
在聊天机器人中加入专家决策机制对学生成绩、享受和焦虑的影响
(Effects of Incorporating an Expert Decision-making Mechanism into Chatbots on Students’ Achievement, Enjoyment, and Anxiety)
一、摘要
研究目的:聊天机器人提供了一个解决传统教学中教学活动缺乏活力、教师查看个别学生学习情况困难以及无法及时反馈学生疑难等问题的机会。然而,传统的聊天机器人(C-chatbot)通常是作为信息提供者(即通过匹配对话中的关键字来提供相关信息)而不是作为决策顾问(即使用具有决策机制的知识库来帮助用户解决问题)。因此,本研究提出了一种基于专家决策的聊天机器人(EDM-chatbot),以方便学生个体在学习过程中对知识的建构,通过聊天机器人学习减少学生的学习焦虑,保持学生的学习乐趣,获得更好的学习效果。
实验结果:结合专家决策知识的edm聊天机器人显著提高了学生的学习成绩和学习乐趣,减少了学生的学习焦虑。
二、研究问题
(1)使用EDM聊天机器人的学生是否比使用传统聊天机器人的学生学习成绩更好?
(2)使用EDM聊天机器人的学生是否比使用传统聊天机器人的学生学习焦虑更低?
(3)使用EDM聊天机器人的学生是否比使用传统聊天机器人的学生学习乐趣更高?
三、研究设计
(一)基于专家决策的聊天机器人的开发
本研究使用IBM Watson为一门科学课程的地理气候单元构建了一个聊天机器人。气候变化是一个复杂的环境问题,可以用来考察学生通过课堂交流获得的对气候变化及其相互作用的理解。Jakobsson等人(2009)在一项通过笔试进行的研究中发现,学生对气候变化的理解较差,笔试并不能明确地揭示学生学到的知识。因此,本研究认为如果使用交际法,学生对气候变化等复杂问题的理解或意义构建会更好。
1.基于ID3算法构建决策树
