机器学习进度01(sklearn、字典特征抽取、文本特征抽取(CountVectorizer、TfidfVevtorizer)、中文文本特征抽取)
sklearn数据集
1 scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
2 sklearn小数据集
-
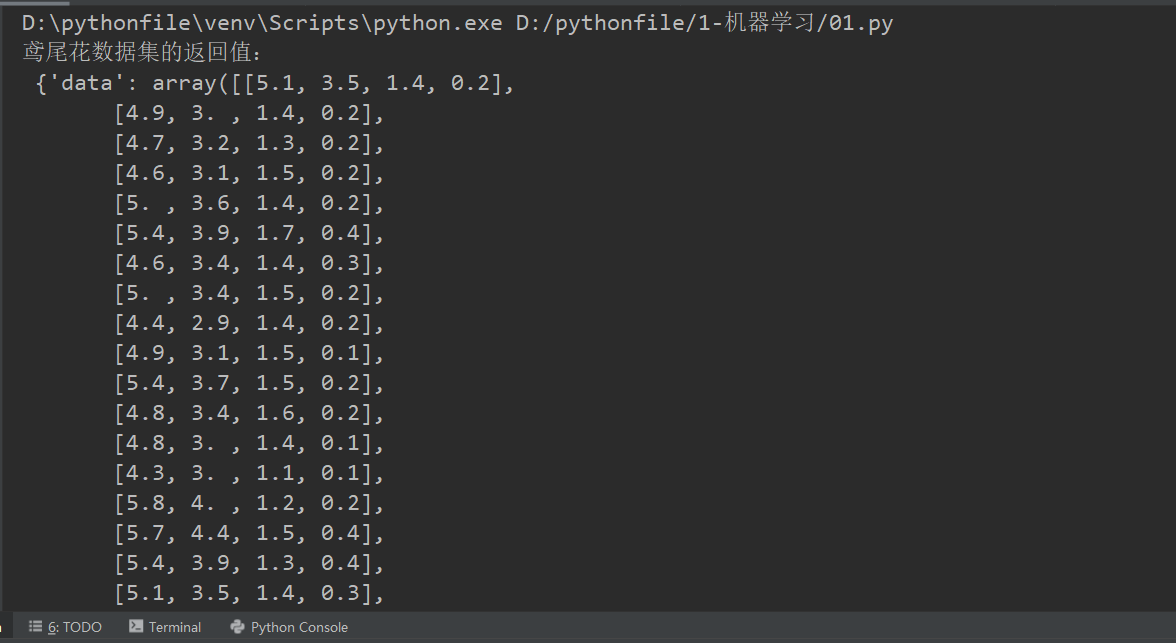
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
-
sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
3 sklearn大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4 sklearn数据集的使用
-
以鸢尾花数据集为例:
sklearn数据集返回值介绍
- load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
from sklearn.datasets import load_iris def datasets_demo(): # 获取鸢尾花数据集 iris = load_iris() print("鸢尾花数据集的返回值:\n", iris) # 返回值是一个继承自字典的Bench print("鸢尾花的特征值:\n", iris["data"]) print("鸢尾花的目标值:\n", iris.target) print("鸢尾花特征的名字:\n", iris.feature_names) print("鸢尾花目标值的名字:\n", iris.target_names) print("鸢尾花的描述:\n", iris.DESCR) if __name__=="__main__": datasets_demo()
数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
数据集划分api
- sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
# 获取鸢尾花数据集
iris = load_iris()
#print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
#print("鸢尾花的特征值:\n", iris["data"])
#print("鸢尾花的目标值:\n", iris.target)
