spark学习进度13(spark总体介绍)
这一节基本上全是概念:::
更新的几种写法:
部署:
逻辑:

其实 RDD 并没有什么严格的逻辑执行图和物理执行图的概念, 这里也只是借用这个概念, 从而让整个 RDD 的原理可以解释, 好理解.
对于 RDD 的逻辑执行图, 起始于第一个入口 RDD 的创建, 结束于 Action 算子执行之前, 主要的过程就是生成一组互相有依赖关系的 RDD, 其并不会真的执行, 只是表示 RDD 之间的关系, 数据的流转过程.
物理:
当触发 Action 执行的时候, 这一组互相依赖的 RDD 要被处理, 所以要转化为可运行的物理执行图, 调度到集群中执行.
因为大部分 RDD 是不真正存放数据的, 只是数据从中流转, 所以, 不能直接在集群中运行 RDD, 要有一种 Pipeline 的思想, 需要将这组 RDD 转为 Stage 和 Task, 从而运行 Task, 优化整体执行速度.
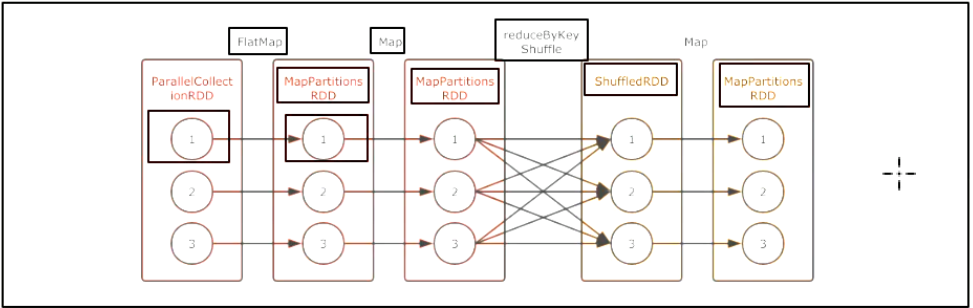
以上的逻辑执行图会生成如下的物理执行图, 这一切发生在 Action 操作被执行时.
从上图可以总结如下几个点
-
 在第一个
在第一个 Stage中, 每一个这样的执行流程是一个Task, 也就是在同一个 Stage 中的所有 RDD 的对应分区, 在同一个 Task 中执行 -
Stage 的划分是由 Shuffle 操作来确定的, 有 Shuffle 的地方, Stage 断开
textFile算子的背后-
研究
RDD的功能或者表现的时候, 其实本质上研究的就是RDD中的五大属性, 因为RDD透过五大属性来提供功能和表现, 所以如果要研究textFile这个算子, 应该从五大属性着手, 那么第一步就要看看生成的RDD是什么类型的RDD-
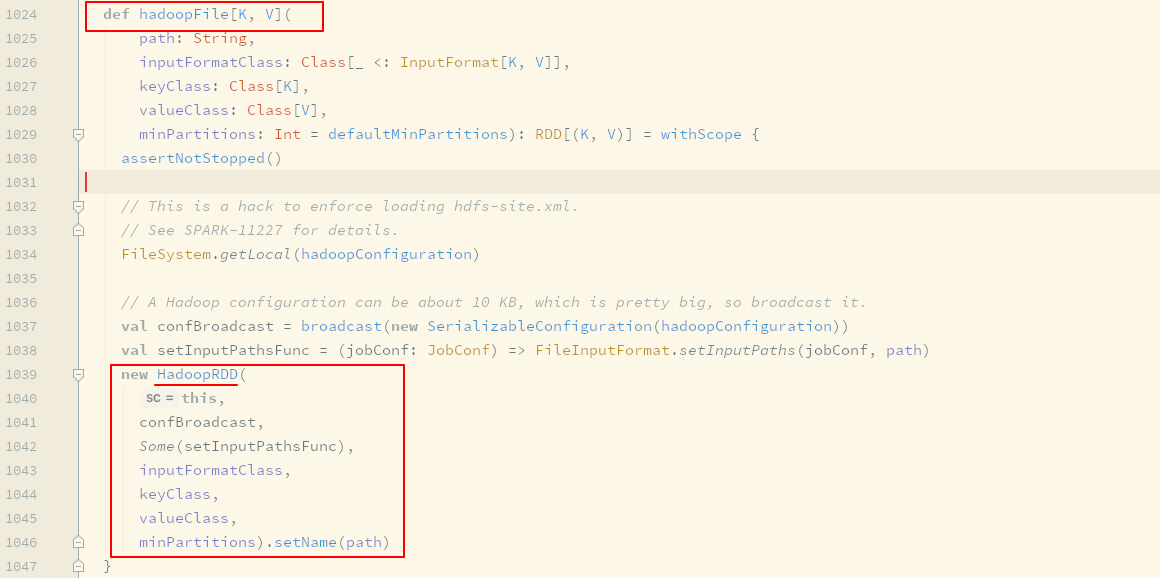
textFile生成的是HadoopRDD
除了上面这一个步骤以外, 后续步骤将不再直接基于代码进行讲解, 因为从代码的角度着手容易迷失逻辑, 这个章节的初心有两个, 一个是希望大家了解 Spark 的内部逻辑和原理, 另外一个是希望大家能够通过本章学习具有代码分析的能力
-
HadoopRDD的Partitions对应了HDFS的Blocks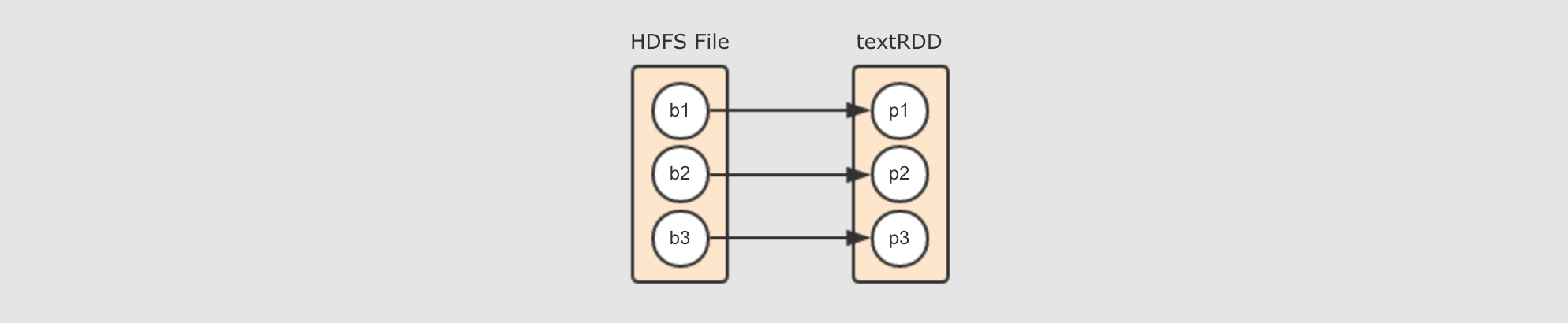
其实本质上每个
HadoopRDD的Partition都是对应了一个Hadoop的Block, 通过InputFormat来确定Hadoop中的Block的位置和边界, 从而可以供一些算子使用 -