表1显示了用于构建ID3决策树的专家知识示例(Quinlan, 1983)。天气有16个分类(即C1、C2…C16),由海拔、冬冷夏凉、纬度、降雨、旱季、夏干、静止锋、针叶林、雪(无雨)9个构式组成,它们各自有不同的临界特征值。
表1训练数据集S
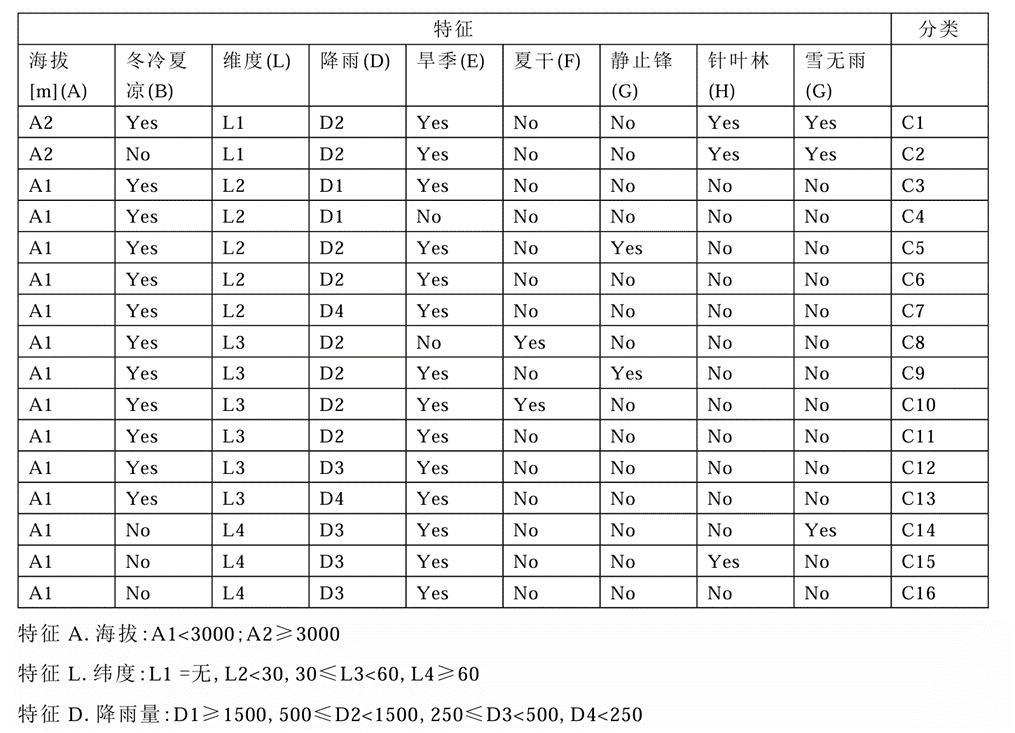
为了开发正确分类训练样例的决策规则,ID3首先选择一个特征,然后使用选择的特征将样例分类为子类来执行特征测试,从而形成有效的决策树。
① 计算信息熵:度量样本纯度的指标,熵值越小,样本集纯度越高。
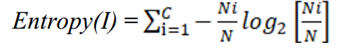
② 计算基于每个特征的信息增益(表示在使用指定属性的特定条件下信息复杂性降低的程度),挑选最优特征,即信息增益最大的特征作为根节点。
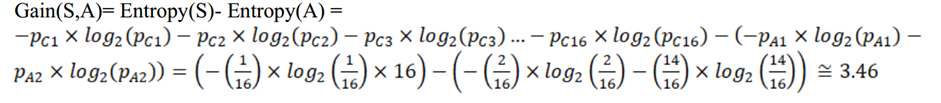
③ 分割数据:根据选定的最优特征分割数据,为每个分割创建子节点。
④ 递归构建:对每个子节点重复上述过程,直到满足停止条件(例如所有样本都属于同一类别,或者达到了树的最大深度)
图1气候决策树
2.用python生成决策树简单实例
表2训练样本集D
python源代码如下:
|
#! Decision Tree(ID3算法信息增益Gain) |

图2运行结果
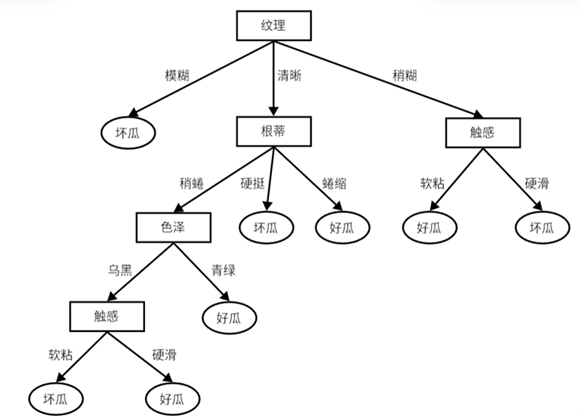
图3可视化树状结构图
3.EDM聊天机器人系统与C聊天机器人系统
聊天机器人都具有学习功能,并采用IBM Watson中的模糊匹配技术,使其与学生的对话更加顺畅。模糊匹配使系统能够处理词干提取、拼写错误或部分匹配。
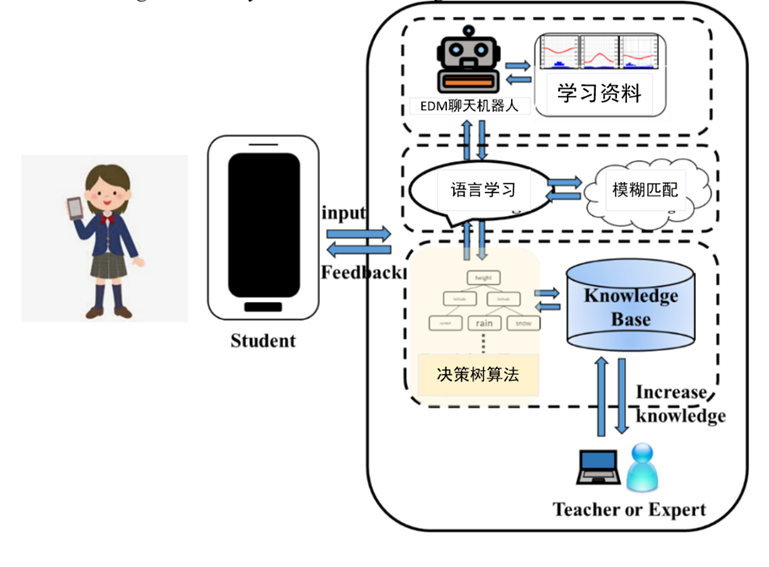
图4 EDM聊天机器人的系统架构图
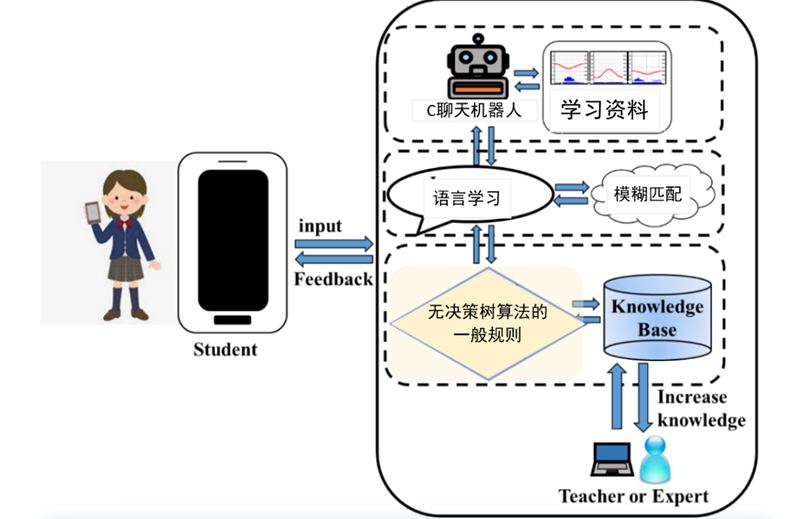 图5 C聊天机器人的系统架构图
图5 C聊天机器人的系统架构图
