spark学习进度17(Catalyst优化器、dataset介绍、dataframe介绍)
RDD 和 SparkSQL 运行时的区别
RDD 的运行流程
-
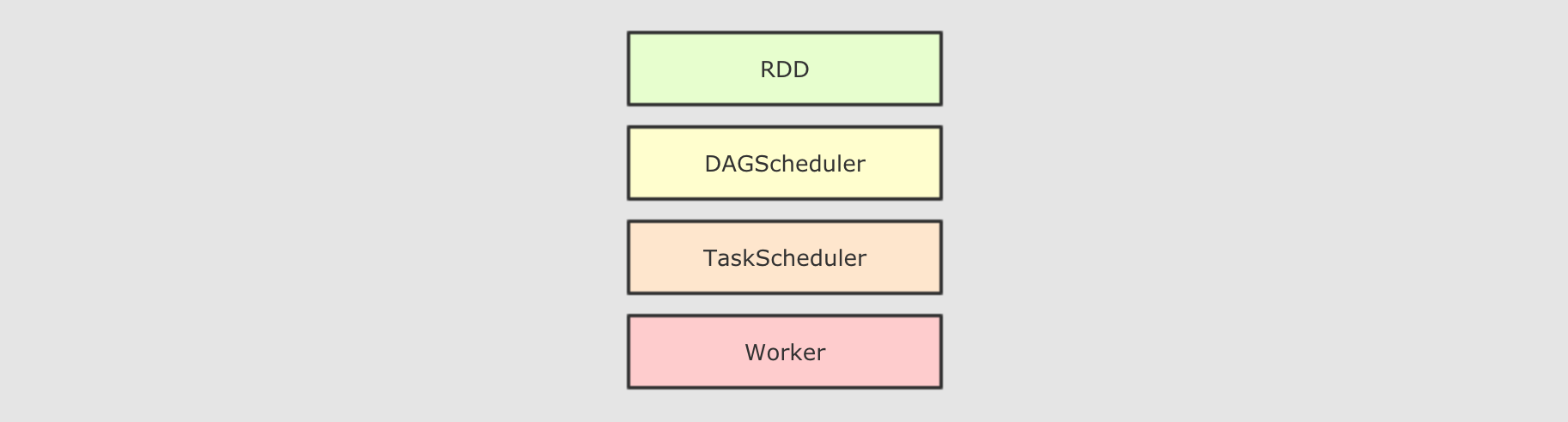
大致运行步骤
-
先将
RDD解析为由Stage组成的DAG, 后将Stage转为Task直接运行
问题
-
任务会按照代码所示运行, 依赖开发者的优化, 开发者的会在很大程度上影响运行效率
解决办法
-
创建一个组件, 帮助开发者修改和优化代码, 但是这在
RDD上是无法实现的SparkSQL提供了什么?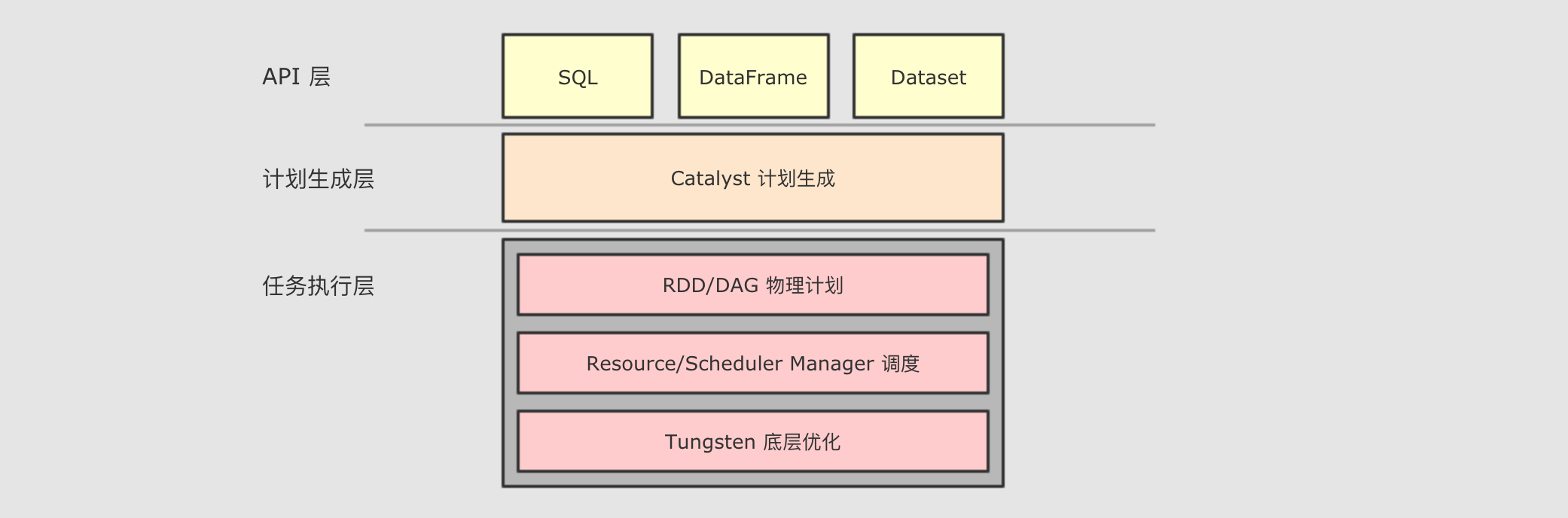
和
RDD不同,SparkSQL的Dataset和SQL并不是直接生成计划交给集群执行, 而是经过了一个叫做Catalyst的优化器, 这个优化器能够自动帮助开发者优化代码也就是说, 在
SparkSQL中, 开发者的代码即使不够优化, 也会被优化为相对较好的形式去执行Catalyst为了解决过多依赖
Hive的问题,SparkSQL使用了一个新的SQL优化器替代Hive中的优化器, 这个优化器就是Catalyst, 整个SparkSQL的架构大致如下
-
API层简单的说就是Spark会通过一些API接受SQL语句 -
收到
SQL语句以后, 将其交给Catalyst,Catalyst负责解析SQL, 生成执行计划等 -
Catalyst的输出应该是RDD的执行计划 -
最终交由集群运行

总结
SparkSQL和RDD不同的主要点是在于其所操作的数据是结构化的, 提供了对数据更强的感知和分析能力, 能够对代码进行更深层的优化, 而这种能力是由一个叫做Catalyst的优化器所提供的Catalyst的主要运作原理是分为三步, 先对SQL或者Dataset的代码解析, 生成逻辑计划, 后对逻辑计划进行优化, 再生成物理计划, 最后生成代码到集群中以RDD的形式运行Dataset 的特点
目标
-
理解
Dataset是什么 -
理解
Dataset的特性
