
源码分析 | ClickHouse和他的朋友们(12)神奇的物化视图(Materialized View)与原理
本文首发于 2020-09-03 21:22:14
《ClickHouse和他的朋友们》系列文章转载自圈内好友 BohuTANG 的博客,原文链接:
https://bohutang.me/2020/08/31/clickhouse-and-friends-materialized-view/
以下为正文。
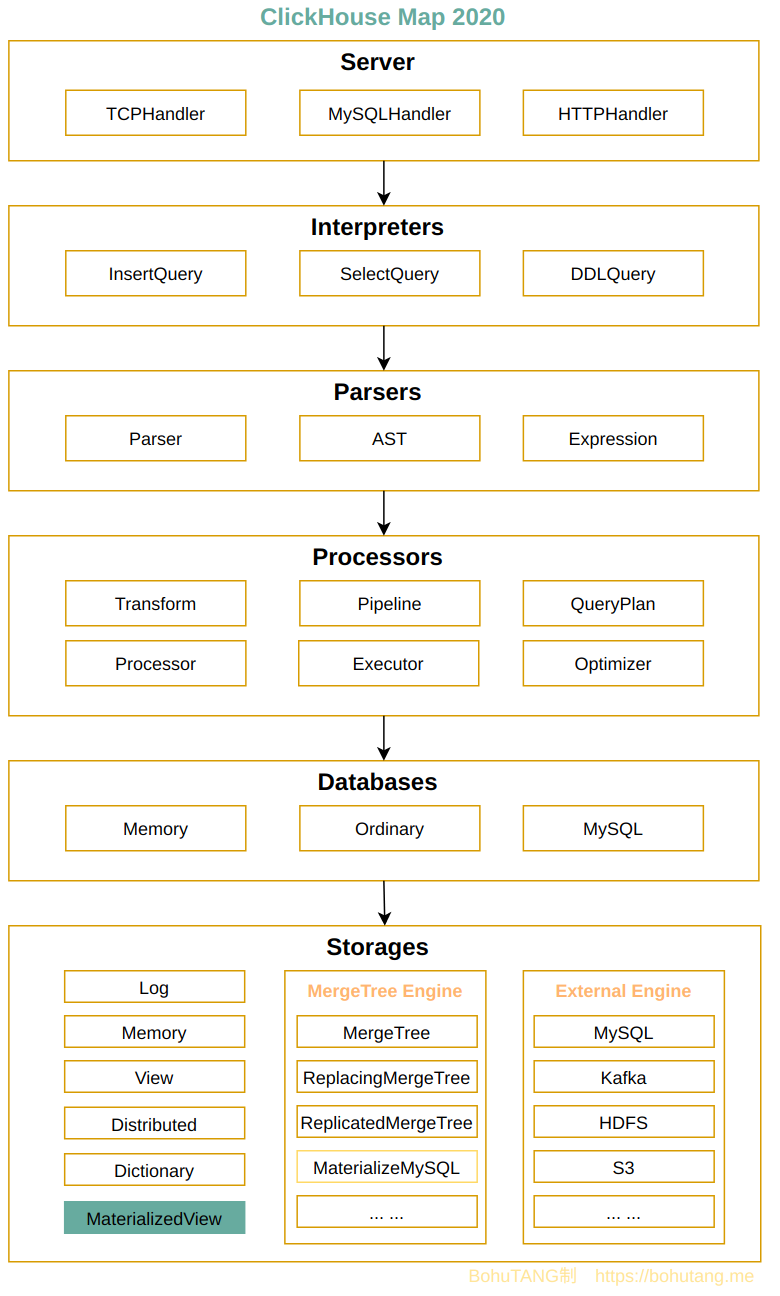
在 ClickHouse 里,物化视图(Materialized View)可以说是一个神奇且强大的东西,用途别具一格。
本文从底层机制进行分析,看看 ClickHouse 的 Materalized View 是怎么工作的,以方便更好的使用它。
什么是物化视图
对大部分人来说,物化视图这个概念会比较抽象,物化?视图?。。。
为了更好的理解它,我们先看一个场景。
假设你是 *hub 一个“幸福”的小程序员,某天产品经理有个需求:实时统计每小时视频下载量。
用户下载明细表:
clickhouse> SELECT * FROM download LIMIT 10;
+---------------------+--------+--------+
| when | userid | bytes |
+---------------------+--------+--------+
| 2020-08-31 18:22:06 | 19 | 530314 |
| 2020-08-31 18:22:06 | 19 | 872957 |
| 2020-08-31 18:22:06 | 19 | 107047 |
| 2020-08-31 18:22:07 | 19 | 214876 |
| 2020-08-31 18:22:07 | 19 | 820943 |
| 2020-08-31 18:22:07 | 19 | 693959 |
| 2020-08-31 18:22:08 | 19 | 882151 |
| 2020-08-31 18:22:08 | 19 | 644223 |
| 2020-08-31 18:22:08 | 19 | 199800 |
| 2020-08-31 18:22:09 | 19 | 511439 |
... ....