图6展示了传统聊天机器人的对话设计,系统会先向学生提出一个问题,紧接着为学生提供多个选择信息,然后根据学生选择提供数据库中相应的学习内容。传统聊天机器人很容易陷入相同的对话循环,所以当学生想要与其交互时,可以通过单击对话项进行选择。如果学生不只是想点击选项,也可以直接回复想说的内容。EDM聊天机器人的对话经过算法处理,基于专家知识和决策树的对话更加精简,学生更容易组织自己的知识,找到自己的学习目标,如图7所示。
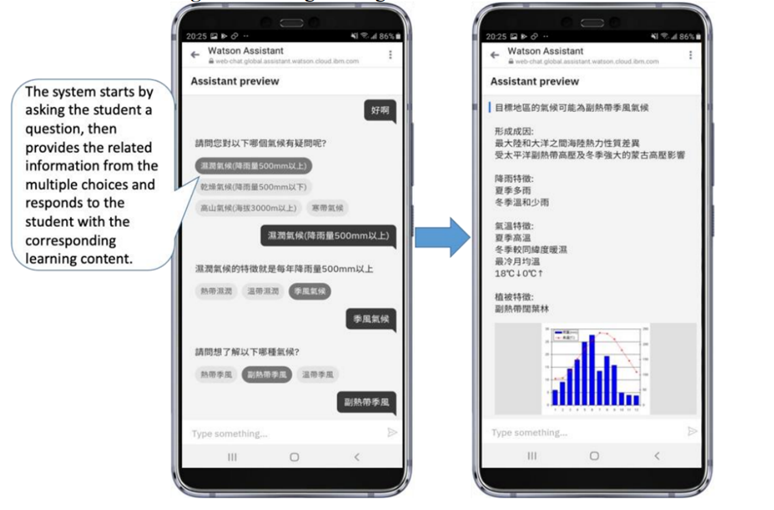
图6 C聊天机器人的对话设计
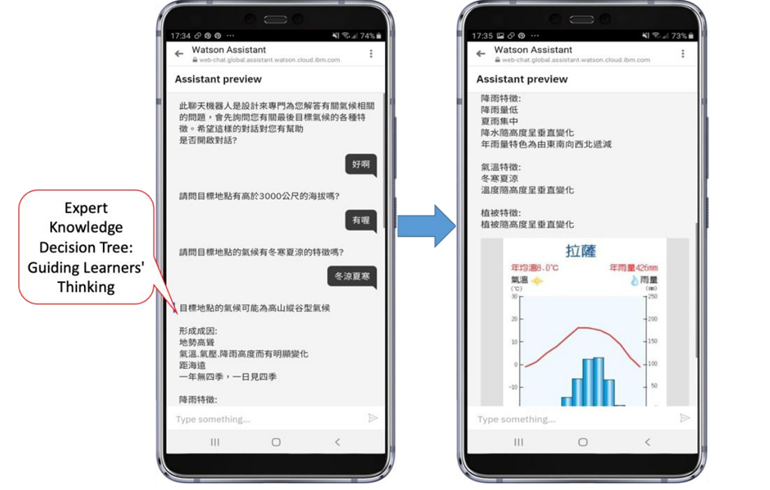
图7 EDM聊天机器人的对话设计
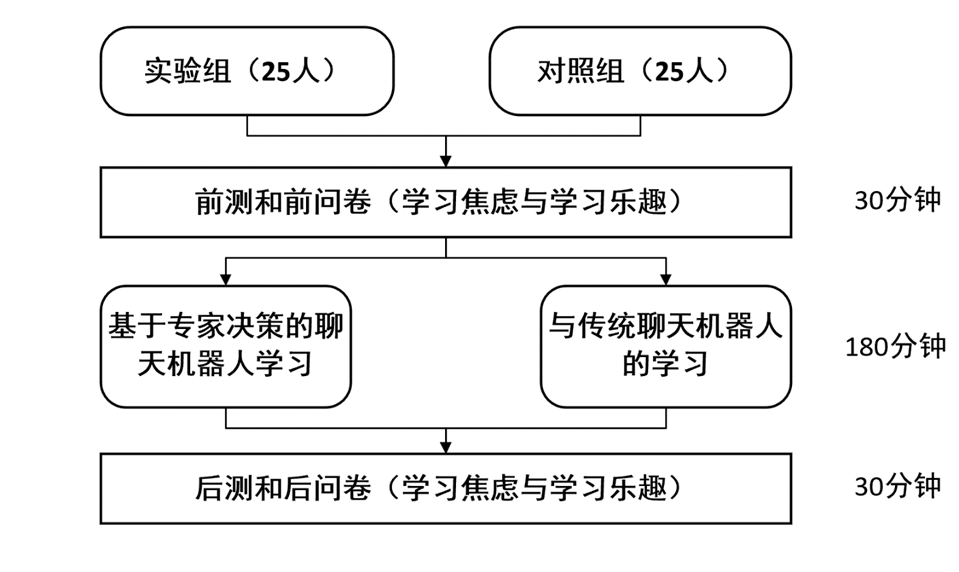
(二)实验对象
选取两个班的高中生,平均年龄17岁。一组(N = 35)为实验组,使用EDM聊天机器人;另一组(N = 35)为对照组,使用c聊天机器人。由同一个老师对两组学生进行教授。
(三)实验过程
四、研究结果
根据研究数据,首先采用Kolmogorov-Smirnov检验进行正态性检验;发现各组数据均不符合正态分布(即ShapiroWilk的p值均小于0.05)。因此,采用非参数分析的统计方法。
(一)学习成绩
首先采用Wilcoxon signed-rank检验比较各组学习成绩前测和后测的差异,如表3所示。结果显示,对照组学生后测学习成绩(M = 57.429, SD = 11.464)显著高于前测学习成绩(M = 53.143, SD = 12.071) (Z = -2.044*, p < 0.05)。同时,实验组后测学习成绩(M = 65.714, SD = 15.202)显著高于前测学习成绩(M = 57.143, SD = 23.082) (Z = -2.736**, p < 0.01)。因此,这两种系统都有助于自我学习。
表3两组学习成绩的威尔克科森检验结果