Dataset是什么?@Test def dataset1(): Unit = { // 1. 创建 SparkSession val spark = new sql.SparkSession.Builder() .master("local[6]") .appName("dataset1") .getOrCreate() // 2. 导入隐式转换 import spark.implicits._ // 3. 演示 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val dataset = sourceRDD.toDS() // Dataset 支持强类型的 API dataset.filter( item => item.age > 10 ).show() // Dataset 支持弱类型 API dataset.filter( 'age > 10 ).show() dataset.filter( $"age" > 10 ).show() // Dataset 可以直接编写 SQL 表达式 dataset.filter("age > 10").show() }

问题1:
People是什么?People是一个强类型的类问题2: 这个
Dataset中是结构化的数据吗?非常明显是的, 因为
People对象中有结构信息, 例如字段名和字段类型问题3: 这个
Dataset能够使用类似SQL这样声明式结构化查询语句的形式来查询吗?当然可以, 已经演示过了
问题4:
Dataset是什么?Dataset是一个强类型, 并且类型安全的数据容器, 并且提供了结构化查询API和类似RDD一样的命令式APIDataset的底层是什么?Dataset最底层处理的是对象的序列化形式, 通过查看Dataset生成的物理执行计划, 也就是最终所处理的RDD, 就可以判定Dataset底层处理的是什么形式的数据val dataset: Dataset[People] = spark.createDataset(Seq(People("zhangsan", 9), People("lisi", 15))) val internalRDD: RDD[InternalRow] = dataset.queryExecution.toRdddataset.queryExecution.toRdd这个API可以看到Dataset底层执行的RDD, 这个RDD中的范型是InternalRow,InternalRow又称之为Catalyst Row, 是Dataset底层的数据结构, 也就是说, 无论Dataset的范型是什么, 无论是Dataset[Person]还是其它的, 其最底层进行处理的数据结构都是InternalRow所以,
Dataset的范型对象在执行之前, 需要通过Encoder转换为InternalRow, 在输入之前, 需要把InternalRow通过Decoder转换为范型对象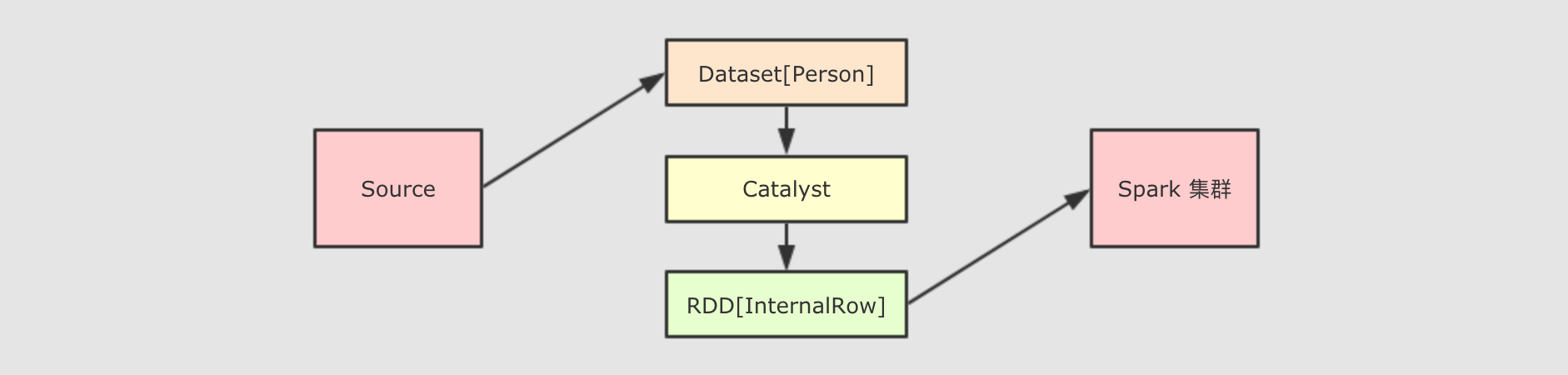
@Test def dataset2(): Unit = { // 1. 创建 SparkSession val spark = new sql.SparkSession.Builder() .master("local[6]") .appName("dataset1") .getOrCreate() // 2. 导入隐式转换 import spark.implicits._ // 3. 演示 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val dataset = sourceRDD.toDS() // dataset.explain(true) // 无论Dataset中放置的是什么类型的对象, 最终执行计划中的RDD上都是 InternalRow val executionRdd: RDD[InternalRow] = dataset.queryExecution.toRdd }
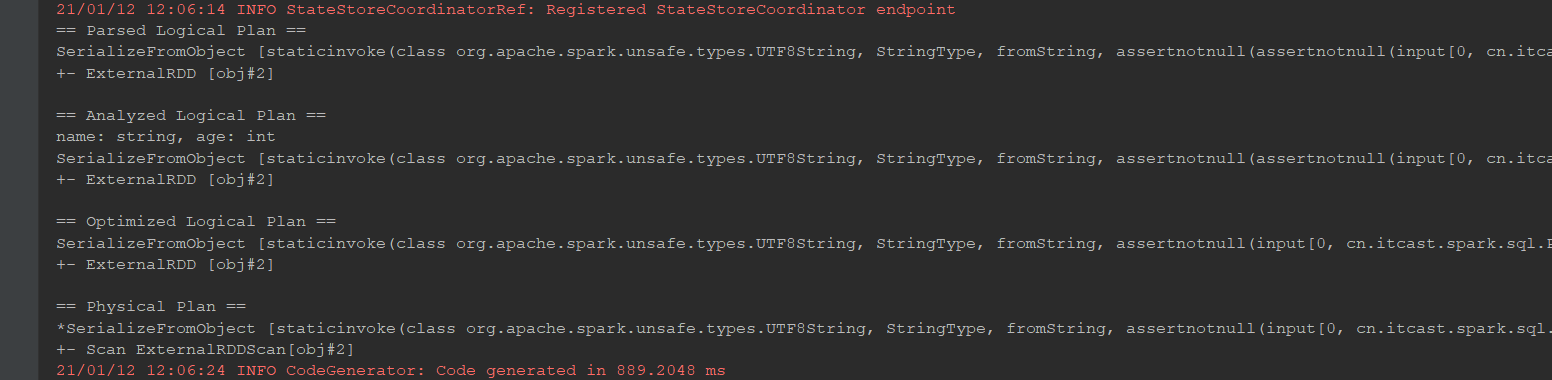
可以获取
Dataset对应的RDD表示总结
-
Dataset是一个新的Spark组件, 其底层还是RDD -
Dataset提供了访问对象中某个特定字段的能力, 不用像RDD一样每次都要针对整个对象做操作 -