HadoopRDD的compute函数就是在读取HDFS中的Block本质上,
compute还是依然使用InputFormat来读取HDFS中对应分区的Block -
textFile这个算子生成的其实是一个MapPartitionsRDDtextFile这个算子的作用是读取HDFS上的文件, 但是HadoopRDD中存放是一个元组, 其Key是行号, 其Value是Hadoop中定义的Text对象, 这一点和MapReduce程序中的行为是一致的但是并不适合
Spark的场景, 所以最终会通过一个map算子, 将(LineNum, Text)转为String形式的一行一行的数据, 所以最终textFile这个算子生成的RDD并不是HadoopRDD, 而是一个MapPartitionsRDD
-
map算子的背后-

-
map算子生成了MapPartitionsRDD由源码可知, 当
val rdd2 = rdd1.map()的时候, 其实生成的新RDD是rdd2,rdd2的类型是MapPartitionsRDD, 每个RDD中的五大属性都会有一些不同, 由map算子生成的RDD中的计算函数, 本质上就是遍历对应分区的数据, 将每一个数据转成另外的形式 -
MapPartitionsRDD的计算函数是collection.map( function )真正运行的集群中的处理单元是
Task, 每个Task对应一个RDD的分区, 所以collection对应一个RDD分区的所有数据, 而这个计算的含义就是将一个RDD的分区上所有数据当作一个集合, 通过这个Scala集合的map算子, 来执行一个转换操作, 其转换操作的函数就是传入map算子的function -
传入
map算子的函数会被清理
这个清理主要是处理闭包中的依赖, 使得这个闭包可以被序列化发往不同的集群节点运行
-
flatMap算子的背后-

flatMap和map算子其实本质上是一样的, 其步骤和生成的RDD都是一样, 只是对于传入函数的处理不同,map是collect.map( function )而flatMap是collect.flatMap( function )从侧面印证了, 其实
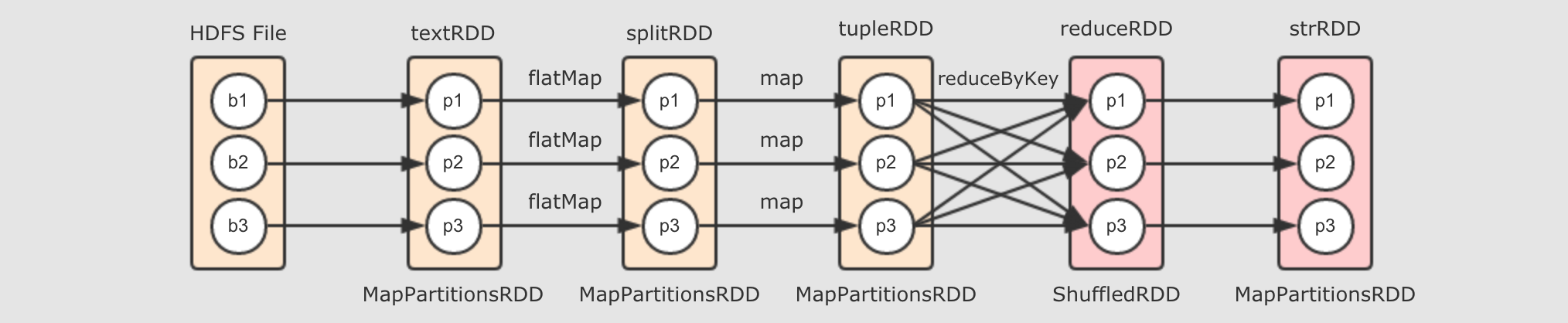
Spark中的flatMap和Scala基础中的flatMap其实是一样的 textRDD→splitRDD→tupleRDD-
由
