https://tech.youzan.com/realtime_customer_data_collection/
背景
有赞会员系统主要承载着有赞的客户经营领域,致力于给商家提供全渠道客户经营的能力。随着社交网络的普及,其社会化、多元化和创新化特质让商家与消费者之间的联系方式更加丰富,互动更加频繁,相应的运营需求也大大增加。除了传统的会员经营手段之外,会员系统需要提供能力,来帮助商家定义客户的生命周期,构建精准的消费画像:商家可以由此全面、及时地了解客户的喜好、行为轨迹、消费能力等属性,定义进而进行差异化的客户经营。我们需要构建一套实时的客户行为收集处理系统,来满足上述业务需求。本文就简单聊聊客户行为收集系统的设计。
行为模型
我们把客户行为事件定义为客户与业务系统间的交互,客户行为事件模型则描述了客户在业务系统中的轨迹。它记录了某个业务场景下一类或多类的客户行为事件,并能够反映事件的先后顺序。通过对客户事件的研究,我们可以评估客户事件的发生以及它对企业价值的影响程度,预测相关事件的发生;或通过追踪客户行为或业务过程,研究与事件发生关联的所有因素,来挖掘用户行为事件背后的原因、交互影响等。
对于客户行为事件,除客户本身的标识外,我们还要定义关注的事件的业务属性(如点击商品事件中的商品信息、下单下单商品及交易属性等),以及事件窗口的长度。其实体关系大致描述如下:
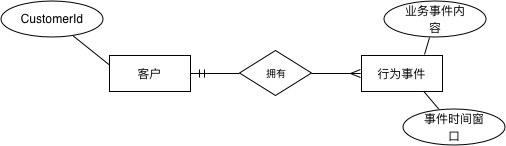
逻辑架构
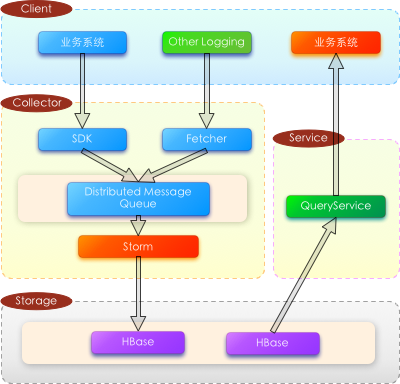
逻辑架构共分为三层:
- 客户端 (Client)
客户端主要包括两类角色:一是客户行为事件的产生源,另一类是客户行为的输出方。
- 收集器 (Collector)
收集器的主要职责是从客户端获取客户事件,并按照行为模型的定义转换数据格式。考虑到客户端的差异,收集器需要支持“推”和“拉”两种模式
- 推模式:由收集器提供收集接口,由客户端调用;或客户端嵌入SDK的方式,将行为事件推送给收集器
- 拉模式:由收集器通过定时任务或消息队列,从业务方系统获取客户事件
获取到客户事件之后,收集器根据预设或自定义的路由规则,将事件发布到分布式队列服务中。在有赞我们使用的是 NSQ (关于NSQ,可以移步重塑NSQ之路 系列了解更多详情)。
队列的消费端是流式计算引擎,通过引擎处理,最终将事件数据发送给存储层。
- 存储层 (Storage)
存储层会根据业务需要选择MySQL或者HBase来事件数据的持久化。目前我们使用的是HBase,主要考虑因素是:1. HBase具有相对灵活的Schema 2. 与Hadoop集群的集成的便捷,使得事件数据不仅仅能够支持实时处理,也能轻松地用于离线分析。
- 服务层 (Service)
服务层用以支撑客户端/外部系统对于客户行为的查询,目前只支持以随机读。
数据流
整个客户行为收集系统主要有两个方向的数据流:
- 处理流
处理流将来自各个系统(包括业务系统、H5页/App等)的客户行为,按照行为模型定义的消息格式,发布到分布式队列服务 (NSQ) ,由流式计算框架 (Storm) 对消息进行消费,并持久化到存储层 (HBase或MySQL) 中。
- 输出流
输出流的逻辑相对简单,将存储的客户行为从存储层读取出来,通过查询服务提供给使用方。目前我们的使用场景只涉及到随机读取。另外如果需要在离线分析(如 Hive)中使用的话,则可以通过Hive的 External Table 集成。
系统设计要求
实时性
作为客户行为收集系统,实时性越高,对于商家就能够更为及时地挖掘客户特征、进行实时推荐或发现一些突发的状况。因此,实时性是该系统的重要非功能性指标之一。在构建实时系统时,我们常常需要解决如下问题:
- 突发的流量
- 部分组件故障导致大量消息需要重试
- 数据积压
- 业务逻辑的bug需要进行数据的重新处理
我们引入了Storm作为支撑整个客户行为系统实时性的组件。Storm作为最早的开源分布式实时计算框架,被行业广泛地应用于生产环境。它能够支持到消息粒度的控制与处理,具有很好的容错性、扩展性;从模型上来说,Storm的Continueous Streaming模型相对于Micro Batch模型能够满足更严格的时延要求(当然相对更低的时延的带来了更高的开销,在吞吐方面的表现较Micro Batch模型逊色)。
Storm的向外扩展 (Scale Out) 能力强大,能够通过调节worker数量并重启Topology (拓扑,Storm的计算任务)来完成计算能力的扩展。
当有基础组件发生故障时,Storm Topology 的对应部分(Spout/Bolt)无法在 TOPOLOGY.MESSAGE.TIMEOUT内处理完消息,会触发Storm的重试;如果短时间内重试消息过多,势必会影响新生产的消息的消费,从而造成数据的延迟。因此,我们使用两组Topic来应对这种场景。
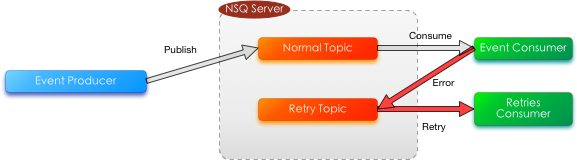
如上图所示,正常的生产客户行为事件消息由生产者发布到 Normal Topic,由对应的Storm Spout来消费。当Topology的部分业务异常时,会触发到Spout的失败处理,此时Spout将消息publish到 Retry Topic ,由重试的Spout按照一定的策略进行重试;或者在超过一定重试次数后,Ack此消息,并发布一个延时的离线补偿任务进行该业务单元的全量计算。下图展示了一种重试的策略。
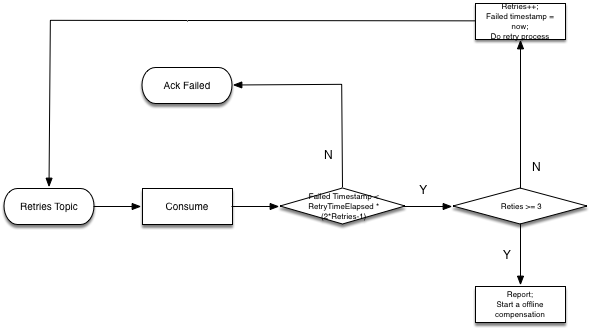
对于需要重新处理数据的场景,我们可以使用分布式队列服务的消息重放功能,由Spout进行重新消费。
消息抵达保证
