1.概述
Flink支持有状态计算,根据支持得不同状态类型,分别有Keyed State和Operator State。针对状态数据得持久化,Flink提供了Checkpoint机制处理;针对状态数据,Flink提供了不同的状态管理器来管理状态数据,如MemoryStateBackend。
上面Flink的文章中,有引用word count的例子,但是都没有包含状态管理。也就是说,如果一个task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。
从容错和消息处理的语义上(at least once, exactly once),Flink引入了state和checkpoint。
首先区分一下两个概念,state一般指一个具体的task/operator的状态。而checkpoint则表示了一个Flink Job,在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态。
所谓checkpoint,就是在某一时刻,将所有task的状态做一个快照(snapshot),然后存储到memory/file system/rocksdb等。Flink通过定期地做checkpoint来实现容错和恢复。
2.checkpoint的实现CheckpointedFunction
CheckpointedFunction的描述
/** * This is the core interface for <i>stateful transformation functions</i>, meaning functions * that maintain state across individual stream records. * While more lightweight interfaces exist as shortcuts for various types of state, this interface offer the * greatest flexibility in managing both <i>keyed state</i> and <i>operator state</i>. * * <p>The section <a href="#shortcuts">Shortcuts</a> illustrates the common lightweight * ways to setup stateful functions typically used instead of the full fledged * abstraction represented by this interface. * * <h1>Initialization</h1> * The {@link CheckpointedFunction#initializeState(FunctionInitializationContext)} is called when * the parallel instance of the transformation function is created during distributed execution. * The method gives access to the {@link FunctionInitializationContext} which in turn gives access * to the to the {@link OperatorStateStore} and {@link KeyedStateStore}. * * <p>The {@code OperatorStateStore} and {@code KeyedStateStore} give access to the data structures * in which state should be stored for Flink to transparently manage and checkpoint it, such as * {@link org.apache.flink.api.common.state.ValueState} or * {@link org.apache.flink.api.common.state.ListState}. * * <p><b>Note:</b> The {@code KeyedStateStore} can only be used when the transformation supports * <i>keyed state</i>, i.e., when it is applied on a keyed stream (after a {@code keyBy(...)}). * * <h1>Snapshot</h1> * The {@link CheckpointedFunction#snapshotState(FunctionSnapshotContext)} is called whenever a * checkpoint takes a state snapshot of the transformation function. Inside this method, functions typically * make sure that the checkpointed data structures (obtained in the initialization phase) are up * to date for a snapshot to be taken. The given snapshot context gives access to the metadata * of the checkpoint. * * <p>In addition, functions can use this method as a hook to flush/commit/synchronize with * external systems. * * <h1>Example</h1> * The code example below illustrates how to use this interface for a function that keeps counts * of events per key and per parallel partition (parallel instance of the transformation function * during distributed execution). * The example also changes of parallelism, which affect the count-per-parallel-partition by * adding up the counters of partitions that get merged on scale-down. Note that this is a * toy example, but should illustrate the basic skeleton for a stateful function. * * <p><pre>{@code * public class MyFunction<T> implements MapFunction<T, T>, CheckpointedFunction { * * private ReducingState<Long> countPerKey; * private ListState<Long> countPerPartition; * * private long localCount; * * public void initializeState(FunctionInitializationContext context) throws Exception { * // get the state data