
复旦大学暑期学校,晚上学习笔记
1:有一种除法是//,称为地板除,两个整数的除法仍然是整数。
2:Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 3
1
3:因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295
4:字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间
5:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
6:对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
1 >>> ord('A')
2 65
3 >>> ord('中')
4 20013
5 >>> chr(66)
6 'B'
7 >>> chr(25991)
8 '文'
7:由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
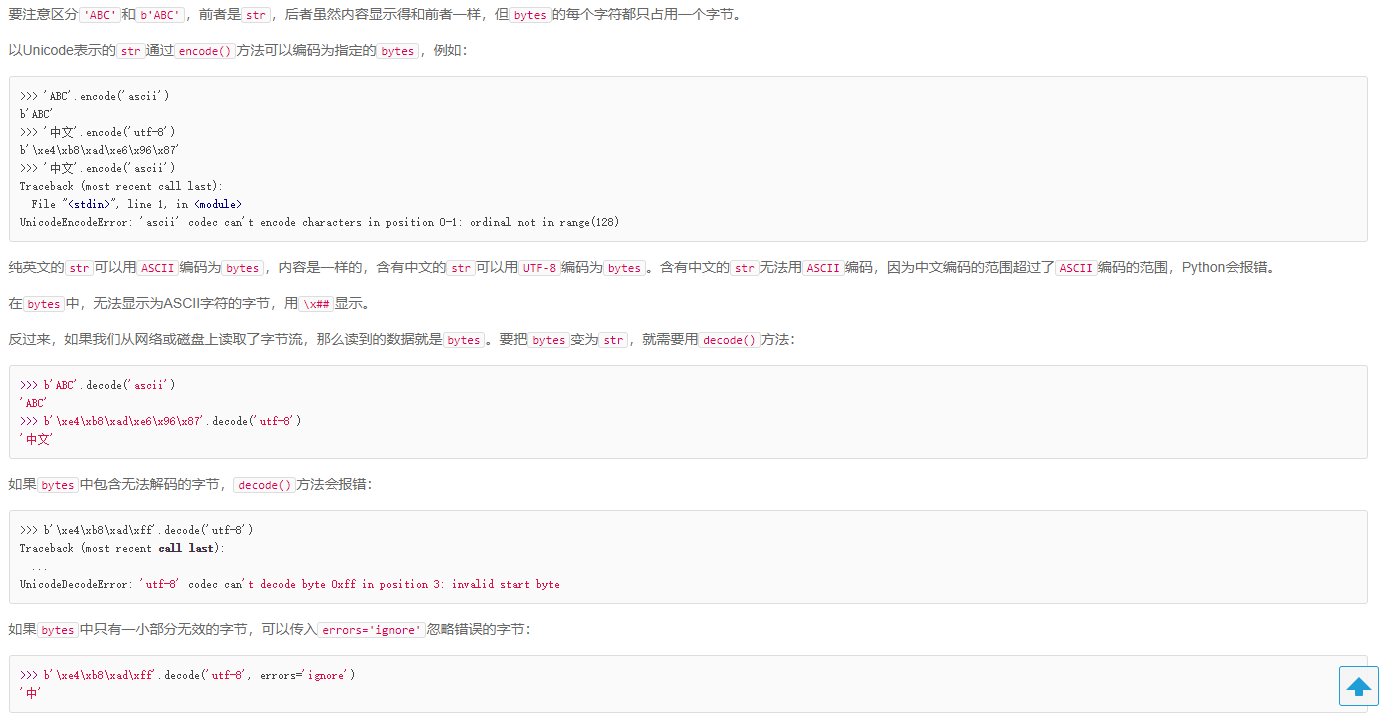
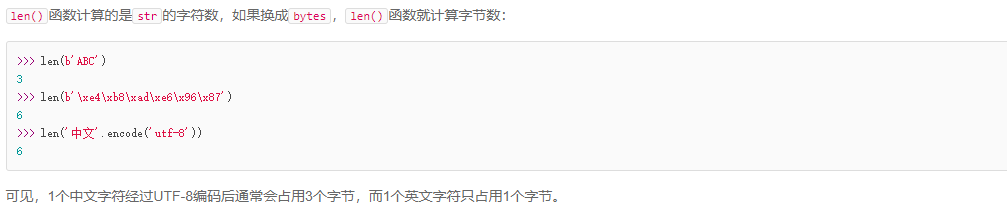
8:要计算str包含多少个字符,可以用len()函数:
1 >>> len('ABC')
2 3
3 >>> len('中文')
4 2

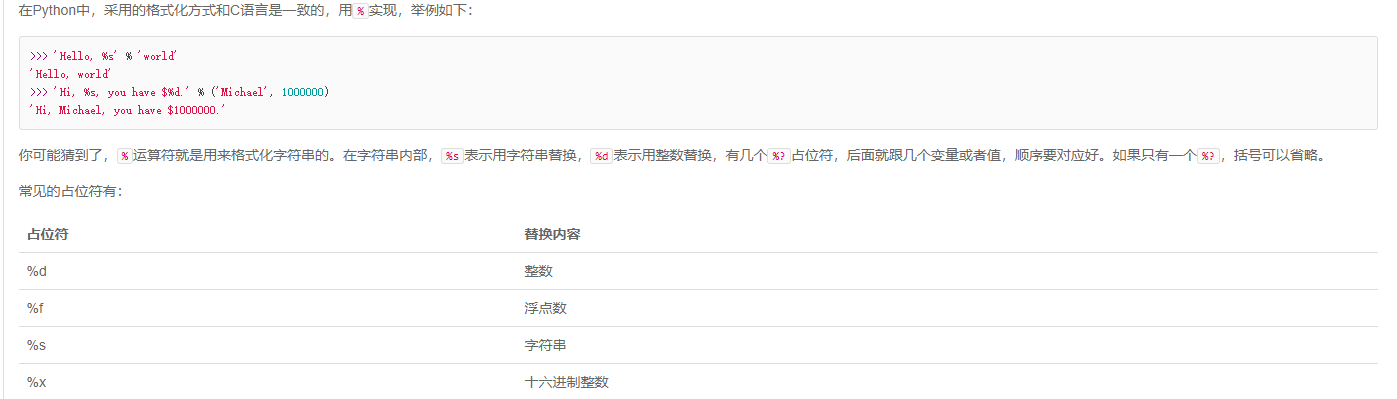
9:格式化
2019-07-3122:37:25 今日学完字符串与编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号