王富平
现为1号店搜索与精准化部门架构师,之前在百度从事数据挖掘相关工作,对实时处理有着深刻的研究。一直从事大数据相关研发工作,2013年开发了一款SQL实时处理框架,致力于建设高可用的大数据业务系统。
一、Lambda架构
Lambda架构由Storm的作者Nathan Marz提出。 旨在设计出一个能满足实时大数据系统关键特性的架构,具有高容错、低延时和可扩展等特性。
Lambda架构整合离线计算和实时计算,融合不可变性(Immutability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,HBase等各类大数据组件。
1.1 Lambda架构理论点
Lambda架构对系统做了如下抽象:
Query = Function(All Data)
简言之:查询是应用于数据集的函数。 data是自变量,query是因变量。
Lambda有两个假设
不可变假设:Lambda架构要求data不可变,这个假设在大数据系统是普遍成立的:因为日志是不可变的,某个时刻某个用户的行为,一旦记录下来就不可变。
Monoid假设: 理想情况下满足Monoid 的function可以转换为:
query = function(all data/ 2) + function(all data/ 2)
Monoid的概念来源于范畴学(Category Theory),其一个重要特性是满足结合律。如整数的加法就满足Monoid特性:(a+b)+c=a+(b+c)
不满足Monoid特性的函数很多时候可以转化成多个满足Monoid特性的函数的运算。如多个数的平均值avg函数,多个平均值没法直接通过结合来得到最终的平均值,但是可以拆成分母除以分子,分母和分子都是整数的加法,从而满足Monoid特性。
1.2 Lambda架构
三层架构:批处理层、实时处理层、服务层,如图1所示:
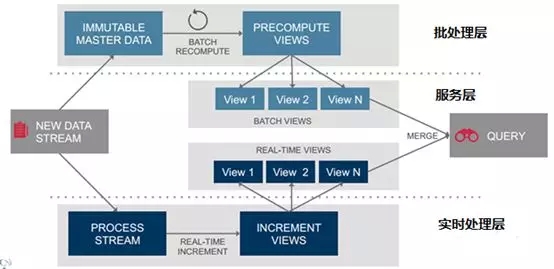
图1
批处理层:批量处理数据,生成离线结果
实时处理层:实时处理在线数据,生成增量结果
服务层:结合离线、在线计算结果,推送上层
1.3 Lambda架构优缺点
优点:
实时:低延迟处理数据
可重计算:由于数据不可变,重新计算一样可以得到正确的结果
容错:第二点带来的,程序bug、系统问题等,可以重新计算
复杂性分离、读写分离
缺点:
开发和运维的复杂性:Lambda需要将所有的算法实现两次,一次是为批处理系统,另一次是为实时系统,还要求查询得到的是两个系统结果的合并,可参考 http://www.infoq.com/cn/news/2014/09/lambda-architecture-questions
1.4 典型推荐架构