structure for the per-key state * countPerKey = context.getKeyedStateStore().getReducingState( * new ReducingStateDescriptor<>("perKeyCount", new AddFunction<>(), Long.class)); * * // get the state data structure for the per-partition state * countPerPartition = context.getOperatorStateStore().getOperatorState( * new ListStateDescriptor<>("perPartitionCount", Long.class)); * * // initialize the "local count variable" based on the operator state * for (Long l : countPerPartition.get()) { * localCount += l; * } * } * * public void snapshotState(FunctionSnapshotContext context) throws Exception { * // the keyed state is always up to date anyways * // just bring the per-partition state in shape * countPerPartition.clear(); * countPerPartition.add(localCount); * } * * public T map(T value) throws Exception { * // update the states * countPerKey.add(1L); * localCount++; * * return value; * } * } * }</pre> * * <hr> * * <h1><a name="shortcuts">Shortcuts</a></h1> * There are various ways that transformation functions can use state without implementing the * full-fledged {@code CheckpointedFunction} interface: * * <h4>Operator State</h4> * Checkpointing some state that is part of the function object itself is possible in a simpler way * by directly implementing the {@link ListCheckpointed} interface. * That mechanism is similar to the previously used {@link Checkpointed} interface. * * <h4>Keyed State</h4> * Access to keyed state is possible via the {@link RuntimeContext}'s methods: * <pre>{@code * public class CountPerKeyFunction<T> extends RichMapFunction<T, T> { * * private ValueState<Long> count; * * public void open(Configuration cfg) throws Exception { * count = getRuntimeContext().getState(new ValueStateDescriptor<>("myCount", Long.class)); * } * * public T map(T value) throws Exception { * Long current = count.get(); * count.update(current == null ? 1L : current + 1); * * return value; * } * } * }</pre> * * @see ListCheckpointed * @see RuntimeContext */
2.1. 它的snapshotState调用过程如下:
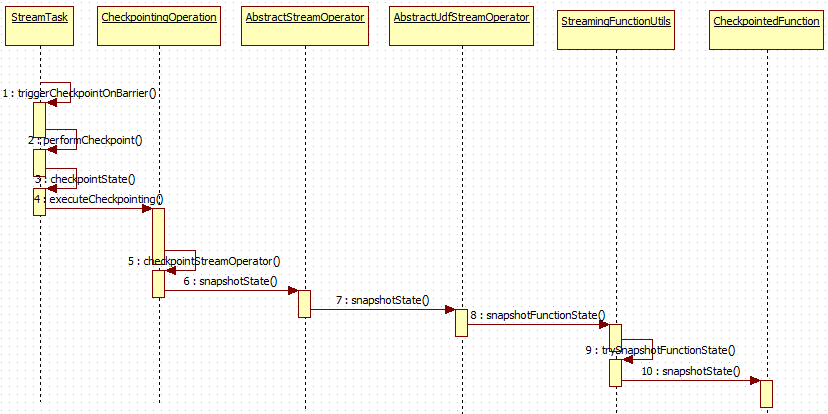
核心类StreamTask
/** * Base class for all streaming tasks. A task is the unit of local processing that is deployed * and executed by the TaskManagers. Each task runs one or more {@link StreamOperator}s which form * the Task's operator chain. Operators that are chained together execute synchronously in the * same thread and hence on the same stream partition. A common case for these chains * are successive map/flatmap/filter tasks. * * <p>The task chain contains one "head" operator and multiple chained operators. * The StreamTask is specialized for the type of the head operator: one-input and two-input tasks, * as well as for sources, iteration heads and iteration tails. * * <p>The Task class deals with the setup of the streams read by the head operator, and the streams * produced by the operators at the ends of the operator chain. Note that the chain may fork and * thus have multiple ends. * * <p>The life cycle of the task is set up as follows: * <pre>{@code * -- setInitialState -> provides state of all operators in the chain * * -- invoke() * | * +----> Create basic utils (config, etc) and load the chain of operators * +----> operators.setup() * +----> task specific init() * +----> initialize-operator-states() * +----> open-operators() * +----> run() * +----> close-operators() * +----> dispose-operators() * +----> common cleanup * +----> task specific cleanup() * }</pre> * * <p>The {@code StreamTask} has a lock object called {@code lock}. All calls to methods on a * {@code StreamOperator} must be synchronized on this lock object to ensure that no methods * are called concurrently. * * @param <OUT> * @param <OP> */
