elasticsearch 查询超10000的几种解决方案
在es中,默认查询的 from + size 数量不能超过一万,官方对于超过1万的解决方案使用游标方案,今天介绍下几种方案,希望对你有用。
数据准备,模拟较大数据量,往es中灌入60w的数据,其中只有2个字段,一个seq,一个timestamp,如下图:

方案1:scroll 游标
游标方案中,我们只需要在第一次拿到游标id,之后通过游标就能唯一确定查询,在这个查询中通过我们指定的 size 移动游标,具体操作看看下面实操。
kibana
# 查看index的settings
GET demo_scroll/_settings
---
{
"demo_scroll" : {
"settings" : {
"index" : {
"number_of_shards" : "5",
"provided_name" : "demo_scroll",
"max_result_window" : "10000", # 窗口1w
"creation_date" : "1680832840425",
"number_of_replicas" : "1",
"uuid" : "OLV5W_D9R-WBUaZ_QbGeWA",
"version" : {
"created" : "6082399"
}
}
}
}
}
---
# 查询 from+size > 10000 的
GET demo_scroll/_search
{
"sort": [
{
"seq": {
"order": "desc"
}
}
],
"from": 9999,
"size": 10
}
---
{
"error": {
"root_cause": [
{
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10009]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "demo_scroll",
"node": "7u5oEE-kSoqXlxEHgDZd4A",
"reason": {
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10009]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status": 500
}
---
# 游标查询,设置游标有效时间,有效时间内,游标都可以使用,过期就不行了
GET demo_scroll/_search?scroll=5m
{
"sort": [
{
"seq": {
"order": "desc"
}
}
],
"size": 200
}
上面操作中通过游标的结果返回:
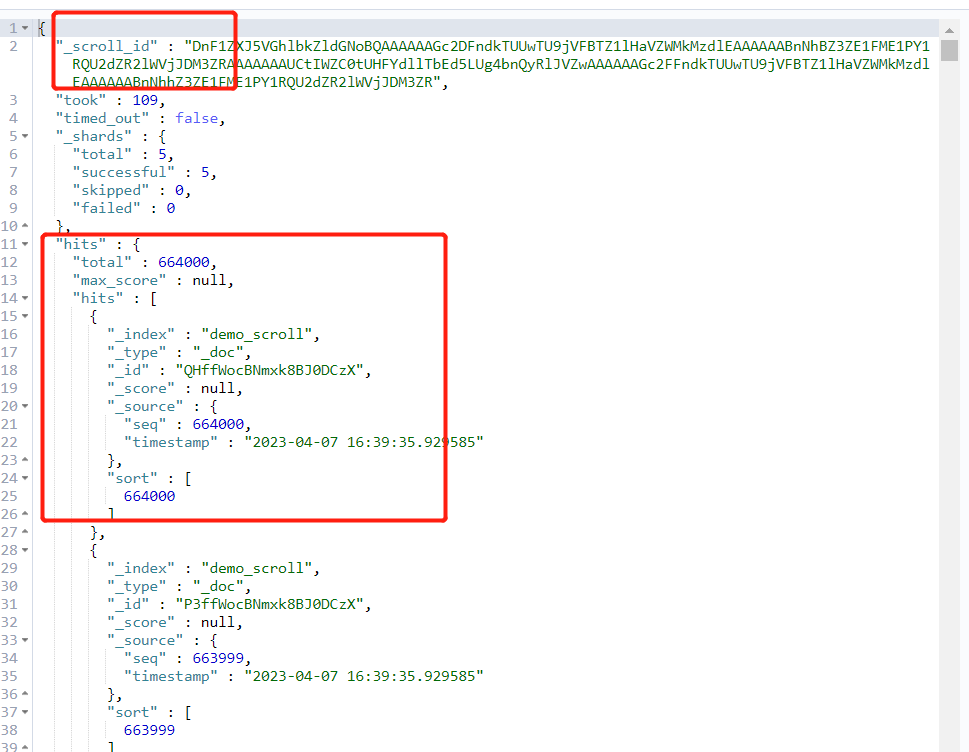
复制_scroll_id到查询窗口中:
GET _search/scroll
{
"scroll":"5m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAGc2DFndkTUUwTU9jVFBTZ1lHaVZWMkMzdlEAAAAAABnNhBZ3ZE1FME1PY1RQU2dZR2lWVjJDM3ZRAAAAAAAUCtIWZC0tUHFYdllTbEd5LUg4bnQyRlJVZwAAAAAAGc2FFndkTUUwTU9jVFBTZ1lHaVZWMkMzdlEAAAAAABnNhhZ3ZE1FME1PY1RQU2dZR2lWVjJDM3ZR"
