Lock , Deadlock 和 Block的区别
Lock
当任何进程访问一个数据并且另一个并发进程也可能同时需要该数据时,将获得Lock。通过锁定数据,我们确保我们能够按照我们期望的方式对数据进行操作。
例如,如果我们读取数据,我们通常希望确保读取最新数据。如果我们更新数据,则需要确保没有其他进程在同一时间进行更新,等等。
锁定是SQL Server为了保护事务期间的数据完整性而使用的机制。
Block
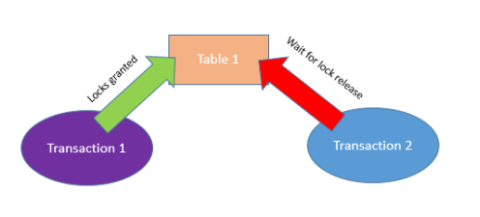
(或阻止锁)发生在两个进程需要同时访问同一数据段时,因此一个进程锁定数据,而另一个进程则需要等待另一个进程完成并释放锁。第一个过程完成后,被阻止的过程将立即恢复运行。阻塞链就像一个队列:阻塞过程完成后,接下来的过程可以继续。在正常的服务器环境中,不频繁的阻塞锁是可以接受的。但是,如果阻塞锁是常见的(而不是很少出现),则可能存在某种设计或查询实现问题,并且阻塞可能只是造成性能问题。
阻塞情况可能无法自行解决(即,如果阻塞过程未能正确完成事务),或者可能需要很长时间才能完成。在这些极端情况下,可能需要取消和/或重新设计阻塞过程。
DeadLock
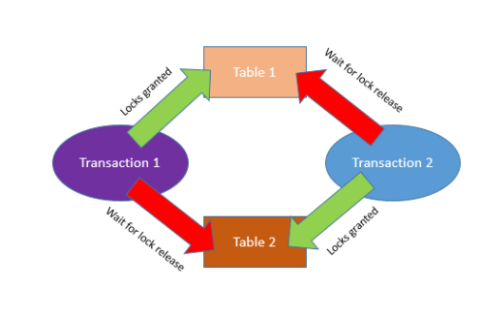
当一个进程被阻塞并等待第二个进程完成其工作并释放锁,而第二个进程同时被阻塞并等待第一个进程释放锁时,就会发生死锁。
在死锁情况下,进程之间已经相互阻塞,因此需要外部干预来解决死锁。因此,SQL Server具有死锁检测和解决机制,其中一个进程需要被选择为“死锁受害者”并被杀死,以便另一个进程可以继续工作。受害者进程收到非常具体的错误消息,表明它已被选择为死锁受害者,因此可以通过基于该错误消息的代码重新启动该进程。
本文介绍了SQL Server如何检测和解决死锁:死锁被认为是数据库世界中的一种严重情况,因为进程只是被自动杀死。可以并且应该避免死锁。死锁由SQL Server解决,不需要手动干预。
避免锁的设计策略:
此文描述了一些策略:
“有一些设计策略可以减少阻塞锁和死锁的发生:
- 在高使用率的表上使用聚簇索引。
- 避免可能导致表锁定的高行数SQL语句。例如,不要一次将一个表的所有行都插入到另一个表中,而是将一个INSERT语句放入循环中并一次插入一行。
- 将长交易分解为许多短交易。使用SQL Server,您可以使用“绑定连接”来控制较短事务的执行顺序。
- 确保UPDATE和DELETE语句使用现有索引。
- 如果使用嵌套事务,请确保没有提交或回滚冲突。
Youtub上有个讲解视频,比较简单明了:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号