2.2.它的initializeState调用过程如下:
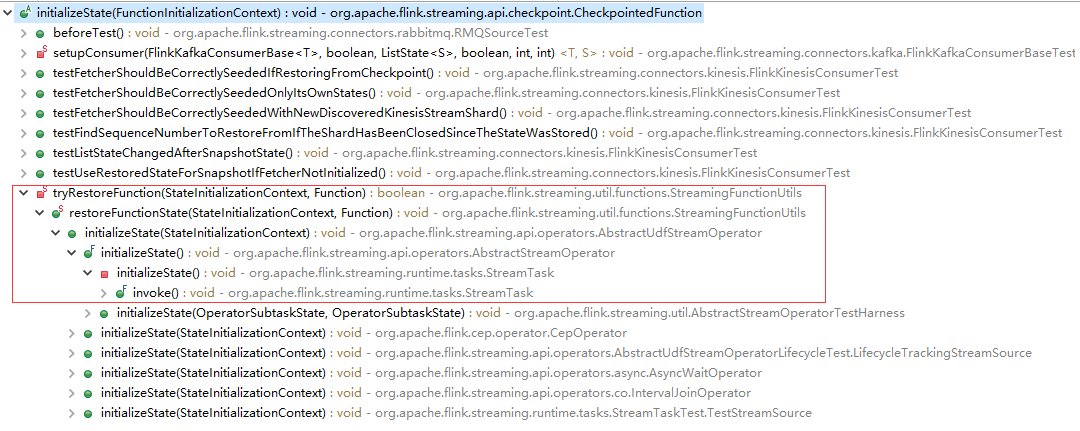
3.checkpoint的状态管理器StateBackend
StateBackend
/** * A <b>State Backend</b> defines how the state of a streaming application is stored and * checkpointed. Different State Backends store their state in different fashions, and use * different data structures to hold the state of a running application. * * <p>For example, the {@link org.apache.flink.runtime.state.memory.MemoryStateBackend memory state backend} * keeps working state in the memory of the TaskManager and stores checkpoints in the memory of the * JobManager. The backend is lightweight and without additional dependencies, but not highly available * and supports only small state. * * <p>The {@link org.apache.flink.runtime.state.filesystem.FsStateBackend file system state backend} * keeps working state in the memory of the TaskManager and stores state checkpoints in a filesystem * (typically a replicated highly-available filesystem, like <a href="https://hadoop.apache.org/">HDFS</a>, * <a href="https://ceph.com/">Ceph</a>, <a href="https://aws.amazon.com/documentation/s3/">S3</a>, * <a href="https://cloud.google.com/storage/">GCS</a>, etc). * * <p>The {@code RocksDBStateBackend} stores working state in <a href="http://rocksdb.org/">RocksDB</a>, * and checkpoints the state by default to a filesystem (similar to the {@code FsStateBackend}). * * <h2>Raw Bytes Storage and Backends</h2> * * The {@code StateBackend} creates services for <i>raw bytes storage</i> and for <i>keyed state</i> * and <i>operator state</i>. * * <p>The <i>raw bytes storage</i> (through the {@link CheckpointStreamFactory}) is the fundamental * service that simply stores bytes in a fault tolerant fashion. This service is used by the JobManager * to store checkpoint and recovery metadata and is typically also used by the keyed- and operator state * backends to store checkpointed state. * * <p>The {@link AbstractKeyedStateBackend} and {@link OperatorStateBackend} created by this state * backend define how to hold the working state for keys and operators. They also define how to checkpoint * that state, frequently using the raw bytes storage (via the {@code CheckpointStreamFactory}). * However, it is also possible that for example a keyed state backend simply implements the bridge to * a key/value store, and that it does not need to store anything in the raw byte storage upon a * checkpoint. * * <h2>Serializability</h2> * * State Backends need to be {@link java.io.Serializable serializable}, because they distributed * across parallel processes (for distributed execution) together with the streaming application code. * * <p>Because of that, {@code StateBackend} implementations (typically subclasses * of {@link AbstractStateBackend}) are meant to be like <i>factories</i> that create the proper * states stores that provide access to the persistent storage and hold the keyed- and operator * state data structures. That way, the State Backend can be very lightweight (contain only * configurations) which makes it easier to be serializable. * * <h2>Thread Safety</h2> * * State backend implementations have to be thread-safe. Multiple threads may be creating * streams and keyed-/operator state backends concurrently. */