其次,采用Mann-Whitney U检验比较两组前测结果无显著差异。最后,再次进行Mann-Whitney U检验,比较两组的后测结果。结果发现,实验组的学习成绩(M = 65.714, SD = 15.202)显著优于对照组的学习成绩(M = 57.429, SD = 11.464) (U = 416.500, p < 0.05),见表4。
表4两组学习成绩后测的曼-惠特尼U检验结果

(二)学习焦虑
首先,采用Wilcoxon sign -rank检验比较两组学习焦虑前测和后测结果,见表5。结果显示,对照组焦虑前测(M = 3.083, SD = 0.439)与后测(M = 3.117, SD = 0.279)差异无统计学意义(Z = -0.432, p > 0.05)。实验组焦虑前测(M = 2.844, SD = 0.490)与后测(M = 2.390, SD = 0.611)差异有统计学意义(Z = -2.893**, p < 0.01)。因此,EDM聊天机器人有助于显著降低学生的学习焦虑。
表5两组学习焦虑的威尔克科森检验结果

其次,采用Mann-Whitney U检验比较两组学习焦虑前测结果无显著差异。最后,再次进行Mann-Whitney U检验,比较两组的学习焦虑后测结果。结果发现,实验组的学习焦虑(M = 2.390, SD = 0.611)显著低于对照组的学习焦虑(M =3.117, SD = 0.279) (U =216.500***, p < .001),见表6。
表6两组学习焦虑后测的曼-惠特尼U检验结果

(三)学习乐趣
首先,采用Wilcoxon符号秩检验比较各组学习乐趣前测和后测的差异,见表7。结果显示,对照组的享受后测(M = 2.790, SD = 0.801)显著低于前测(M = 3.419, SD = 0.711)(Z = -3.105**, p < 0.01)。这一发现表明,当学生使用c聊天机器人进行自我学习时,他们感受到的学习乐趣较低。实验组享受前测(M = 3.324, SD = 0.810)与享受后测(M = 3.343, SD = 0.865)差异无统计学意义(Z = 0.082, p > 0.05)。