#print("鸢尾花特征的名字:\n", iris.feature_names)
#print("鸢尾花目标值的名字:\n", iris.target_names)
#print("鸢尾花的描述:\n", iris.DESCR)
#进行数据及的划分
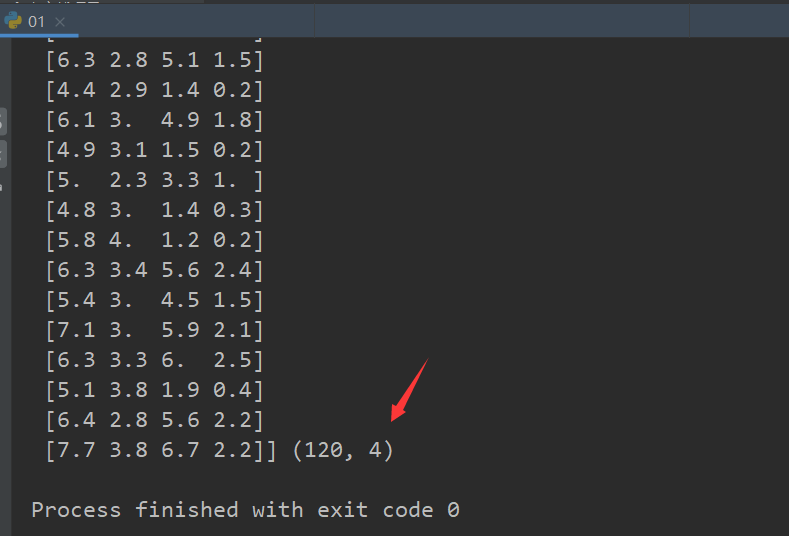
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
#test_size默认是0.25,random_state表示随机数种子
print("训练集得特征值 :\n",x_train,x_train.shape)#x_train.shape看x_train有多少行多少咧
#随机种子一种之后所有的项都是true
if __name__=="__main__":
datasets_demo()
字典特征抽取:
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
- pandas:一个数据读取非常方便以及基本的处理格式的工具
- sklearn:对于特征的处理提供了强大的接口
特征抽取的目标:
- 应用DictVectorizer实现对类别特征进行数值化、离散化
- 应用CountVectorizer实现对文本特征进行数值化
- 应用TfidfVectorizer实现对文本特征进行数值化
- 说出两种文本特征提取的方式区别
特征提取API
sklearn.feature_extraction作用:对字典数据进行特征值化
- sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩阵
- DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格式
- DictVectorizer.get_feature_names() 返回类别名称
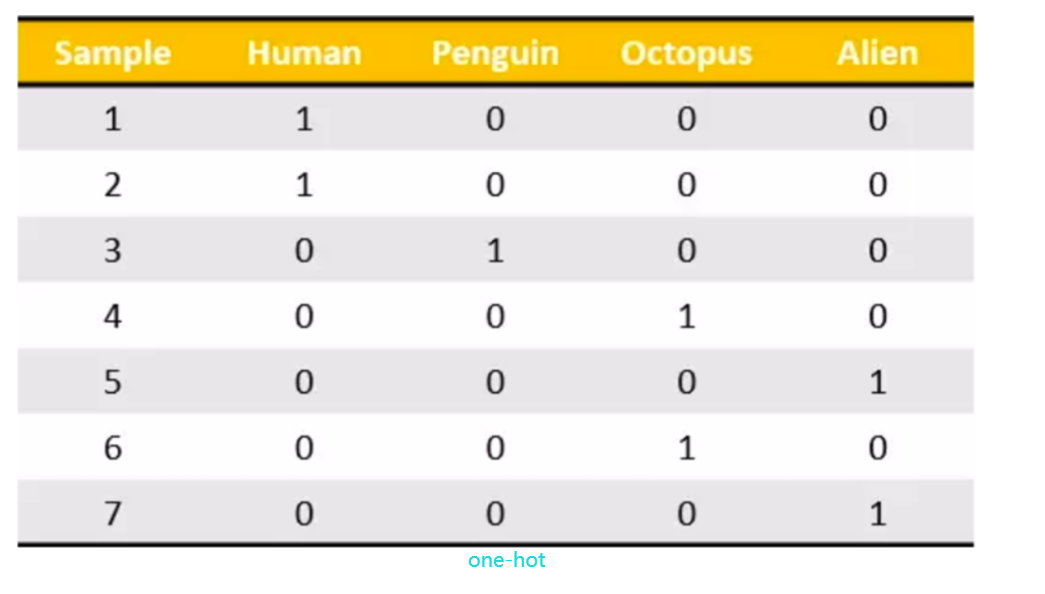
对于特征当中存在类别信息的我们都会做one-hot编码处理
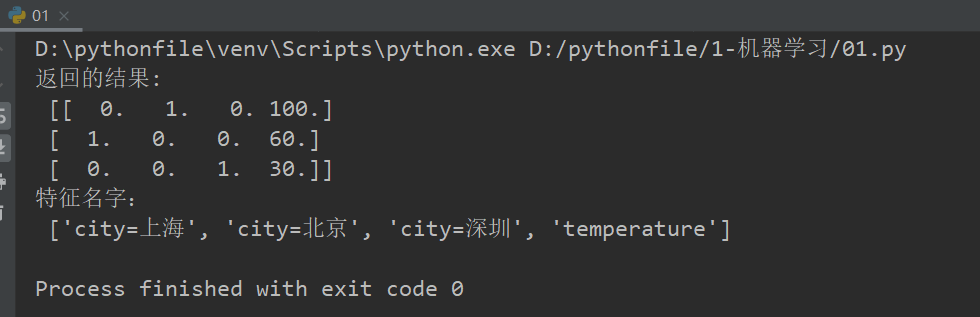
#字典特征提取 def dict_demo(): """ 对字典类型的数据进行特征抽取 :return: None """ data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}] # 1、实例化一个转换器类 transfer = DictVectorizer(sparse=False) # 