计算每小时下载量:
clickhouse> SELECT toStartOfHour(when) AS hour, userid, count() as downloads, sum(bytes) AS bytes FROM download GROUP BY userid, hour ORDER BY userid, hour;
+---------------------+--------+-----------+------------+
| hour | userid | downloads | bytes |
+---------------------+--------+-----------+------------+
| 2020-08-31 18:00:00 | 19 | 6822 | 3378623036 |
| 2020-08-31 19:00:00 | 19 | 10800 | 5424173178 |
| 2020-08-31 20:00:00 | 19 | 10800 | 5418656068 |
| 2020-08-31 21:00:00 | 19 | 10800 | 5404309443 |
| 2020-08-31 22:00:00 | 19 | 10800 | 5354077456 |
| 2020-08-31 23:00:00 | 19 | 10800 | 5390852563 |
| 2020-09-01 00:00:00 | 19 | 10800 | 5369839540 |
| 2020-09-01 01:00:00 | 19 | 10800 | 5384161012 |
| 2020-09-01 02:00:00 | 19 | 10800 | 5404581759 |
| 2020-09-01 03:00:00 | 19 | 6778 | 3399557322 |
+---------------------+--------+-----------+------------+
10 rows in set (0.13 sec)
很容易嘛,不过有个问题:每次都要以 download 表为基础数据进行计算,*hub 数据量太大,无法忍受。
想到一个办法:如果对 download 进行预聚合,把结果保存到一个新表 download_hour_mv,并随着 download 增量实时更新,每次去查询download_hour_mv 不就可以了。
这个新表可以看做是一个物化视图,它在 ClickHouse 是一个普通表。
创建物化视图
clickhouse> CREATE MATERIALIZED VIEW download_hour_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(hour) ORDER BY (userid, hour)
AS SELECT
toStartOfHour(when) AS hour,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download WHERE when >= toDateTime('2020-09-01 04:00:00')
GROUP BY userid, hour
这个语句主要做了:
- 创建一个引擎为
SummingMergeTree的物化视图download_hour_mv - 物化视图的数据来源于
download表,并根据select语句中的表达式进行相应“物化”操作 - 选取一个未来时间(当前时间是
2020-08-31 18:00:00)作为开始点WHERE when >= toDateTime('2020-09-01 04:00:00'),表示在2020-09-01 04:00:00之后的数据才会被同步到download_hour_mv
这样,目前 download_hour_mv 是一个空表:
clickhouse> SELECT * FROM download_hour_mv ORDER BY userid, hour;
Empty set (0.02 sec)
注意:官方有 POPULATE 关键字,但是不建议使用,因为视图创建期间 download 如果有写入数据会丢失,这也是我们加一个 WHERE 作为数据同步点的原因。
那么,我们如何让源表数据可以一致性的同步到 download_hour_mv 呢?
物化全量数据
在2020-09-01 04:00:00之后,我们可以通过一个带 WHERE 快照的INSERT INTO SELECT... 对 download 历史数据进行物化:
clickhouse> INSERT INTO download_hour_mv
SELECT
toStartOfHour(when) AS hour,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download WHERE when < toDateTime('2020-09-01 04:00:00')
GROUP BY userid, hour
查询物化视图:
clickhouse> SELECT * FROM download_hour_mv ORDER BY hour, userid, downloads DESC;
+---------------------+--------+-----------+------------+
| hour | userid | downloads | bytes |
+---------------------+--------+-----------+------------+
| 2020-08-31 18:00:00 | 19 | 6822 | 3378623036 |
| 2020-08-31 19:00:00 | 19 | 10800 | 5424173178 |
| 2020-08-31 20:00:00 | 19 | 10800 | 5418656068 |
| 2020-08-31 21:00:00 | 19 | 10800 | 5404309443 |
| 2020-08-31 22:00:00 | 19 | 10800 | 5354077456 |
| 2020-08-31 23:00:00 | 19 | 10800 | 5390852563 |
| 2020-09-01 00:00:00 | 19 | 10800 | 5369839540 |
| 2020-09-01 01:00:00 | 19 | 10800 | 5384161012 |
| 2020-09-01 02:00:00 | 19 | 10800 | 5404581759 |
| 2020-09-01 03:00:00 | 19 | 6778 | 3399557322 |
+---------------------+--------+-----------+------------+
10 rows in set (0.05 sec)
可以看到数据已经“物化”到 download_hour_mv。
物化增量数据
写一些数据到 download表:
clickhouse> INSERT INTO download
SELECT
toDateTime('2020-09-01 04:00:00') + number*(1/3) as when,
19,
rand() % 1000000
FROM system.numbers
LIMIT 10;
查询物化视图 download_hour_mv:
clickhouse> SELECT * FROM download_hour_mv ORDER BY hour, userid, downloads;
+---------------------+--------+-----------+------------+
| hour | userid | downloads | bytes |
+---------------------+--------+-----------+------------+
| 2020-08-31 18:00:00 | 19 | 6822 | 3378623036 |
| 2020-08-31 19:00:00 | 19 | 10800 | 5424173178 |
| 2020-08-31 20:00:00 | 19 | 10800 | 5418656068 |
| 2020-08-31 21:00:00 | 19 | 10800 | 5404309443 |
| 2020-08-31 22:00:00 | 19 | 10800 | 5354077456 |
| 2020-08-31 23:00:00 | 19 | 10800 | 5390852563 |
| 2020-09-01 00:00:00 | 19 | 10800 | 5369839540 |
| 2020-09-01 01:00:00 | 19 | 10800 | 5384161012 |
| 2020-09-01 02:00:00 | 19 | 10800 | 5404581759 |
| 2020-09-01 03:00:00 | 19 | 6778 | 3399557322 |
| 2020-09-01 04:00:00 | 19 | 10 | 5732600 |
+---------------------+--------+-----------+------------+
11 rows in set (0.00 sec)
可以看到最后一条数据就是我们增量的一个物化聚合,已经实时同步,这是如何做到的呢?
