python 实现索引生命周期管理-index_lifecycle_manage的简单应用
在elasticsearch 6.x后,出了一项功能叫做生命周期管理, index lifecycle manage,通过ilm可以实现索引数据的hot-warm-cold-delete,四种状态的管理,当然在实际应用中,这四种形态我们不一定都要用上,有的项目业务可能直接就是hot-delete两种状态,具体可以根据最大生存时间和最大文档数或者最大日志量确定执行ilm的rollover,但目前es的ilm功能尚不具备通过时间日期进行切分,通常来说切分的索引名类似于index_name-000001,后面切分的日志名在000001的基础上依次递增。
elasticsearch ilm官方文档点击这里
本文基于es 6.8做相关分享,python用到的es的库为elasticsearch,可以通过pip install elasticsearch下载该库。
接下来将按照python的编码实现ilm的初始化,示例文档,kibana的界面展示做分享。
1.python的ilm初始化
es 6.8以后提供了xpack的认证服务,另外对应的模板及ilm_policy也一并贴出。
url = "http://172.22.11.111:9200/"
auth = ("user", "password")
es_template = {
"index_patterns": ["demo_log*"], # 通过模板关联的索引
"settings": {
"number_of_shards": 3, # 如果是集群,建议与集群data节点数保持一致
"number_of_replicas": 1, # 副本分片数
"priority": 10, # 优先级
"index.lifecycle.name": "demo", # ilm name
"index.lifecycle.rollover_alias": "demo_log" # rollover别名,一定要设置
}
}
LIFECYCLE_POLICY_URL = "_ilm/policy/demo" # policy的name即为demo
ILM_POLICY= {
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "20m", # 为方便看得到效果,设置最大时间20min,文档数10
"max_docs": "10"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "1d",
"actions": {
"readonly": {},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"freeze": {}
}
},
"delete": {
"min_age": "3d",
"actions": {
"delete": {}
}
}
}
}
}
es中先设置相关模板,然后添加索引别名,最后设置ilm。
es的ilm初始化代码:
class ESORM:
def __init__(self):
self.client = Elasticsearch(hosts=url, http_auth=auth, timeout=120)
self.init_es_template()
self.init_alias()
self.init_ilm()
def init_es_template(self):
if not self.client.indices.exists_template(name="demo_business"):
self.client.indices.put_template(name="demo_business", body=es_template)
print "es template: demo_business has init success!"
def init_alias(self):
if not self.client.indices.get_alias(index="demo_businesslog*"):
self.client.indices.create(index="demo_businesslog-" +str(datetime.datetime.now()).split(" ")[0]+ "-000001")
self.client.indices.put_alias(index="demo_businesslog*", name="demo_businesslog", body={"is_write_index": True})
print "es alias settings has init success!"
def init_ilm(self):
policy_url = url + LIFECYCLE_POLICY_URL
resp = requests.get(policy_url, timeout=30, auth=auth)
if resp.status_code == 200:
print "ilm policy has init!"
return
resp = requests.put(policy_url, json=ILM_POLICY, auth=auth)
if resp.status_code == 200:
print "es ilm policy init success!"
2.准备索引数据
因为都在一个class中实现,本段代码只贴出数据部分:
...
def prepare_body(self):
body = {
"name": random.choice(["zhangsan", "lisi", "wangwu", "zhaoliu"]) + "_" + random.choice([str(i) for i in range(10000)]),
"timestamp": int(time.time()),
"@timestamp": str(datetime.datetime.now())
}
return body
def add(self, index=None, body=None, doc_id=None):
body = self.prepare_body()
index = "demo_log"
self.client.index(index=index, document=body, doc_type="_doc")
接下来初始化ilm,上传index的数据:
if __name__ == "__main__":
es = ESORM()
for i in range(100000): # 搞个循环一直po数据
es.add()
print "add doc, seq is: %d" % (i+1)
time.sleep(60)
3.kibana界面效果
查看模板
GET _template/demo_business

查看别名
GET _alias/demo_businesslog

查看ilm
GET _ilm/policy/demo
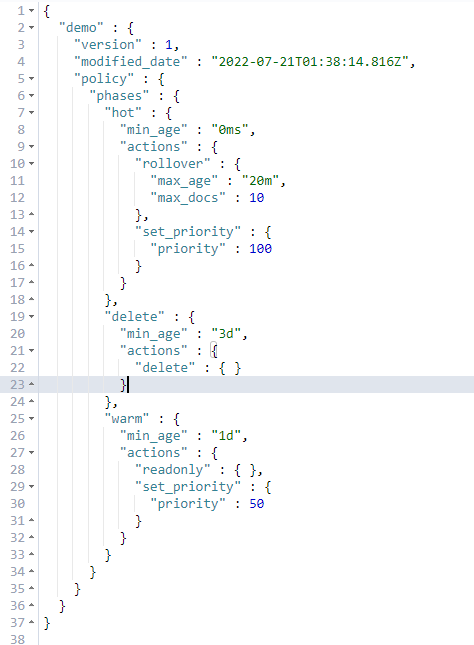
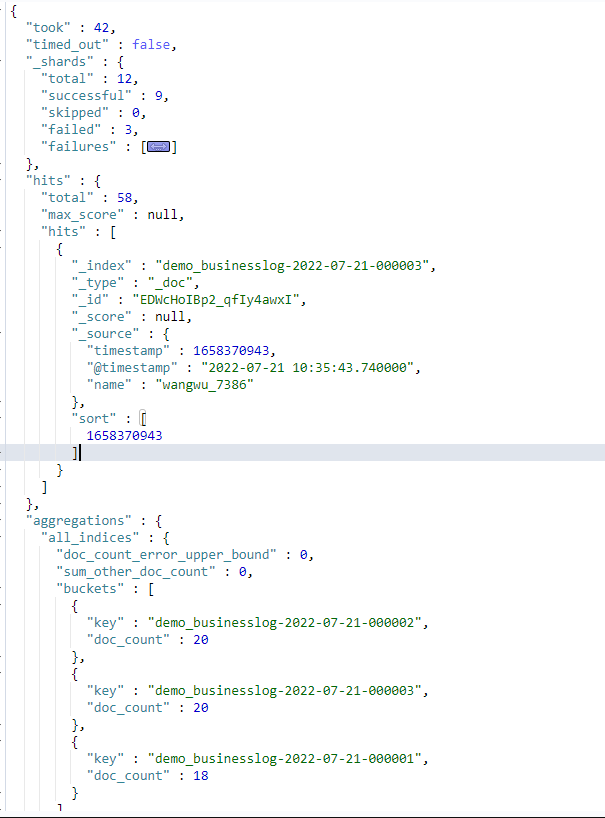
通过索引别名查看index数据及聚合index_name
从下图可以看到,es的ilm机制已经把我们实现了index的滚动
GET demo_businesslog/_search
{
"size": 1,
"sort": [
{
"timestamp": {
"order": "desc"
}
}
],
"aggs": {
"all_indices": {
"terms": {
"field": "_index",
"size": 1000
}
}
}
}
查看ilm的状态信息
GET demo_businesslog/_ilm/explain

最后,通过简单的实践,我们在python应用中成功地实现了es的ilm机制,如果业务项目有需求就用起来吧,毕竟单个索引如果很庞大,并非好事。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号