textRDD到splitRDD再到tupleRDD的过程, 其实就是调用map和flatMap算子生成新的RDD的过程, 所以如下图所示, 就是这个阶段所生成的逻辑计划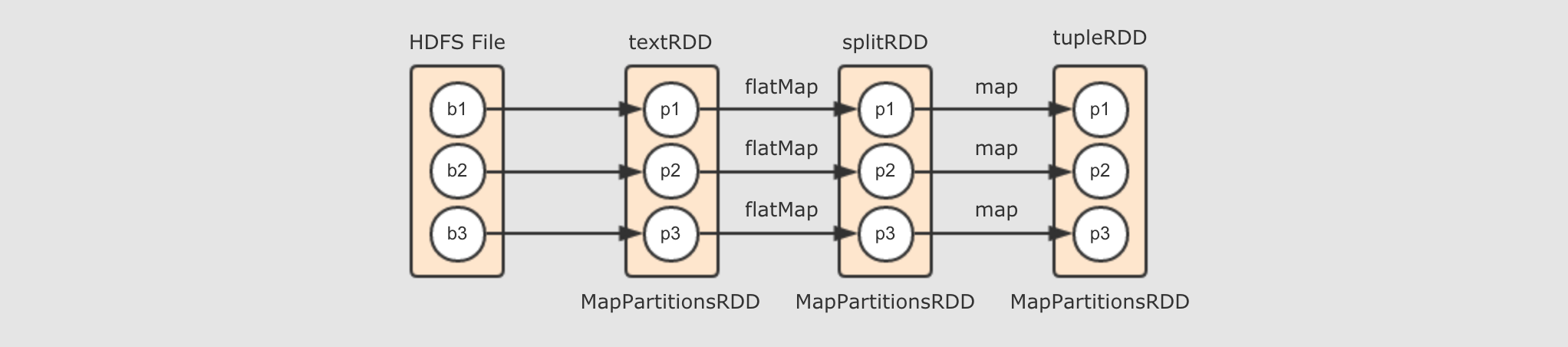 总结
总结
- 如何生成
RDD? - 生成哪些
RDD? - 如何计算
RDD中的数据 ? -
虽然前面我们提到过
RDD是偏向计算的, 但是其实RDD还只是表示数据, 纵观RDD的五大属性中有三个是必须的, 分别如下-
Partitions List分区列表 -
Compute function计算函数 -
Dependencies依赖
虽然计算函数是和计算有关的, 但是只有调用了这个函数才会进行计算,
RDD显然不会自己调用自己的Compute函数, 一定是由外部调用的, 所以RDD更多的意义是用于表示数据集以及其来源, 和针对于数据的计算所以如何计算
RDD中的数据呢? 一定是通过其它的组件来计算的, 而计算的规则, 由RDD中的Compute函数来指定, 不同类型的RDD子类有不同的Compute函数什么是RDD之间的依赖关系?-
什么是关系(依赖关系) ?
从算子视角上来看,
splitRDD通过map算子得到了tupleRDD, 所以splitRDD和tupleRDD之间的关系是map但是仅仅这样说, 会不够全面, 从细节上来看,
RDD只是数据和关于数据的计算, 而具体执行这种计算得出结果的是一个神秘的其它组件, 所以, 这两个RDD的关系可以表示为splitRDD的数据通过map操作, 被传入tupleRDD, 这是它们之间更细化的关系但是
RDD这个概念本身并不是数据容器, 数据真正应该存放的地方是RDD的分区, 所以如果把视角放在数据这一层面上的话, 直接讲这两个 RDD 之间有关系是不科学的, 应该从这两个 RDD 的分区之间的关系来讨论它们之间的关系 -
那这些分区之间是什么关系?
如果仅仅说
splitRDD和tupleRDD之间的话, 那它们的分区之间就是一对一的关系但是
tupleRDD到reduceRDD呢?tupleRDD通过算子reduceByKey生成reduceRDD, 而这个算子是一个Shuffle操作,Shuffle操作的两个RDD的分区之间并不是一对一,reduceByKey的一个分区对应tupleRDD的多个分区
reduceByKey算子会生成ShuffledRDDreduceByKey是由算子combineByKey来实现的,combineByKey内部会创建ShuffledRDD返回, 具体的代码请大家通过IDEA来进行查看, 此处不再截图, 而整个reduceByKey操作大致如下过程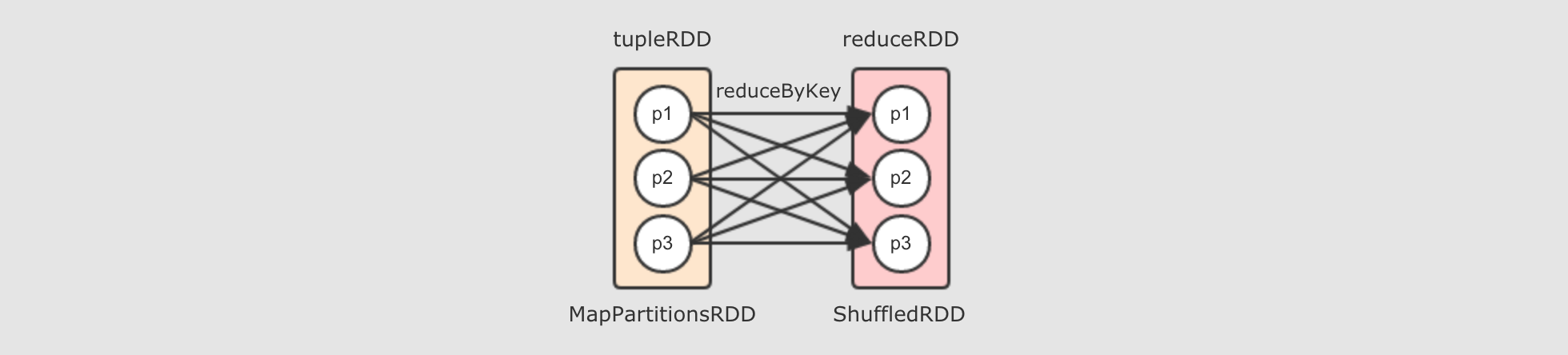