2、调用fit_transform data = transfer.fit_transform(data) print("返回的结果:\n", data) # 打印特征名字 print("特征名字:\n", transfer.get_feature_names()) return None if __name__=="__main__": dict_demo()
文本特征提取CountVectorizer:
作用:对文本数据进行特征值化
-
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- 返回词频矩阵
- CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象 返回值:返回sparse矩阵
- CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格
- CountVectorizer.get_feature_names() 返回值:单词列表
- sklearn.feature_extraction.text.TfidfVectorizer#文本特征提取
def text_count_demo(): """ 对文本进行特征抽取,countvetorizer :return: None """ data = ["life is short,i like like python", "life is too long,i dislike python"] # 1、实例化一个转换器类 transfer = CountVectorizer()
#transfer = CountVectorizer(stop_words=["is","too"])#设置停用词表,这样就不管这些单词了
# 2、调用fit_transform data = transfer.fit_transform(data) #统计的是单词出现的个数 print("文本特征抽取的结果:\n", data.toarray())#采用toarray()进行展示 print("返回特征名字:\n", transfer.get_feature_names()) return None if __name__=="__main__": text_count_demo()
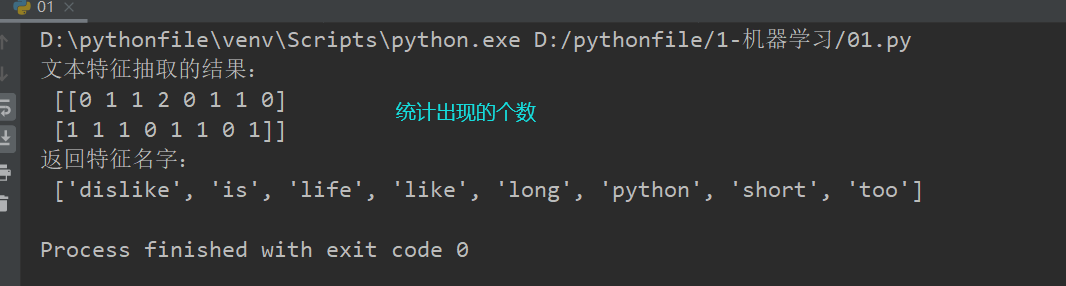
中文文本特征提取:
简单(手动分开一个句子)。