}
以下是返回结果:
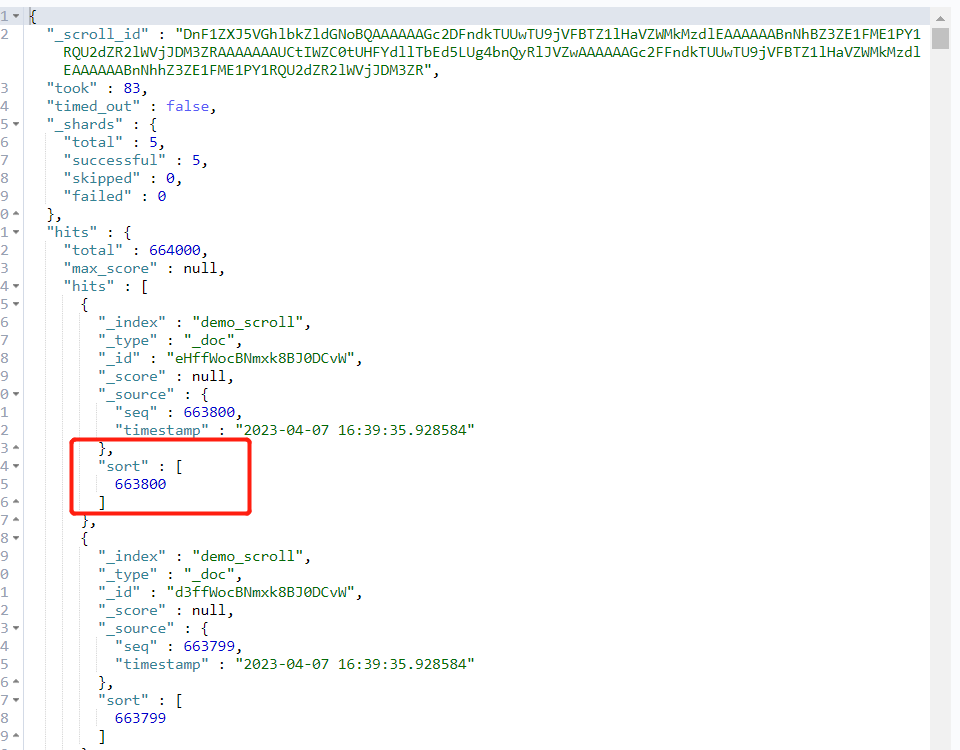
注意,此时游标移动了,所以我们可以通过游标的方式不断后移,直到移动到我们想要的 from+size 范围内。
看看python中实现:
python
def get_docs_by_scroll_v2(index, from_, size, scroll="10m"):
"""
:param index:
:param from_:
:param size:
:param scroll: scroll timeout, in timeout, the scroll is valid
:param timeout:
:return:
"""
query_scroll = {
"size": size,
"sort": {"seq": {"order": "desc"}},
"_source": ["seq"]
}
init_res = es.search(index=index, body=query_scroll, scroll=scroll, timeout=scroll)
scroll_id = init_res["_scroll_id"]
ans = []
for i in range(1, int(from_/size)+1, 1):
res = es.scroll(scroll_id=scroll_id, scroll=scroll)
if i == int(from_/size):
for item in res["hits"]["hits"]:
ans.append(item["_source"])
return ans
我们只需要通过size控制每次游标的移动范围,具体结果看实际需求。
游标确实可以帮我们获取到超1w的数据,但也有问题,就是如果分页相对深的时候,游标遍历的时间相对较长,下面介绍另外一种方案。
方案2:设置 max_result_size
在此方案中,我们建议仅限于测试用,生产禁用,毕竟当数据量大的时候,过大的数据量可能导致es的内存溢出,直接崩掉,一年绩效白干。
下面看看操作吧。
kibana
# 调大查询窗口大小,比如100w
PUT demo_scroll/_settings
{
"index.max_result_window": "1000000"
}
# 查看查询最大数
GET demo_scroll/_settings
---
{
"demo_scroll" : {
"settings" : {
"index" : {
"number_of_shards" : "5",
"provided_name" : "demo_scroll",
"max_result_window" : "1000000",
"creation_date" : "1680832840425",
"number_of_replicas" : "1",
"uuid" : "OLV5W_D9R-WBUaZ_QbGeWA",
"version" : {
"created" : "6082399"
}
}
}
}