去掉两个
reducer端的分区, 只留下一个的话, 如下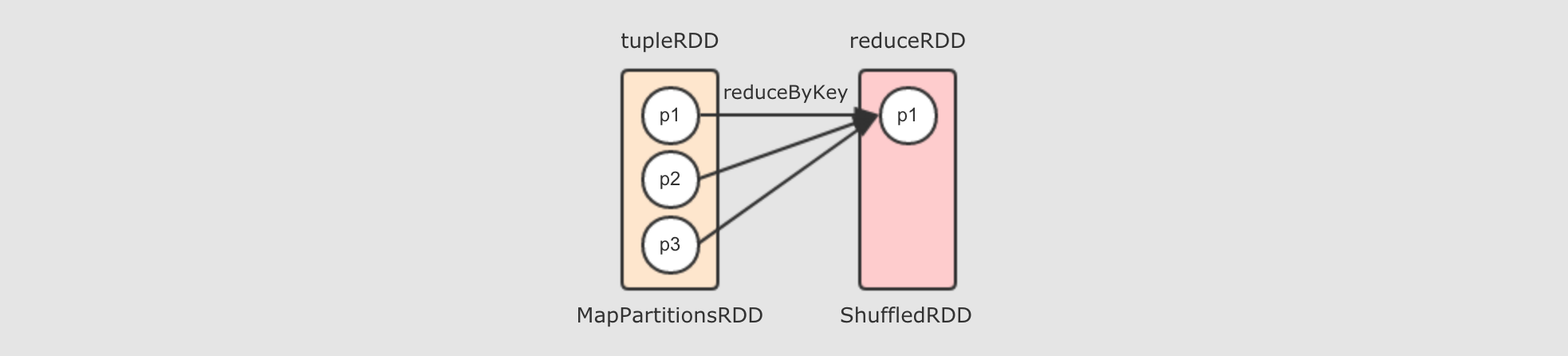
所以, 对于
reduceByKey这个Shuffle操作来说,reducer端的一个分区, 会从多个mapper端的分区拿取数据, 是一个多对一的关系至此为止, 出现了两种分区见的关系了, 一种是一对一, 一种是多对一
整体上的流程图
 物理图的作用是什么?谁来计算 RDD ?
物理图的作用是什么?谁来计算 RDD ?- 问题一: 物理图的意义是什么?
-
物理图解决的其实就是
RDD流程生成以后, 如何计算和运行的问题, 也就是如何把 RDD 放在集群中执行的问题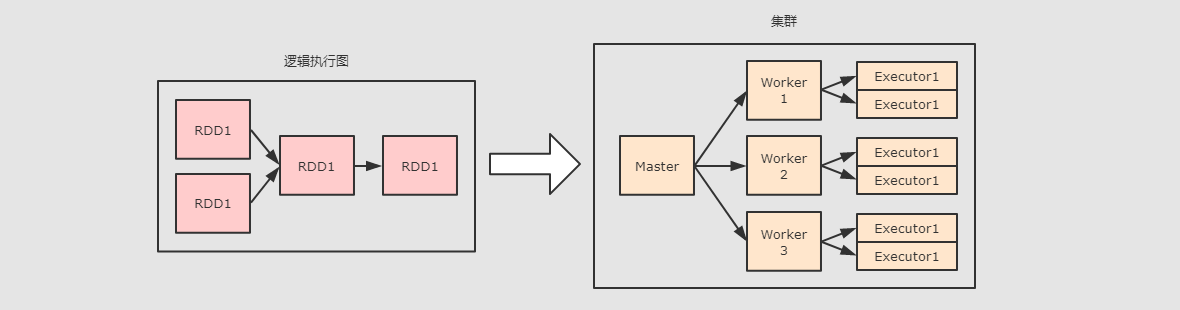
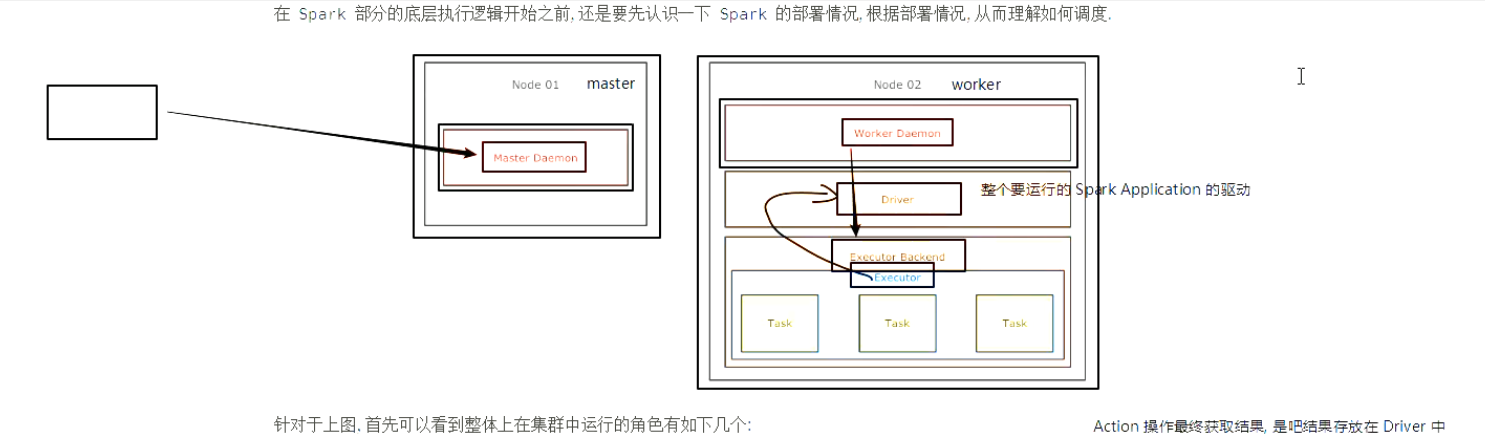
- 问题二: 如果要确定如何运行的问题, 则需要先确定集群中有什么组件
-
-
首先集群中物理元件就是一台一台的机器
-
其次这些机器上跑的守护进程有两种:
Master,Worker-
每个守护进程其实就代表了一台机器, 代表这台机器的角色, 代表这台机器和外界通信
-
例如我们常说一台机器是
Master, 其含义是这台机器中运行了一个Master守护进程, 如果一台机器运行了Master的同时又运行了Worker, 则说这台机器是Master也可以, 说它是Worker也行
-
-
真正能运行
RDD的组件是:Executor, 也就是说其实RDD最终是运行在Executor中的, 也就是说, 无论是Master还是Worker其实都是用于管理Executor和调度程序的
结论是
RDD一定在Executor中计算, 而Master和Worker负责调度和管理Executor -
- 问题三: 物理图的生成需要考虑什么问题?
-
-
要计算
RDD, 不仅要计算, 还要很快的计算 → 优化性能 -
要考虑容错, 容错的常见手段是缓存 →
RDD要可以缓存
结论是在生成物理图的时候, 不仅要考虑效率问题, 还要考虑一种更合适的方式, 让
RDD运行的更好 -
问题三: Task 该如何设计 ?- 问题一: RDD 是什么, 用来做什么 ?
-
回顾一下
RDD的五个属性-
A list of partitions -
A function for computing each split -
