MySQL 8 的哈希连接
什么是哈希连接
哈希连接是一种执行连接的方法,使用哈希表在两个输入之间找到匹配的行(输入可以是一个或多个表)。
它通常比嵌套循环连接更高效,特别是当其中一个输入可以放在在内存中时。为了了解它是如何工作的,将使用以下查询作为示例:
|
1
2
3
4
|
SELECT given_name, country_nameFROM persons JOIN countries ON persons.country_id = countries.country_id; |
哈希连接通常分为两个阶段;哈希构建阶段和哈希探测阶段。
构建阶段
在构建阶段,构建一个内存中的哈希表,将其中一个输入的行存储在内存中,使用连接属性作为哈希表的键。这个输入也被称为构建输入,假设我们将 'countries' 指定为构建输入。
理想情况下,将选择两个输入中较小的一个作为构建输入(以字节为单位,而不是以行数为单位)。由于 'countries.country_id' 是属于构建输入的连接条件,因此它作为哈希表中的键。一旦所有行都已存储在哈希表中,构建阶段就完成了。

探测阶段
在探测阶段,开始从探测输入(在我们的例子中是 "persons")读取行。对于读取的每一行,使用 'persons.country_id' 的值作为查找键在哈希表中探测匹配的行。
对于每一个匹配,mysql 将连接后的一行发送给客户端。最终,mysql 只扫描了一次每个输入,在两个输入之间找到匹配的行使用的是常量时间。

这样做非常有效,因为可以将整个构建输入存储在内存中。可用的内存量由系统变量 join_buffer_size 控制,并可以在运行时进行调整。但是,如果构建输入大于可用内存怎么办?那将会溢出到磁盘!
溢出到磁盘
当内存在构建阶段爆满时,服务器会将其余的构建输入写入磁盘上的若干块(chunks)文件。服务器会尝试设置块数,最大限度的使得块正好适合内存,但 MySQL 有一个硬性上限,即每个输入最大可以有 128 个块文件。通过计算连接属性的哈希值,可以确定将记录写入哪个块文件。请注意,插图中使用的哈希函数与内存构建阶段使用的哈希函数不同。稍后会看到原因。
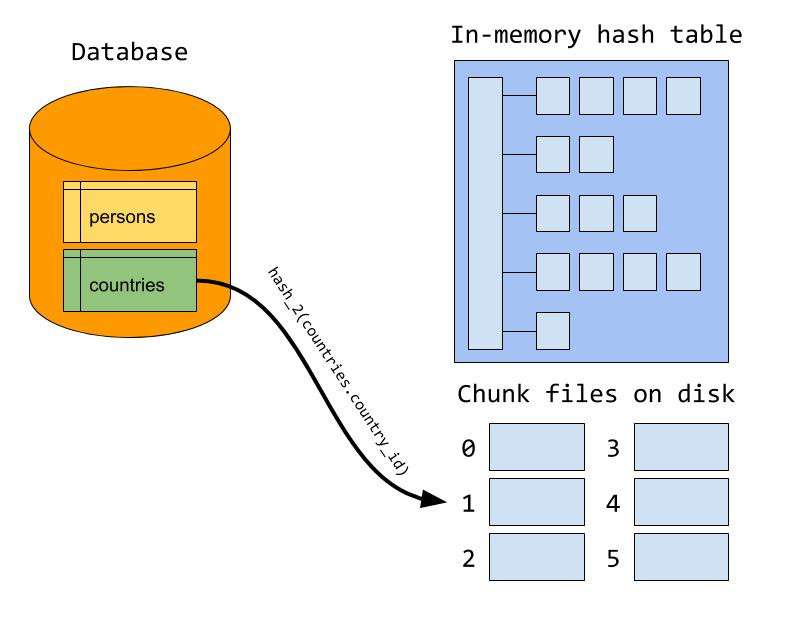
在探测阶段,会探测哈希表中是否有匹配的行,就像所有内容都在内存中一样。但除此之外,一行也可能与写入磁盘的构建输入中的一行相匹配。因此,探针输入中的每一行也会被写入一组块文件。我们使用与将构建输入写入磁盘时相同的哈希函数和公式来确定将某一行写入哪个块文件。这样,我们就能确定两个输入之间的匹配行将位于同一对块文件中。

探测阶段结束后,我们开始从磁盘读取块文件。一般来说,会使用第一组块文件作为构建和探测输入,进行构建和探测阶段。我们会将构建输入中的第一个块文件加载到内存哈希表中。这就解释了为什么我们希望最大的数据块能完全装入内存;如果数据块文件太大,我们就需要将其分割成更小的数据块。加载构建的块后,我们会从探测输入中读取相应的块文件,并在哈希表中寻找匹配的文件,就像所有文件都装入内存一样。当处理完第一对块文件后,我们就开始处理下一对块文件,直到处理完所有对块文件。

你现在可能已经猜到,为什么在将数据行分割成块文件和将数据行写入哈希表时要使用两种不同的哈希函数了。如果在这两种操作中使用相同的哈希函数,那么在将构建的块文件加载到哈希表时,我们就会得到一个极其糟糕的哈希表,因为同一块文件中的所有行都会哈希列为相同的值。
哈希连接优化
缺省情况下,mysql 在可能的情况下使用哈希连接。可以使用优化器的hint:BNL 和 NO_BNL,或通过设置 block_nested_loop=on 或 block_nested_loop=off 作为optimizer_switch系统变量设置的一部分,来控制是否采用哈希连接。
对于查询中每个表都是等值连接条件的任何查询,而且没有索引可应用于任何连接条件,MySQL 都会使用哈希连接。比如下面的查询:
|
1
2
3
4
|
SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1; |
当有一个或多个索引可用于单表谓词时,也可以使用哈希连接。
假设使用以下语句创建了三个表 t1、t2 和 t3:
|
1
2
3
|
CREATE TABLE t1 (c1 INT, c2 INT);CREATE TABLE t2 (c1 INT, c2 INT);CREATE TABLE t3 (c1 INT, c2 INT); |
借助EXPLAIN命令,就可以看到使用了哈希连接:
|
1
2
3
4
5
6
7
|