物化视图原理
ClickHouse 的物化视图原理并不复杂,在 download 表有新的数据写入时,如果检测到有物化视图跟它关联,会针对这批写入的数据进行物化操作。
比如上面新增数据是通过以下 SQL 生成的:
clickhouse> SELECT
-> toDateTime('2020-09-01 04:00:00') + number*(1/3) as when,
-> 19,
-> rand() % 1000000
-> FROM system.numbers
-> LIMIT 10;
+---------------------+------+-------------------------+
| when | 19 | modulo(rand(), 1000000) |
+---------------------+------+-------------------------+
| 2020-09-01 04:00:00 | 19 | 870495 |
| 2020-09-01 04:00:00 | 19 | 322270 |
| 2020-09-01 04:00:00 | 19 | 983422 |
| 2020-09-01 04:00:01 | 19 | 759708 |
| 2020-09-01 04:00:01 | 19 | 975636 |
| 2020-09-01 04:00:01 | 19 | 365507 |
| 2020-09-01 04:00:02 | 19 | 865569 |
| 2020-09-01 04:00:02 | 19 | 975742 |
| 2020-09-01 04:00:02 | 19 | 85827 |
| 2020-09-01 04:00:03 | 19 | 992779 |
+---------------------+------+-------------------------+
10 rows in set (0.02 sec)
物化视图执行的语句类似:
INSERT INTO download_hour_mv
SELECT
toStartOfHour(when) AS hour,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM [新增的10条数据] WHERE when >= toDateTime('2020-09-01 04:00:00')
GROUP BY userid, hour
代码导航:
-
添加视图 OutputStream, InterpreterInsertQuery.cpp
if (table->noPushingToViews() && !no_destination) out = table->write(query_ptr, metadata_snapshot, context); else out = std::make_shared<PushingToViewsBlockOutputStream>(table, metadata_snapshot, context, query_ptr, no_destination); -
构造 Insert , PushingToViewsBlockOutputStream.cpp
ASTPtr insert_query_ptr(insert.release()); InterpreterInsertQuery interpreter(insert_query_ptr, *insert_context); BlockIO io = interpreter.execute(); out = io.out;
Context local_context = *select_context;
local_context.addViewSource(
StorageValues::create(
storage->getStorageID(), metadata_snapshot->getColumns(), block, storage->getVirtuals()));
select.emplace(view.query, local_context, SelectQueryOptions());
in = std::make_shared<MaterializingBlockInputStream>(select->execute().getInputStream()
总结
物化视图的用途较多。
比如可以解决表索引问题,我们可以用物化视图创建另外一种物理序,来满足某些条件下的查询问题。
还有就是通过物化视图的实时同步数据能力,我们可以做到更加灵活的表结构变更。
更强大的地方是它可以借助 MergeTree 家族引擎(SummingMergeTree、Aggregatingmergetree等),得到一个实时的预聚合,满足快速查询。
原理是把增量的数据根据 AS SELECT ... 对其进行处理并写入到物化视图表,物化视图是一种普通表,可以直接读取和写入。
欢迎关注我的微信公众号【数据库内核】:分享主流开源数据库和存储引擎相关技术。

| 标题 | 网址 |
|---|---|
| GitHub | https://dbkernel.github.io |
| 知乎 | https://www.zhihu.com/people/dbkernel/posts |
| 思否(SegmentFault) | https://segmentfault.com/u/dbkernel |
| 掘金 | https://juejin.im/user/5e9d3ed251882538083fed1f/posts |
| 开源中国(oschina) | https://my.oschina.net/dbkernel |
| 博客园(cnblogs) | https://www.cnblogs.com/dbkernel |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号