A list of dependencies on other RDDs -
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) -
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
简单的说就是: 分区列表, 计算函数, 依赖关系, 分区函数, 最佳位置
-
分区列表, 分区函数, 最佳位置, 这三个属性其实说的就是数据集在哪, 在哪更合适, 如何分区
-
计算函数和依赖关系, 这两个属性其实说的是数据集从哪来
所以结论是
RDD是一个数据集的表示, 不仅表示了数据集, 还表示了这个数据集从哪来, 如何计算但是问题是, 谁来计算 ? 如果为一台汽车设计了一个设计图, 那么设计图自己生产汽车吗 ?
-
- 问题二: 谁来计算 ?
-
前面我们明确了两件事,
RDD在哪被计算? 在Executor中.RDD是什么? 是一个数据集以及其如何计算的图纸.直接使用
Executor也是不合适的, 因为一个计算的执行总是需要一个容器, 例如JVM是一个进程, 只有进程中才能有线程, 所以这个计算RDD的线程应该运行在一个进程中, 这个进程就是Exeutor,Executor有如下两个职责-
和
Driver保持交互从而认领属于自己的任务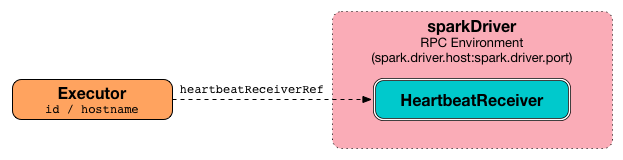
-
接受任务后, 运行任务

-
所以, 应该由一个线程来执行
RDD的计算任务, 而Executor作为执行这个任务的容器, 也就是一个进程, 用于创建和执行线程, 这个执行具体计算任务的线程叫做Task如何划分阶段 ?第一个想法是每个
RDD都由一个Task来计算 第二个想法是一整个逻辑执行图中所有的RDD都由一组Task来执行 第三个想法是分阶段执行- 第一个想法: 为每个 RDD 的分区设置一组 Task
-

大概就是每个
RDD都有三个Task, 每个Task对应一个RDD的分区, 执行一个分区的数据的计算但是这么做有一个非常难以解决的问题, 就是数据存储的问题, 例如
Task 1, 4, 7, 10, 13, 16在同一个流程上, 但是这些Task之间需要交换数据, 因为这些Task可能被调度到不同的机器上上, 所以Task1执行完了数据以后需要暂存, 后交给Task4来获取这只是一个简单的逻辑图, 如果是一个复杂的逻辑图, 会有什么表现? 要存储多少数据? 无论是放在磁盘还是放在内存中, 是不是都是一种极大的负担?
