spark学习进度28(SparkStreaming)
SparkStreaming

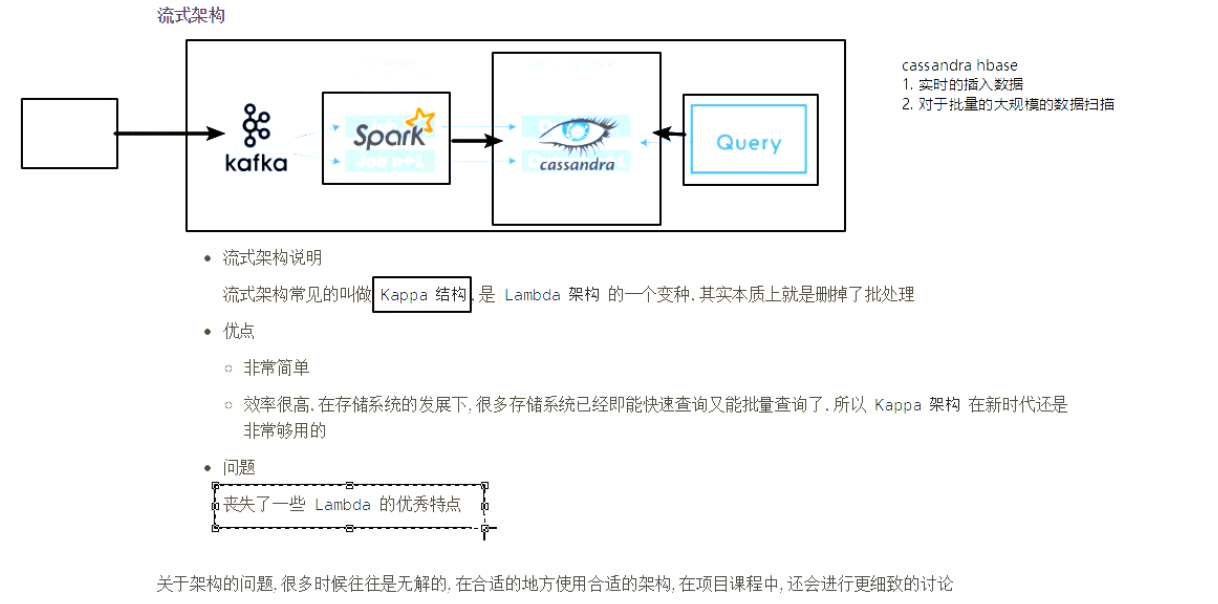
Spark Streaming 的特点
Netcat 的使用

Step 1: Socket 回顾
-

-
Socket是Java中为了支持基于TCP / UDP协议的通信所提供的编程模型 -
Socket分为Socket server和Socket clientSocket server-
监听某个端口, 接收
Socket client发过来的连接请求建立连接, 连接建立后可以向Socket client发送TCP packet交互 (被动) Socket client-
向某个端口发起连接, 并在连接建立后, 向
Socket server发送TCP packet实现交互 (主动)
-
TCP三次握手建立连接Step 1-
Client向Server发送SYN(j), 进入SYN_SEND状态等待Server响应 Step 2-
Server收到Client的SYN(j)并发送确认包ACK(j + 1), 同时自己也发送一个请求连接的SYN(k)给Client, 进入SYN_RECV状态等待Client确认 Step 3-
Client收到Server的ACK + SYN, 向Server发送连接确认ACK(k + 1), 此时,Client和Server都进入ESTABLISHED状态, 准备数据发送
-
Step 2: Netcat
-