}
---
# from+size > 10000 的查询
GET demo_scroll/_search
{
"from": 12000,
"size": 20,
"sort": [
{
"seq": {
"order": "desc"
}
}
]
}
下图为查询结果:
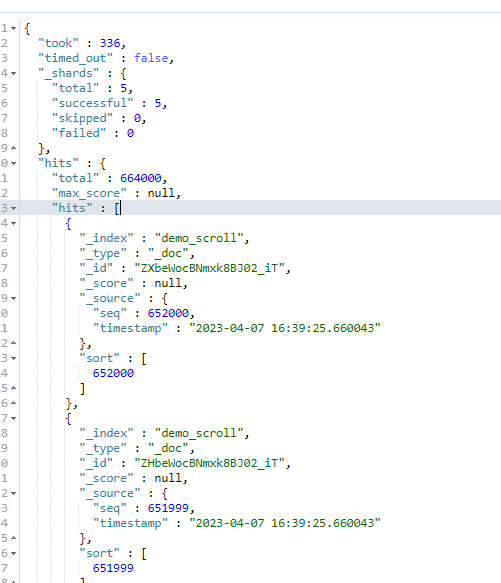
切记生产慎用,测试可用。
方法3:通过书签方式
用过关系型数据库都知道,假设我们有个 user 表,其中 id 为自增主键,在类似下面的 SQL 语句中:
select id, name from user limit 100000, 10;
如果你直接用这个语句查询,想想会不会被喷呢。涉及到较为深度的分页时,联系 mysql 的查询原理,首先查到那么多数据,只返回最后几条数据,浅分页影响小,深度分页,当数据量很大时,性能堪忧,所以通常我们可以这样优化下 SQL 语句:
select id, name from user where id > 100000 limit 10;
通过走索引的范围查找,相较于全表扫描式,性能肯定就更好了。
借鉴这种思路,还是以上面 es 中的索引数据,我们可以通过限定字段 seq 来作为书签进而分页。
具体思路,既然限制10000,我们可以10000接着10000去搜索,是不是也可以呢,到了最后在10000内的数据,再通过 from+size 就可以解决了。
比如我们跳过 skip = from/10000, 再接着 from+size。
# 在es默认的10000搜索范围内,下面查询报错
GET demo_scroll/_search
{
"from": 11000,
"size": 20,
"sort": [
{
"seq": {
"order": "asc"
}
}
]
}
# 解决上面查询,可以先查10000,在1000+20查询
GET demo_scroll/_search
{
"size": 10000,
"sort": [
{
"seq": {
"order": "asc"
}
}
]
}
GET demo_scroll/_search
{
"from": 1000,
"size": 20,
"sort": [
{
"seq": {
"order": "asc"
}
}
],
"query": {
"bool": {
"must": [
{"range": {
"seq": {
"gt": 10000
}
}}
]
}
}
}
当然如果是这个 skip 比较大,比如 from=31000,这个时候 skip=3,我们可以第一次拿到 seq,然后第二次通过 range 查询 seq > 10000,size=10000 保持不变,直到第三次,拿到第三次的 seq 的 30000分位的值,第四次在 from+size 中查询,这种思路在编码实现中可以通过循环实现,具体自己实现,也不难。
通过上面三种方法,我们就可以实现深度分页下的数据查询,游标方式查多少多可以,主要还是右边遍历的性能太差,建议通过 书签 方式实现,性能远比游标好,自己项目中的测试环境,数据量在5w内,查询2w多的数据,通过游标需要1min多,通过书签方式需要5秒,你品品。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号