Dataset和RDD不同, 如果想把Dataset[T]转为RDD[T], 则需要对Dataset底层的InternalRow做转换, 是一个比价重量级的操作
DataFrame 的作用和常见操作
目标
-
理解
DataFrame是什么 -
理解
DataFrame的常见操作
-
DataFrame是SparkSQL中一个表示关系型数据库中表的函数式抽象, 其作用是让Spark处理大规模结构化数据的时候更加容易. 一般DataFrame可以处理结构化的数据, 或者是半结构化的数据, 因为这两类数据中都可以获取到Schema信息. 也就是说DataFrame中有Schema信息, 可以像操作表一样操作DataFrame.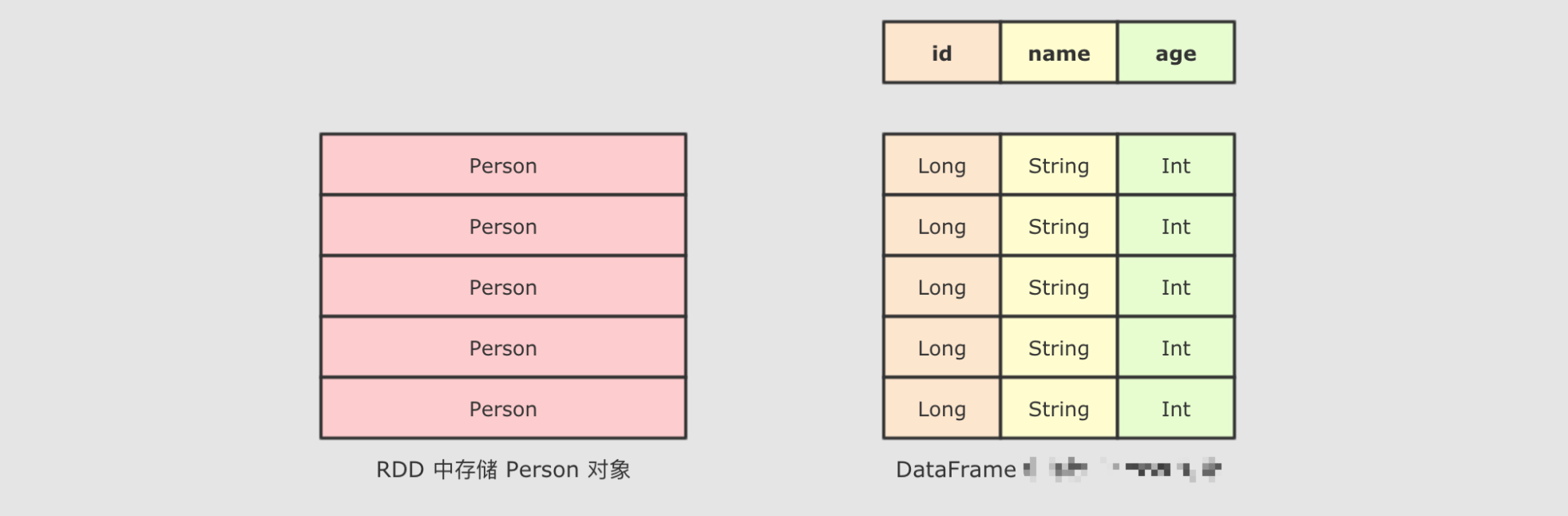
DataFrame由两部分构成, 一是row的集合, 每个row对象表示一个行, 二是描述DataFrame结构的Schema.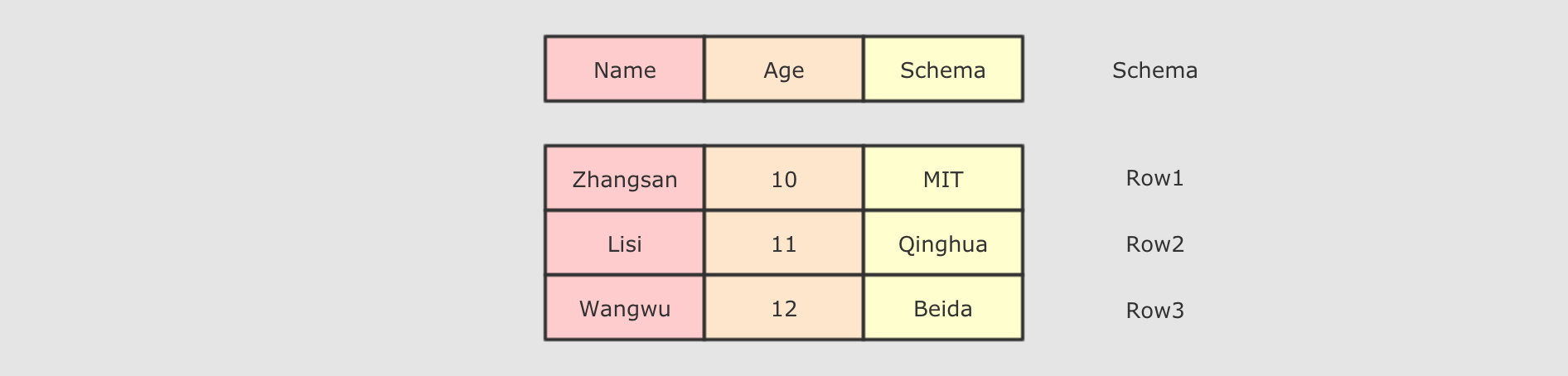
DataFrame支持SQL中常见的操作, 例如:select,filter,join,group,sort,join等
@Test def dataframe1(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .appName("dataframe1") .master("local[6]") .getOrCreate() // 2. 创建 DataFrame import spark.implicits._ val dataFrame: DataFrame = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDF() // 3. 看看 DataFrame 可以玩出什么花样 // select name from ... t where t.age > 10 dataFrame.where('age > 10) .select('name) .show() }