-
Netcat简写nc, 命令行中使用nc命令调用 -
Netcat是一个非常常见的Socket工具, 可以使用nc建立Socket server也可以建立Socket client-
nc -l建立Socket server,l是listen监听的意思 -
nc host port建立Socket client, 并连接到某个Socket server
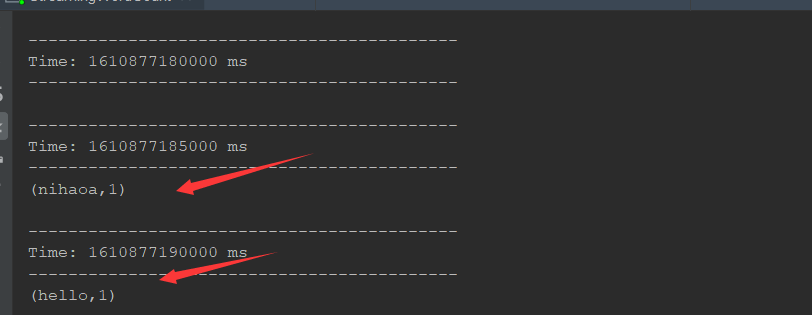
流的演示:
package cn.itcast.streaming import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object StreamingWordCount { def main(args: Array[String]): Unit = { // 1. 初始化环境 // 在 SparkCore 中的内存, 创建 SparkContext 的时候使用 // 在创建 Streaming Context 的时候也要用到 conf, 说明 Spark Streaming 是基于 Spark Core 的 // 在执行 master 的时候, 不能指定一个线程 // 因为在 Streaming 运行的时候, 需要开一个新的线程来去一直监听数据的获取 val sparkConf = new SparkConf().setAppName("streaming word count").setMaster("local[6]") // StreamingContext 其实就是 Spark Streaming 的入口 // 相当于 SparkContext 是 Spark Core 的入口一样 // 它们也都叫做 XXContext val ssc = new StreamingContext(sparkConf, Seconds(5)) ssc.sparkContext.setLogLevel("WARN")//减少日志时候使用 // socketTextStream 这个方法用于创建一个 DStream, 监听 Socket 输入, 当做文本来处理 // sparkContext.textFile() 创建一个 rdd, 他们俩类似, 都是创建对应的数据集 // RDD -> Spark Core DStream -> Spark Streaming // DStream 可以理解为是一个流式的 RDD val lines: ReceiverInputDStream[String] = ssc.socketTextStream( hostname = "192.168.15.128",//这是eth0 的 port = 9999, storageLevel = StorageLevel.MEMORY_AND_DISK_SER ) // 2. 数据的处理 // 1. 把句子拆为单词 val words: DStream[String] = lines.flatMap(_.split(" ")) // 2. 转换单词 val tuples: DStream[(String, Int)] = words.map((_, 1)) // 3. 词频reduce val counts: DStream[(String, Int)] = tuples.reduceByKey(_ + _) // 3. 展示和启动 counts.print()//并不会导致整个流执行 ssc.start() // main 方法执行完毕后整个程序就会退出, 所以需要阻塞主线程 ssc.awaitTermination() } }



