实验6:文件实验编程
任务实验1:csv格式文件读写(使用python内置的文件操作)
task1.1:
1 title=['城市','人口(万)'] 2 info=[['南京','850'],['纽约','2300'],['东京','3800'],['巴黎','1000']] 3 with open('city1.csv','w',encoding='utf-8') as f: 4 f.write(','.join(title)+'\n') 5 for item in info: 6 f.write(','.join(item)+'\n')
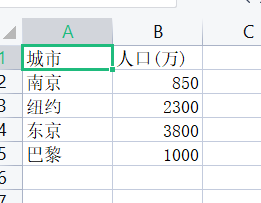
task1.2:
1 with open('city1.csv','r',encoding='utf-8') as f: 2 print(f.read().rstrip('\n'))

task1.3:
1 with open('city1.csv','r',encoding='utf-8') as f: 2 data=f.readlines() 3 print('data: ') 4 print(data) 5 6 info=[line.rstrip('\n').split(',') for line in data] 7 print('info: ') 8 print(info)

任务实验2:csv格式文件读写(使用python内置的csv模块)
task2.1:
1 import csv 2 title = ['城市', '人口(万)'] 3 info = [ ['南京', '850'], ['纽约', '2300'], ['东京', '3800'], ['巴黎', '1000'] ] 4 with open('city2.csv', 'w', encoding='utf-8', newline='') as f: 5 f_writer = csv.writer(f) 6 f_writer.writerow(title) 7 f_writer.writerows(info)
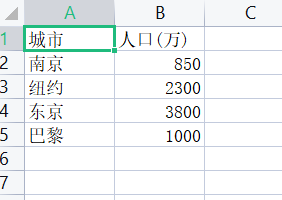
task2.2:
1 import csv 2 with open('city2.csv','r',encoding='utf-8') as f: 3 f_reader=csv.reader(f) 4 for line in f_reader: 5 print(line)

task2.3:
1 import csv 2 with open('city3.csv', 'w', encoding='utf-8', newline='') as f: 3 title = ['城市', '人口'] 4 f_writer = csv.DictWriter(f, fieldnames = title) 5 f_writer.writeheader() 6 f_writer.writerow({'城市':'南京', '人口': '850万'}) 7 f_writer.writerow({'城市':'纽约', '人口': '2300万'}) 8 f_writer.writerow({'城市':'东京', '人口': '3800万'}) 9 f_writer.writerow({'城市':'巴黎', '人口': '1000万'})
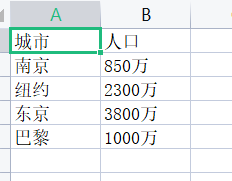
task2.4:
1 import csv 2 with open('city3.csv', 'r', encoding='utf-8') as f: 3 f_reader = csv.DictReader(f) 4 for line in f_reader: 5 print(line)

任务实验3:身份证号码文件批量处理
1 def is_valid(x): 2 if len(x)!=18: 3 return False 4 for i in x: 5 if not (i.isdigit() or i=='X'): 6 return False 7 else: 8 return True 9 with open('data3_id.txt','r',encoding='utf-8') as f: 10 data=f.readlines() 11 del data[0] 12 line=[i.rstrip('\n').split(',') for i in data] 13 valid=[] 14 for i in line: 15 if is_valid(i[1])==True: 16 valid.append(i) 17 name=[] 18 number=[] 19 l2=[] 20 for i in valid: 21 name.append(i[0]) 22 number.append(i[1]) 23 n1=[i[6:14] for i in number] 24 l1=list(zip(name,n1)) 25 for i in l1: 26 a=list(i) 27 l2.append(a) 28 l3=sorted(l2,key=(lambda x:x[1]),reverse=False) 29 for i in l3: 30 b=''.join(i) 31 print(f'{b[0:2]},{b[2:6]}-{b[6:8]}-{b[8:10]}')

任务实验4:random模块,datetime模块:


任务实验5:随机抽点
1 import random 2 x=list(range(1,81)) 3 n=int(input('请输入随机抽点人数:')) 4 with open('data5.txt','r',encoding='utf-8') as f: 5 data=f.readlines() 6 d1=[] 7 for i in data: 8 d1.append(i.strip('\n')) 9 d2=random.sample(d1,n) 10 11 for i in d2: 12 print(i) 13 import datetime 14 t=datetime.datetime.now() 15 f1=t.strftime('%Y%m%d')+'.txt' 16 with open(f1,'w',encoding='utf-8') as f: 17 for i in d2: 18 f.write(i+'\n')


1 import random 2 x=list(range(1,81)) 3 with open('data5.txt','r',encoding='utf-8') as f: 4 data=f.readlines() 5 d1=[] 6 for i in data: 7 d1.append(i.strip('\n')) 8 import datetime 9 t=datetime.datetime.now() 10 f1=t.strftime('%Y%m%d')+'.txt' 11 print('{:=^50}'.format('抽点开始')) 12 13 while True: 14 n=int(input('请输入随机抽点人数:')) 15 if n==0: 16 print('{:=^50}'.format('抽点结束')) 17 break 18 d2=(random.sample(d1,n)) 19 20 for i in d2: 21 d1.remove(i) 22 print(i) 23 with open(f1,'a',encoding='utf-8') as f: 24 for i in d2: 25 f.write(i+'\n')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号