- 第二个想法: 让数据流动
-
很自然的, 第一个想法的问题是数据需要存储和交换, 那不存储不就好了吗? 对, 可以让数据流动起来
第一个要解决的问题就是, 要为数据创建管道(
Pipeline), 有了管道, 就可以流动
简单来说, 就是为所有的
RDD有关联的分区使用同一个Task, 但是就没问题了吗? 请关注红框部分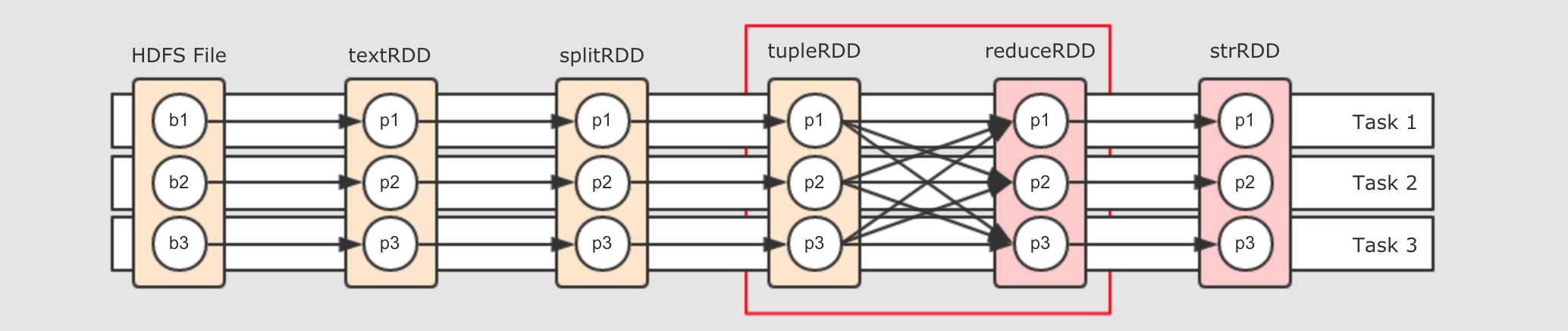
这两个
RDD之间是Shuffle关系, 也就是说, 右边的RDD的一个分区可能依赖左边RDD的所有分区, 这样的话, 数据在这个地方流不动了, 怎么办? - 第三个想法: 划分阶段
-
既然在
Shuffle处数据流不动了, 那就可以在这个地方中断一下, 后面Stage部分详解
数据怎么流动 ?为了减少执行任务, 减少数据暂存和交换的机会, 所以需要创建管道, 让数据沿着管道流动, 其实也就是原先每个
RDD都有一组Task, 现在改为所有的RDD共用一组Task, 但是也有问题, 问题如下就是说, 在
Shuffle处, 必须断开管道, 进行数据交换, 交换过后, 继续流动, 所以整个流程可以变为如下样子
把
Task断开成两个部分,Task4可以从Task 1, 2, 3中获取数据, 后Task4又作为管道, 继续让数据在其中流动但是还有一个问题, 说断开就直接断开吗? 不用打个招呼的呀? 这个断开即没有道理, 也没有规则, 所以可以为这个断开增加一个概念叫做阶段, 按照阶段断开, 阶段的英文叫做
Stage, 如下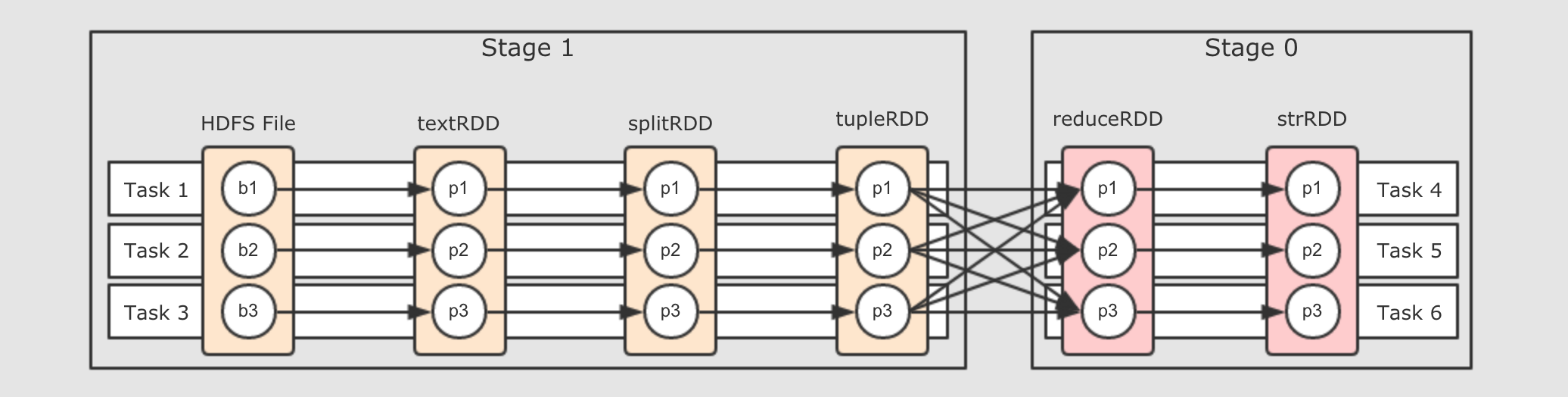
所以划分阶段的本身就是设置断开点的规则, 那么该如何划分阶段呢?