4.Savepoint
Savepoint是Checkpoint的一种特殊实现,底层也是使用Checkpoint的机制。Savepoint是用户以手工命令的方式触发Checkpoint并将结果持久化到指定的存储里,其主要目的是帮助用户在升级和维护集群过程中保存系统的状态数据,避免因停机或者升级邓正常终止应用的操作而导致系统无法恢复到原有的计算状态,而无法实现Exactly-Once的语义保证。
/** * Savepoints are manually-triggered snapshots from which a program can be * resumed on submission. * * <p>In order to allow changes to the savepoint format between Flink versions, * we allow different savepoint implementations (see subclasses of this * interface). * * <p>Savepoints are serialized via a {@link SavepointSerializer}. */
5.Querable State
Queryable State,顾名思义,就是可查询的状态,表示这个状态,在流计算的过程中就可以被查询,而不像其他流计算框架,需要存储到外部系统中才能被查询。目前可查询的state主要针对partitionable state,如keyed state等。
简单来说,当用户在job中定义了queryable state之后,就可以在外部,通过QueryableStateClient,通过job id, state name, key来查询所对应的状态的实时的值。
5.1 QueryableStateClient
QueryableStateClient
/** * Client for querying Flink's managed state. * * <p>You can mark state as queryable via {@link StateDescriptor#setQueryable(String)}. * The state instance created from this descriptor will be published for queries when it's * created on the Task Managers and the location will be reported to the Job Manager. * * <p>The client connects to a {@code Client Proxy} running on a given Task Manager. The * proxy is the entry point of the client to the Flink cluster. It forwards the requests * of the client to the Job Manager and the required Task Manager, and forwards the final * response back the client. * * <p>The proxy, initially resolves the location of the requested KvState via the JobManager. Resolved * locations are cached. When the server address of the requested KvState instance is determined, the * client sends out a request to the server. The returned final answer is then forwarded to the Client. */
其查询的实现
/** * Returns a future holding the serialized request result. * * @param jobId JobID of the job the queryable state * belongs to * @param queryableStateName Name under which the state is queryable * @param keyHashCode Integer hash code of the key (result of * a call to {@link Object#hashCode()} * @param serializedKeyAndNamespace Serialized key and namespace to query * KvState instance with * @return Future holding the serialized result */ private CompletableFuture<KvStateResponse> getKvState( final JobID jobId, final String queryableStateName, final int keyHashCode, final byte[] serializedKeyAndNamespace) { LOG.debug("Sending State Request to {}.", remoteAddress); try { KvStateRequest request = new KvStateRequest(jobId, queryableStateName, keyHashCode, serializedKeyAndNamespace); return client.sendRequest(remoteAddress, request); } catch (Exception e) { LOG.error("Unable to send KVStateRequest: ", e); return FutureUtils.getFailedFuture(e); } }
通过组装request,然后使用client发送请求
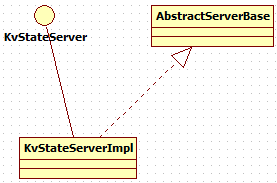
5.2 KvStateServer
KvStateServer
/** * An interface for the Queryable State Server running on each Task Manager in the cluster. * This server is responsible for serving requests coming from the {@link KvStateClientProxy * Queryable State Proxy} and requesting <b>locally</b> stored state. */
6. 总结
为什么要使用状态?
数据之间有关联,需要通过状态满足业务逻辑
为什么要管理状态?
实时计算作业需要7*24运行,需要应对不可靠因素带来的影响
如何选择状态的类型和存储方式?
分析自己的业务场景,比对各方案的利弊,选择合适的,够用即可
参考资料:
【1】https://yq.aliyun.com/articles/225623#
【2】https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/stream/state/
【3】https://blog.csdn.net/alexdamiao/article/details/94043468

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号