Storm 本身支持多种消息抵达保证的语义:通过 Acker 和 Reliability API 来实现 At Least Once 语义;通过 Trident 来实现 Exactly Once 语义。对于消息抵达,我们有如下几个要求:
1. 业务对于实时数据的要求是保证消息不丢失
2. 部分业务场景需要我们支持 Exactly Once 语义。
此外,作为Storm的Source,NSQ本身会保证消息一定推给consumer —— 即在极小的机率下NSQ Server会重复推送消息给Consumer。综合上述情况,结合前面提到的多种重试场景的支持,我们使用 At Least Once 语义,而由具体的处理逻辑来保证幂等性。
public class NSQSpout extends BaseRichSpout {
public void nextTuple() {
String messageId = UUID.randomUUID().toString();
try {
...
// 消息处理逻辑
this.collector.emit("stream_id", new Values(message), messageId);
} catch (Exception e) {
logger.error("Emit message failed. ", e);
}
}
@Override
public void ack(Object msgId) {
// Get origin NSQMessage and finish it
try {
this.consumer.finish(NSQMessage message);
} catch(NSQException e) {
logger.error("Failed to ack message. id: {}", msgId, e);
}
}
@Override
public void fail(Object msgId) {
logger.info("msg failed: {}", msgId);
// 按照重试策略处理
}
}
public class BizBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
}
@Override
public void execute(Tuple tuple) {
Object obj = tuple.getValues();
// Do your business
...
this.collector.emit("another-stream-id", tuple, new Values(obj));
this.collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
// 声明bolt的输出
outputFieldsDeclarer.declareStream("log-stream", new Fields("content"));
}
}
存储
我们主要选择HBase来存储客户的行为。在HBase中,是通过Rowkey, ColumnFamily+Qualifier及Timestamp来定位数据的。Rowkey作为唯一标识,在设计业务表Schema时主要需要考虑以下几点:
- 长度:尽可能短,HBase的持久化文件HFile是按照Key-Value存储的,如果Rowkey过长,会影响HFile的存储效率。
-
散列:针对随机读取的场景,需要散列Rowkey来避免查询热点集中到一个RegionServer上。我们采用了两种方式:
- 随机化(如MD5)
- 当Rowkey中需要保存递增的序列(如:时间戳),同时要求Rowkey可读时。可将其他的ID(如:客户ID)截取后N位+递增序列拼接成Rowkey 。一种参考的实现方式如下。
// 方式一
byte[] rowkey = MessageDigest.getInstance("MD5").digest(identifier.getBytes());
// 方式二
byte[] rowkey = String.format("%08d%d", prefix, timestamp).getBytes();
- 唯一性:在该业务上必须是唯一的。
部署
Storm Topology的部署相当容易,只需要上传新的JAR包即可。NSQ Server保存了Consumer当前的Offset,只要我们通过相同的Consumer Name (Channel) 重连NSQ Server,即可获得之前消费的Offset。当然,如果需要强制重新消费,调整对应Channel的Offset即可。
总结
实时系统能够有效弥补离线"T+1"的短板,同时也有更为严格的时效性和容错要求,其实时性、可用性、可扩展性各个方面值得去仔细推敲和打磨。支撑更多的业务场景,改善数据收集效率是我们持续改进的动力,欢迎有兴趣的同学勾搭。 liyumeng@youzan.com
参考资料
- https://storm.apache.org/releases/1.0.2/Guaranteeing-message-processing.html
- https://community.hortonworks.com/articles/550/unofficial-storm-and-kafka-best-practices-guide.html
- https://hbase.apache.org/0.94/book/rowkey.design.html
- https://storm.apache.org/releases/1.0.2/Acking-framework-implementation.html

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号