Spark Streaming的特点-
Spark Streaming会源源不断的处理数据, 称之为流计算 -
Spark Streaming并不是实时流, 而是按照时间切分小批量, 一个一个的小批量处理 -
Spark Streaming是流计算, 所以可以理解为数据会源源不断的来, 需要长时间运行
Spark Streaming是按照时间切分小批量-
如何小批量?
Spark Streaming中的编程模型叫做DStream, 所有的API都从DStream开始, 其作用就类似于RDD之于Spark Core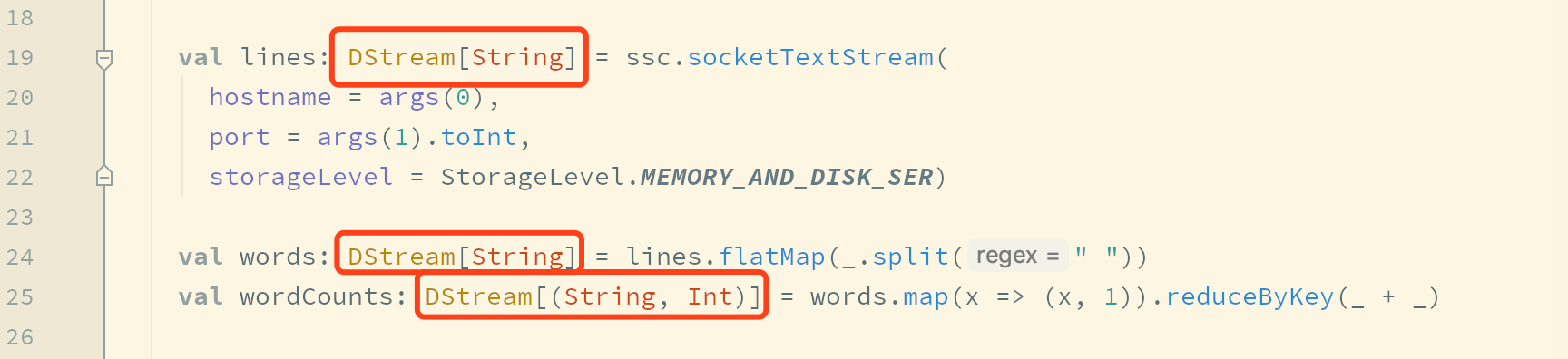
可以理解为
DStream是一个管道, 数据源源不断的从这个管道进去, 被处理, 再出去
但是需要注意的是,
DStream并不是严格意义上的实时流, 事实上,DStream并不处理数据, 而是处理RDD
以上, 可以整理出如下道理
-
Spark Streaming是小批量处理数据, 并不是实时流 -
Spark Streaming对数据的处理是按照时间切分为一个又一个小的RDD, 然后针对RDD进行处理
-
RDD和DStream的DAG如果是
RDD的WordCount, 代码大致如下val textRDD = sc.textFile(...) val splitRDD = textRDD.flatMap(_.split(" ")) val tupleRDD = splitRDD.map((_, 1)) val reduceRDD = tupleRDD.reduceByKey(_ + _)

用图形表示如下

同样,
DStream的代码大致如下val lines: DStream[String] = ssc.socketTextStream(...) val words: DStream[String] = lines.flatMap(_.split(" ")) val wordCounts: DStream[(String, Int)] = words.map(x => (x, 1)).reduceByKey(_ + _)

同理,
DStream也可以形成DAG如下
看起来
DStream和RDD好像哟, 确实如此RDD和DStream的区别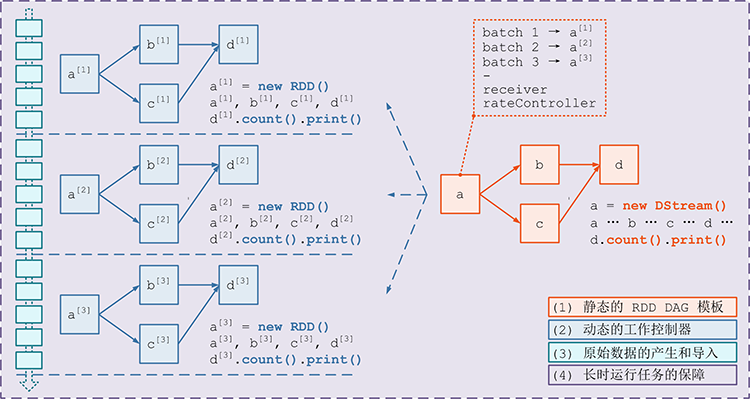
-
DStream的数据是不断进入的,RDD是针对一个数据的操作 -
像
RDD一样,DStream也有不同的子类, 通过不同的算子生成 -
一个
DStream代表一个数据集, 其中包含了针对于上一个数据的操作 -
DStream根据时间切片, 划分为多个RDD, 针对DStream的计算函数, 会作用于每一个DStream中的RDD
DStream如何形式DAG-
每个
DStream都有一个关联的DStreamGraph对象 -
DStreamGraph负责表示DStream之间的的依赖关系和运行步骤 -
DStreamGraph中会单独记录InputDStream和OutputDStream

-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号