-
第一步, 从最后一个
RDD, 也就是逻辑图中最右边的RDD开始, 向前滑动Stage的范围, 为Stage0 -
第二步, 遇到
ShuffleDependency断开Stage, 从下一个RDD开始创建新的Stage, 为Stage1 -
第三步, 新的
Stage按照同样的规则继续滑动, 直到包裹所有的RDD
总结来看, 就是针对于宽窄依赖来判断, 一个
Stage中只有窄依赖, 因为只有窄依赖才能形成数据的Pipeline.如果要进行
Shuffle的话, 数据是流不过去的, 必须要拷贝和拉取. 所以遇到RDD宽依赖的两个RDD时, 要切断这两个RDD的Stage.这样一个 RDD 依赖的链条, 我们称之为 RDD 的血统, 其中有宽依赖也有窄依赖
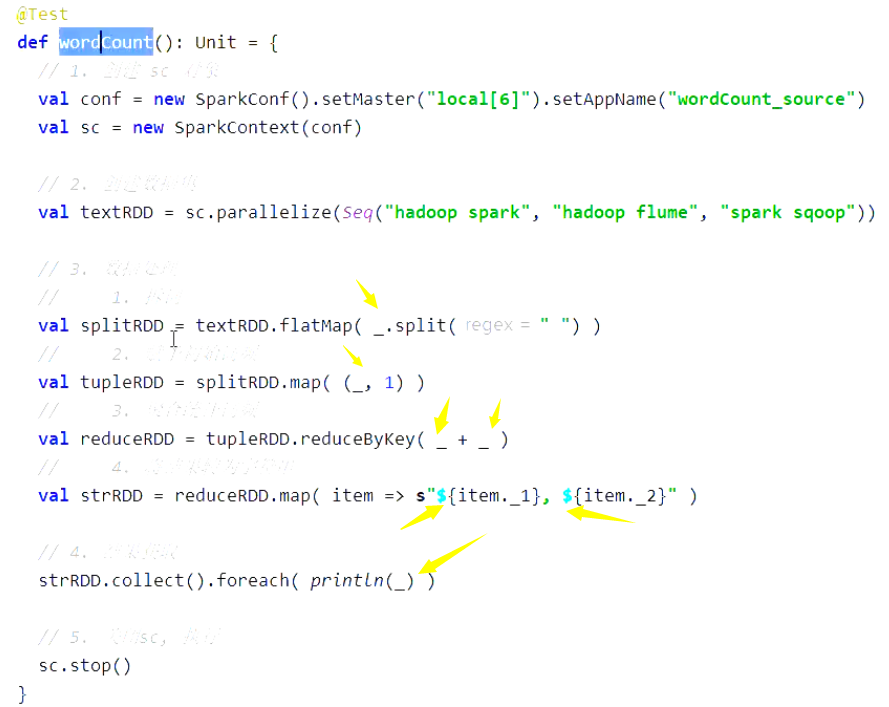
val sc = ... val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val splitRDD = textRDD.flatMap(_.split(" ")) val tupleRDD = splitRDD.map((_, 1)) val reduceRDD = tupleRDD.reduceByKey(_ + _) val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}") strRDD.collect.foreach(item => println(item))上述代码是这个章节我们一直使用的代码流程, 如下是其完整的逻辑执行图