DataFrame如何创建:
@Test def dataframe2(): Unit = { val spark = SparkSession.builder() .appName("dataframe1") .master("local[6]") .getOrCreate() import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) // 1. toDF val df1 = personList.toDF() val df2 = spark.sparkContext.parallelize(personList).toDF() // 2. createDataFrame val df3 = spark.createDataFrame(personList) // 3. read val df4 = spark.read.csv("dataset/BeijingPM20100101_20151231_noheader.csv") df4.show() }
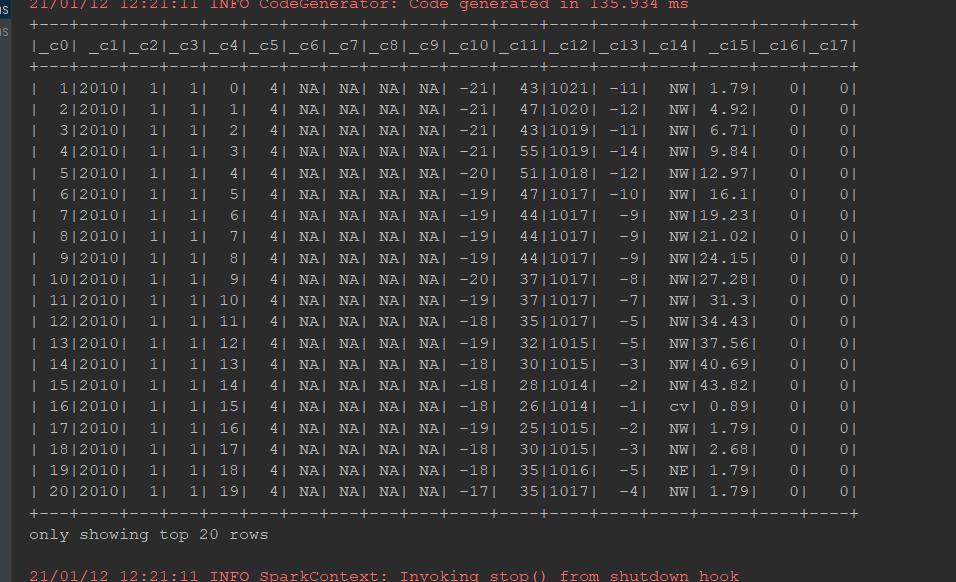
DataFrame介绍:
@Test def dataframe3(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("pm analysis") .getOrCreate() import spark.implicits._ // 2. 读取数据集 val sourceDF: DataFrame = spark.read .option("header", value = true)//把第一行弄成header .csv("dataset/BeijingPM20100101_20151231.csv") // 查看 DataFrame 的 Schema 信息, 要意识到 DataFrame 中是有结构信息的, 叫做 Schema sourceDF.printSchema() // 3. 处理 // 1. 选择列 // 2. 过滤掉 NA 的 PM 记录 // 3. 