>explain select * from t1 join t2 on t1.c1=t2.c1;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL || 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (hash join) |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ |
对于多个连接的查询,只要有一个连接的两个表使用了等值查询,也可以使用哈希连接。比如:
|
1
2
3
|
SELECT * FROM t1 JOIN t2 ON (t1.c1 = t2.c1 AND t1.c2 < t2.c2) JOIN t3 ON (t2.c1 = t3.c1); |
像上面展示的这种情况中,它使用了内连接,任何不等连接的额外条件会在连接执行后作为过滤器应用(对于外连接,例如左连接、半连接和反连接,它们作为连接的一部分被打印出来)。这可以在以下EXPLAIN的输出中看到:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> EXPLAIN FORMAT=TREE -> SELECT * -> FROM t1 -> JOIN t2 -> ON (t1.c1 = t2.c1 AND t1.c2 < t2.c2) -> JOIN t3 -> ON (t2.c1 = t3.c1)\G*************************** 1. row ***************************EXPLAIN: -> Inner hash join (t3.c1 = t1.c1) (cost=1.05 rows=1) -> Table scan on t3 (cost=0.35 rows=1) -> Hash -> Filter: (t1.c2 < t2.c2) (cost=0.70 rows=1) -> Inner hash join (t2.c1 = t1.c1) (cost=0.70 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Table scan on t1 (cost=0.35 rows=1) |
还可以看到,这里使用了多个哈希连接。
即使任何一对连接的表都不满足至少一个等值连接条件,仍然会使用哈希连接,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
>EXPLAIN FORMAT=TREE -> SELECT * FROM t1 -> JOIN t2 ON (t1.c1 < t2.c1) -> JOIN t3 ON (t2.c1 < t3.c1)\G*************************** 1. row ***************************EXPLAIN: -> Filter: (t2.c1 < t3.c1) (cost=1.05 rows=1) -> Inner hash join (no condition) (cost=1.05 rows=1) -> Table scan on t3 (cost=0.35 rows=1) -> Hash -> Filter: (t1.c1 < t2.c1) (cost=0.7 rows=1) -> Inner hash join (no condition) (cost=0.7 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Table scan on t1 (cost=0.35 rows=1) |
哈希连接也适用于笛卡尔积——即当未指定连接条件时,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
|
>EXPLAIN FORMAT=TREE -> SELECT * -> FROM t1 -> JOIN t2 -> WHERE t1.c2 > 50\G*************************** 1. row ***************************EXPLAIN: -> Inner hash join (no condition) (cost=0.7 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Filter: (t1.c2 > 50) (cost=0.35 rows=1) -> Table scan on t1 (cost=0.35 rows=1) |
哈希连接不必是至少含有一个等值连接条件。这意味着可以使用哈希连接来优化的查询类型包括以下列表中的那些:
1.inner non-equi-join
|
1
2
3
4
5