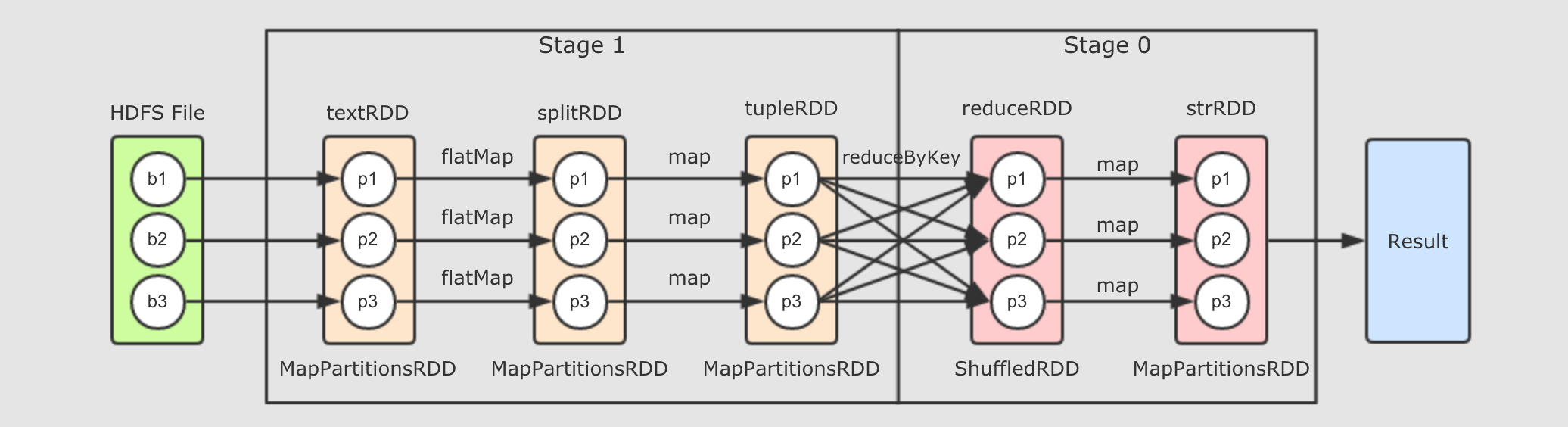
如果放在集群中运行, 通过
WebUI可以查看到如下DAG结构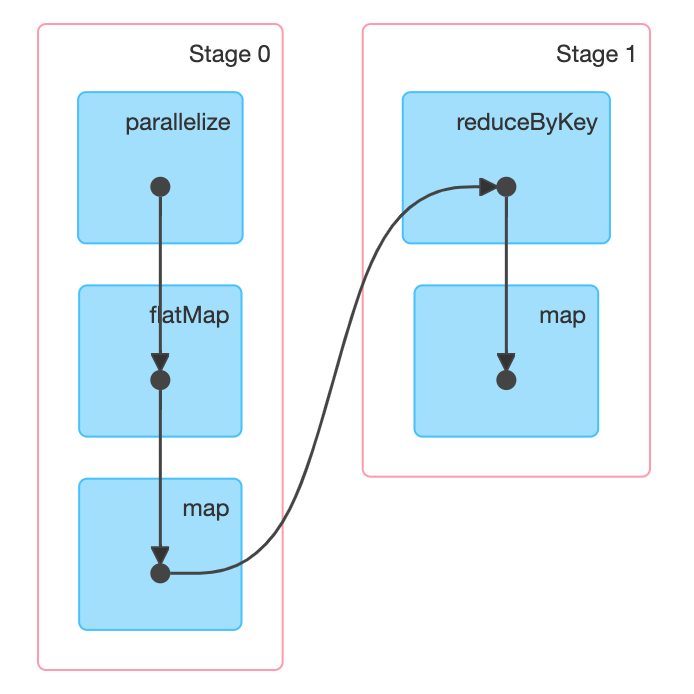
- Step 1: 从
ResultStage开始执行 -
最接近
Result部分的Stage id为 0, 这个Stage被称之为ResultStage由代码可以知道, 最终调用
Action促使整个流程执行的是最后一个RDD,strRDD.collect, 所以当执行RDD的计算时候, 先计算的也是这个RDD - Step 2:
RDD之间是有关联的 -
前面已经知道, 最后一个
RDD先得到执行机会, 先从这个RDD开始执行, 但是这个RDD中有数据吗 ? 如果没有数据, 它的计算是什么? 它的计算是从父RDD中获取数据, 并执行传入的算子的函数简单来说, 从产生
Result的地方开始计算, 但是其RDD中是没数据的, 所以会找到父RDD来要数据, 父RDD也没有数据, 继续向上要, 所以, 计算从Result处调用, 但是从整个逻辑图中的最左边RDD开始, 类似一个递归的过程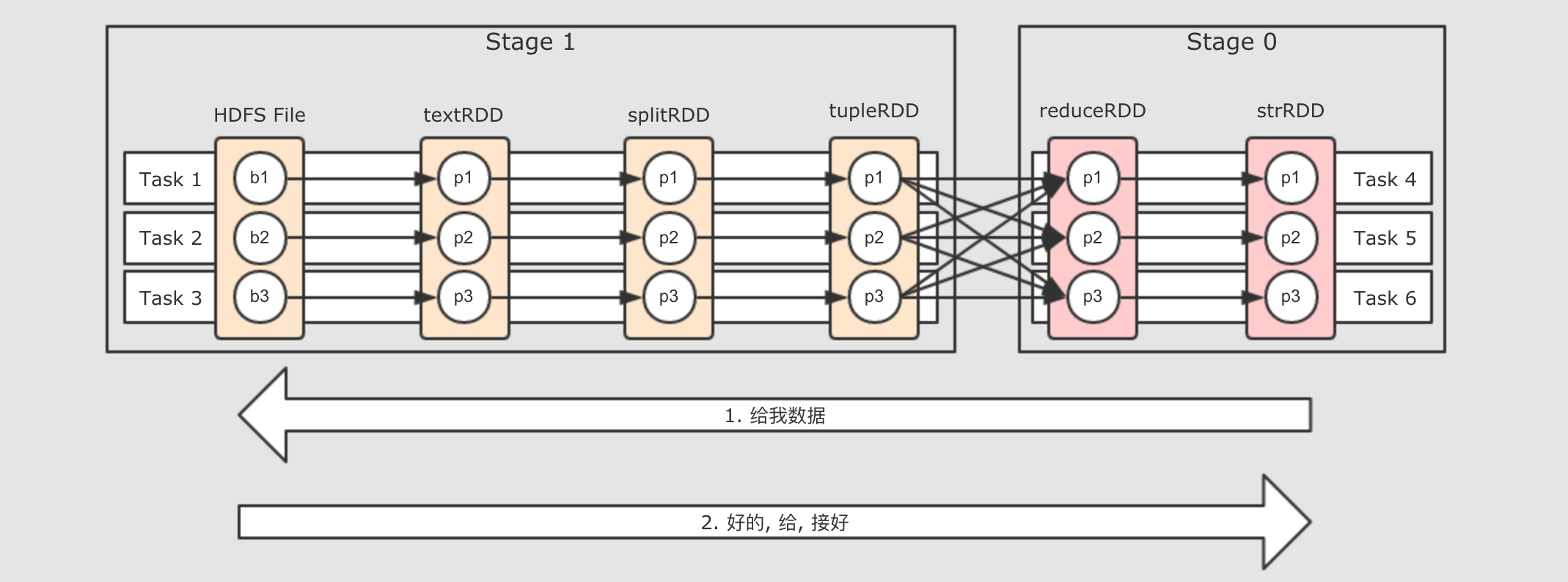
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号