#中文文本特征提取 def count_chinese_demo(): """ 对中文文本进行特征抽取, :return: None """ data = ["人生 苦短,我 喜欢 Python","生活 太长久,我不 喜欢 Python"] # 1、实例化一个转换器类 transfer = CountVectorizer() # 2、调用fit_transform data = transfer.fit_transform(data) #统计的是单词出现的个数 print("文本特征抽取的结果:\n", data.toarray())#采用toarray()进行展示 print("返回特征名字:\n", transfer.get_feature_names()) return None if __name__=="__main__": count_chinese_demo()
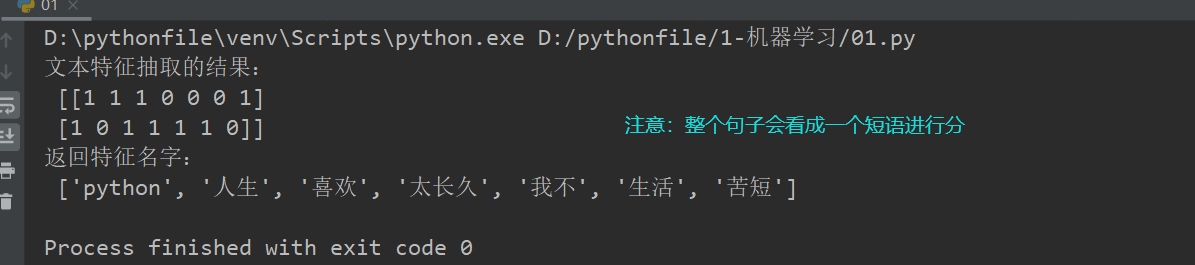
jieba自动分词:
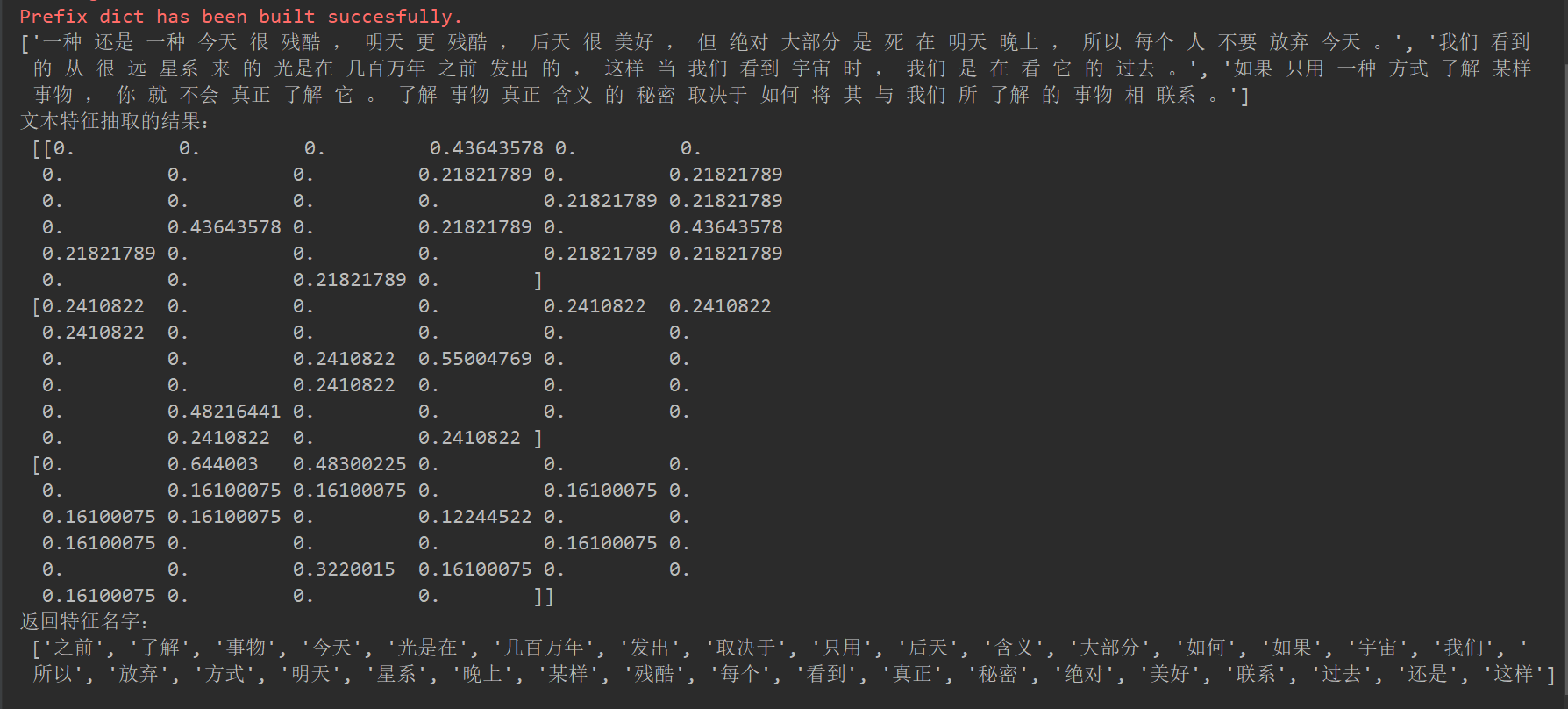
#jieba分词 def cut_word(text): """ 对中文进行分词 "我爱北京天安门"————>"我 爱 北京 天安门" :param text: :return: text """ # 用结巴对中文字符串进行分词 text = " ".join(list(jieba.cut(text)))#用list将他强转一下使用“ ”.json就会将他变成字符串 return text #中文文本特征提取jieba分词 def count_chinese_demo2(): """ 对中文进行特征抽取 :return: None """ data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。", "我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。", "如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"] # 将原始数据转换成分好词的形式 text_list = [] for sent in data: text_list.append(cut_word(sent)) print(text_list) # 1、实例化一个转换器类 transfer = CountVectorizer() # 2、调用fit_transform data = transfer.fit_transform(text_list) print("文本特征抽取的结果:\n", data.toarray()) print("返回特征名字:\n", transfer.get_feature_names()) return None if __name__=="__main__": count_chinese_demo2()