分组 select year, month, count(PM_Dongsi) from ... where PM_Dongsi != NA group by year, month // 4. 聚合 // 4. 得出结论 // sourceDF.select('year, 'month, 'PM_Dongsi) // .where('PM_Dongsi =!= "NA") // .groupBy('year, 'month) // .count() // .show() // 是否能直接使用 SQL 语句进行查询 // 1. 将 DataFrame 注册为临表 sourceDF.createOrReplaceTempView("pm") // 2. 执行查询 val resultDF = spark.sql("select year, month, count(PM_Dongsi) from pm where PM_Dongsi != 'NA' group by year, month") resultDF.show() spark.stop() }

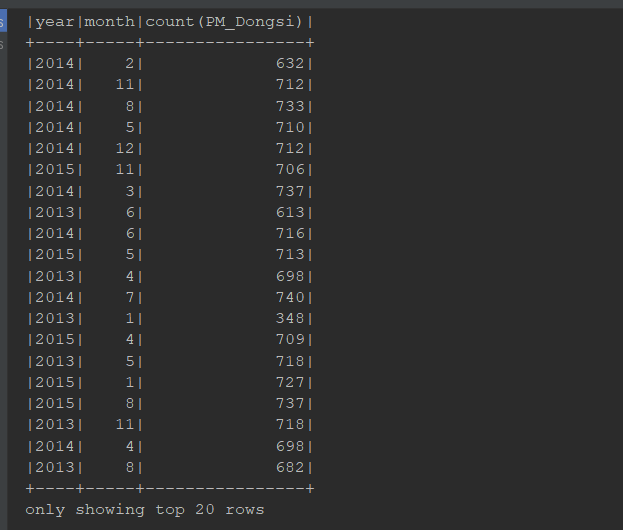
Dataset 和 DataFrame 的异同
目标
-
理解
Dataset和DataFrame之间的关系
DataFrame就是Dataset-
根据前面的内容, 可以得到如下信息
-
Dataset中可以使用列来访问数据,DataFrame也可以 -
Dataset的执行是优化的,DataFrame也是 -
Dataset具有命令式API, 同时也可以使用SQL来访问,DataFrame也可以使用这两种不同的方式访问
所以这件事就比较蹊跷了, 两个这么相近的东西为什么会同时出现在
SparkSQL中呢?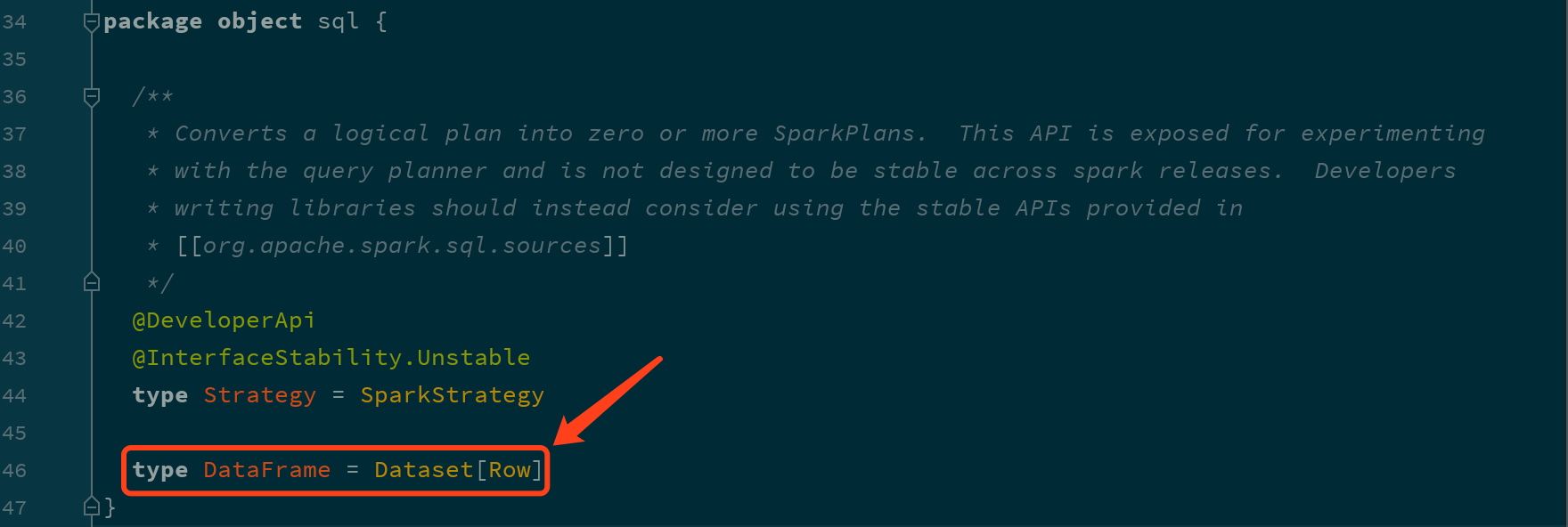
确实, 这两个组件是同一个东西,
DataFrame是Dataset的一种特殊情况, 也就是说DataFrame是Dataset[Row]的别名 -
DataFrame和Dataset所表达的语义不同
@Test def dataframe4(): Unit = { val spark = SparkSession.builder() .appName("dataframe1") .master("local[6]") .getOrCreate() import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) // DataFrame 是弱类型的 val df: DataFrame = personList.toDF() df.map( (row: Row) => Row(row.get(0), row.getAs[Int](1) * 2) )(RowEncoder.apply(df.schema)) .show() // DataFrame 所代表的弱类型操作是编译时不安全 // df.groupBy("name, school") // Dataset 是强类型的 val ds: Dataset[Person] = personList.toDS() ds.map( (person: Person) => Person(person.name, person.age * 2) ) .show() // Dataset 所代表的操作, 是类型安全的, 编译时安全的 // ds.filter( person => person.school ) }


Row
@Test def row(): Unit = { // 1. Row 如何创建, 它是什么 // row 对象必须配合 Schema 对象才会有 列名 val p = Person("zhangsan", 15) val row = Row("zhangsan", 15) // 2. 如何从 Row 中获取数据 row.getString(0) row.getInt(1) // 3. Row 也是样例类 row match { case Row(name, age) => println(name, age) } }

-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号