6
7
|
>EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 < t2.c1\G*************************** 1. row ***************************EXPLAIN: -> Filter: (t1.c1 < t2.c1) (cost=0.7 rows=1) -> Inner hash join (no condition) (cost=0.7 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Table scan on t1 (cost=0.35 rows=1) |
2.semijoin
|
1
2
3
4
5
6
|
>EXPLAIN FORMAT=TREE SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c2 FROM t2)\G*************************** 1. row ***************************EXPLAIN: -> Hash semijoin (t2.c2 = t1.c1) (cost=0.7 rows=1) -> Table scan on t1 (cost=0.35 rows=1) -> Hash -> Table scan on t2 (cost=0.35 rows=1) |
3.antijoin
|
1
2
3
4
5
6
|
>EXPLAIN FORMAT=TREE SELECT * FROM t2 WHERE NOT EXISTS (SELECT * FROM t1 WHERE t1.c1 = t2.c1)\G*************************** 1. row ***************************EXPLAIN: -> Hash antijoin (t1.c1 = t2.c1) (cost=0.7 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Table scan on t1 (cost=0.35 rows=1) |
4.left outer join:
|
1
2
3
4
5
6
|
>EXPLAIN FORMAT=TREE SELECT * FROM t1 LEFT JOIN t2 ON t1.c1 = t2.c1\G*************************** 1. row ***************************EXPLAIN: -> Left hash join (t2.c1 = t1.c1) (cost=0.7 rows=1) -> Table scan on t1 (cost=0.35 rows=1) -> Hash -> Table scan on t2 (cost=0.35 rows=1) |
5.right outer join:
|
1
2
3
4
5
6
|
>EXPLAIN FORMAT=TREE SELECT * FROM t1 RIGHT JOIN t2 ON t1.c1 = t2.c1\G*************************** 1. row ***************************EXPLAIN: -> Left hash join (t1.c1 = t2.c1) (cost=0.7 rows=1) -> Table scan on t2 (cost=0.35 rows=1) -> Hash -> Table scan on t1 (cost=0.35 rows=1) |
可以通过使用 join_buffer_size 系统变量来控制哈希连接的内存使用;哈希连接不能使用超过此数量的内存。当哈希连接所需的内存超过可用的数量时,MySQL 通过使用磁盘上的文件来处理这种情况。
如果发生这种情况,用户应该注意,如果内存无法满足哈希连接并且创建的文件数量超过 open_files_limit 设置的限制,则连接查询可能会不成功。为避免此类问题,请采用以下某项修改:
·增加 join_buffer_size,以便哈希连接不会溢出到磁盘。
·增加 open_files_limit。
哈希连接的 join buffer 是逐渐分配的;因此,可以将 join_buffer_size 设置得更高,而小查询不会分配非常大的 join buffer 内存,虽然外连接会分配 join buffer 。但是哈希连接也用于外连接(包括反连接和半连接),因此这不再是一个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号