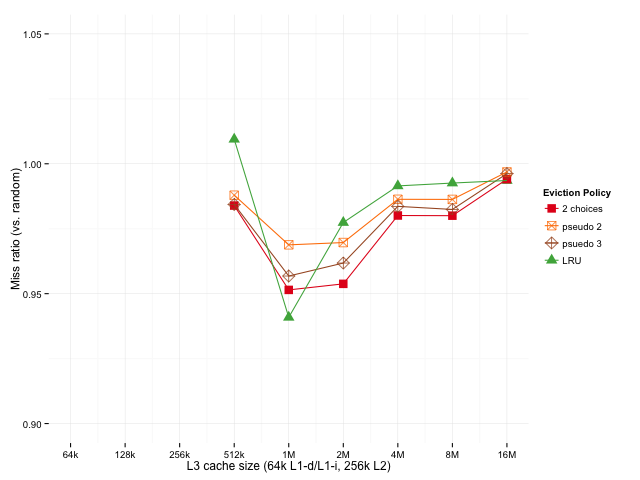
- Pseudo 2-random:略逊于精确 2-random,但远好于 Random 和 FIFO;
- Pseudo 3-random(从三个随机中挑最久未使用者):接近精确 2-random 的性能,且优于传统 LRU,尤其在大缓存下优势明显。
替换策略性能还受关联度影响
缓存的**组关联度(Set Associativity)**也会影响替换策略的效果:
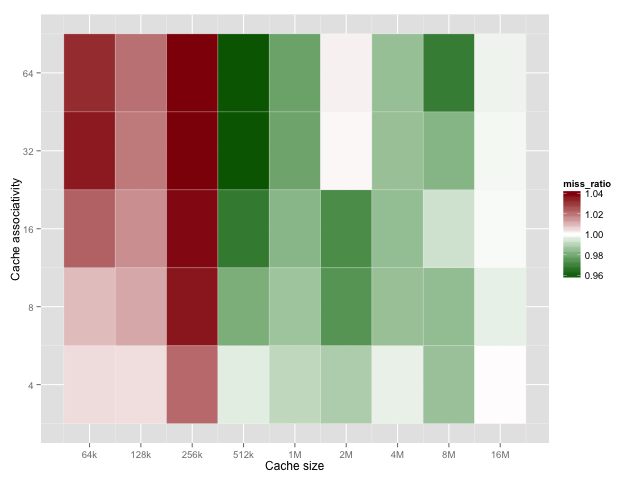
结论依旧一致:
- 小缓存:LRU 更优;
- 大缓存:2-random 更强;
- 关联度越高,策略间差距越大;
策略混搭是否更优?
虽然本文测试中未做混合策略模拟,但从趋势来看:在 L1、L2 使用 LRU,L3 使用 2-random,可能是当前硬件环境下的最优组合。
这一策略不止适用于 CPU 缓存,对于数据库、CDN、分布式缓存等系统同样具有参考价值。
数学原理:为什么“两个随机选择”这么强?
这个问题早有研究结论。《The Power of Two Random Choices》一文中指出:
- 将 n 个球随机分配到 n 个桶中,最大负载为
O(log n / log log n) - 但若每次随机挑两个桶,把球放到负载较小的那个,最大负载变成
O(log log n) - 效率提升惊人,只需额外一个判断
简单改动,巨大收益!
参考链接:The Power of Two Random Choices PDF
总结
- LRU 仍是缓存替换策略中的王者,但不是万能;
- 2-random 在大缓存、高 miss 场景下拥有明显优势;
- 简单实现的 Pseudo 2/3-random 足以媲美甚至超越传统策略;
- 这类算法,已在缓存、负载均衡、哈希、路由等领域大放异彩。
在“缓存无处不在”的时代,从移动端到大模型推理系统,这种简单却强大的策略,值得每一位开发者了解和尝试!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号