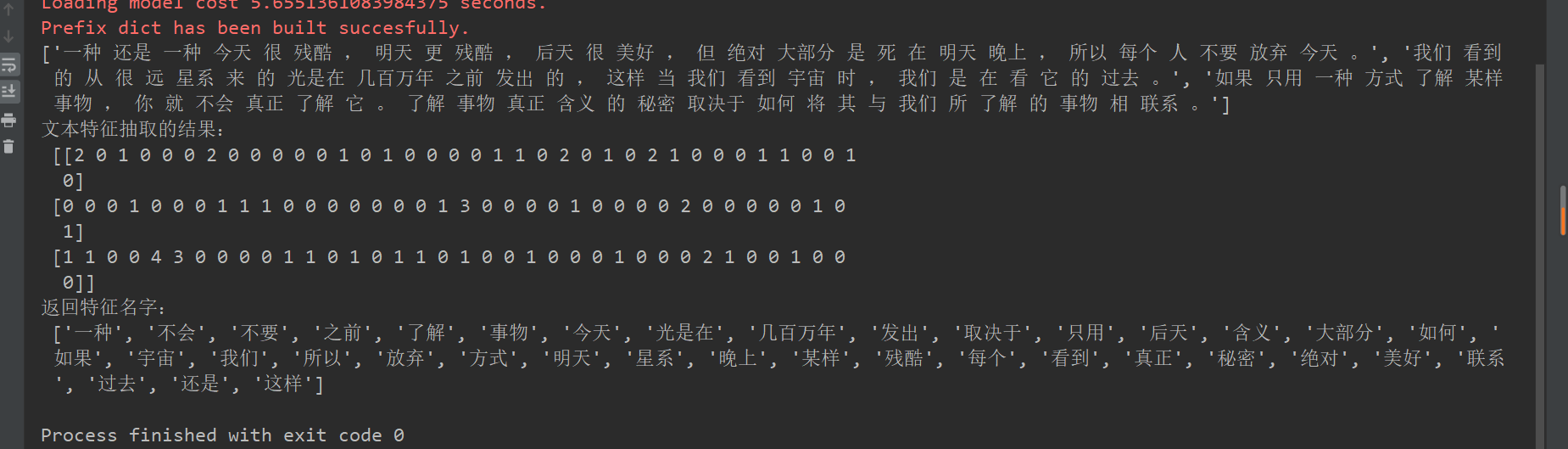
文本特征提取TfidfVevtorizer:
其衡量的是一个单词的重要程度。
-
TF-IDF的主要思想是:
- 如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
-
TF-IDF作用:
- 用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
公式
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
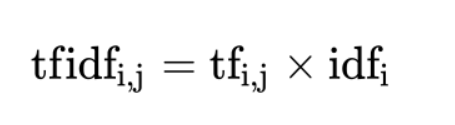

#文本特征提取tfidf def text_chinese_tfidf_demo(): """ 对文本进行特征抽取-tfidf :return: None """ data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。", "我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。", "如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"] # 将原始数据转换成分好词的形式 text_list = [] for sent in data: text_list.append(cut_word(sent)) print(text_list) # 1、实例化一个转换器类 transfer = TfidfVectorizer(stop_words=['一种', '不会', '不要']) # 2、调用fit_transform data = transfer.fit_transform(text_list) print("文本特征抽取的结果:\n", data.toarray()) print("返回特征名字:\n", transfer.get_feature_names()) return None if __name__=="__main__": text_chinese_tfidf_demo()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号