表7两组学习乐趣的威尔克科森检验结果

其次,采用Mann-Whitney U检验比较两组学习享受前测结果无显著差异(U = 57万;Z = -0.524;(p > . 05)。最后,再次进行Mann-Whitney U检验,比较两组的学习后享受程度。结果发现,实验组的学习享受(M = 3.343, SD = 0.865)显著高于对照组的学习享受(M = 2.790, SD = 0.801) U = 404.000*, p < 0.05),见表8。
表8两组学习乐趣后测的曼-惠特尼U检验结果

五、结论
本研究利用IBM Watson构建了一个EDM聊天机器人,并将专家决策融入到多轮对话机制中,为学生提供自适应学习。在人工智能算法系统中,避免了与文化、宗教和性别相关的有偏见的词语,为学习者提供了一个公平的竞争环境,新的算法可以通过智能分析、诊断、预测、治疗和预防实现更接近人类的表现,为学生提供自适应学习(Yang, 2021)。实验结果表明,EDM聊天机器人在提高学生学习成绩、减少学习焦虑、增加学习乐趣方面比传统聊天机器人更有效。
尽管有积极的发现,但本研究仍有一些值得注意的局限性。
首先,如果学生的答案与手头的问题无关,聊天机器人可能不得不从头开始对话,这可能会让学生感到不耐烦。建议未来的研究首先收集学生在传统课堂上的学习成果和参与度,以便将学生使用e-learning结合AI机制进行自主学习的表现与教师在无法考虑任何个性化反应的传统课堂上教授的学生的表现进行比较。
其次,本研究仅在地理气候单元中使用聊天机器人,自我学习时间有限且教师并未对学生的学习进行干预。因此建议未来的研究在更长的时间内尝试针对不同学科和课程的聊天机器人的高交互性设计,教师在进一步的研究中可以成为一个独立变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号