实时处理范式的需求
推荐系统的最终目的是提高转化率,手段是推送用户感兴趣的、需要的产品。为什么需要实时处理范式?
1号店会根据你实时浏览、加车、收藏、从购物车删除、下单等行为,计算相关产品的权重,把相应的产品立刻更新到猜你喜欢栏位。同样在亚马逊搜索浏览了《基督山伯爵》这本书,亚马逊首页很快增加一行新推荐:包含4个版本《基督山伯爵》
答案不言而喻:让推荐引擎更具时效性。如图2、图3所示:
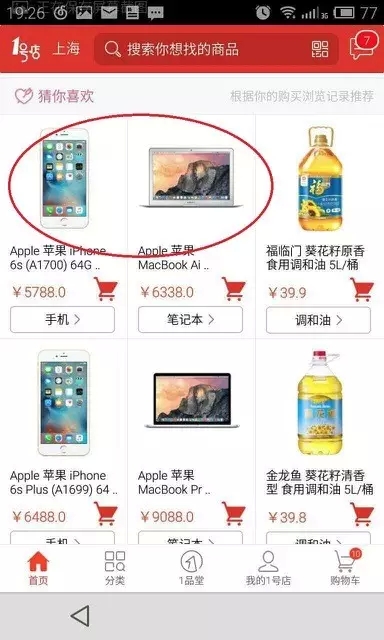
图2

图3
Netflix推荐架构
Netflix推荐架构如图4所示
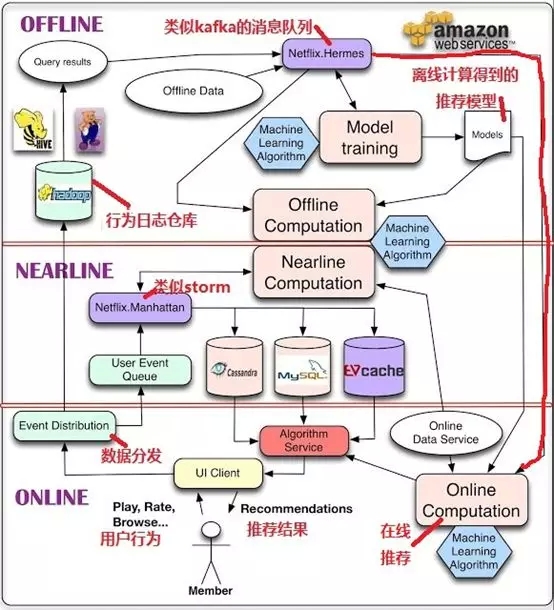
图4
批处理层:从Hive、pig数据仓库,离线计算推荐模型,生成离线推荐结果
实时处理层:从消息队列(Hermes、User Event Queue)实时拉取用户行为数据与事件,生成在线推荐结果
服务层:结合离线、在线推荐结果,为用户生成推荐列表
二、1号店推荐系统实践
2.1. 推荐引擎组件
目前共有6大推荐引擎:
用户意图:实时分析用户行为,存储短期内兴趣偏好
用户画像:用户兴趣偏好的长期积累(商品类目、品牌等),自然属性(年龄、性别),社会属性(居住地、公司)
千人千面:群体分析(某一大学、某一小区、公司、好友群)
情境推荐:根据季节、节日、天气等特定情境做推荐
反向推荐:根据商品购买周期等,方向生成推荐结果
主题推荐:分析用户与主题的匹配度(如:美食家、极客等),根据主题对用户进行推荐
产品架构如图5所示
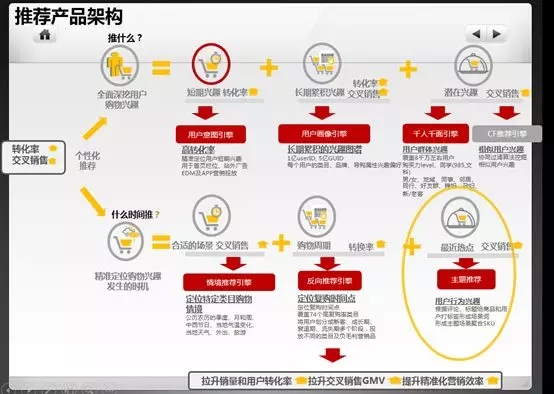
图5
今天主要讨论其中的主题推荐
2.2 主题推荐
首先主题推荐有三个步骤
建立关系(主题与商品,用户与商品,用户与主题)
选品,建立主题选品池
推荐,根据用户与主题的关系,从选品池为用户进行推荐 用公式表示就是:Topic_recommend = topic_recommend_function(offline data) 仅仅完成上面步骤,不需要“实时处理范式”就可以完成 后来主题推荐加入了“增量推荐”功能,通过用户的实时行为,对推荐结果进行调整
根据用户在线行为(浏览、购买、评论)等,调整离线推送的主题推荐结果 用公式表示就是Topic_recommend= mege ( topic_recommend_function1(offline data), topic_recommend_function2(online data) )
显然这演变成了一个Lambda架构,如图6所示
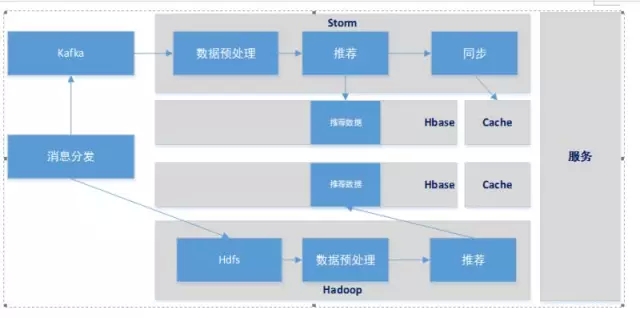
图6
2.3 主题推荐存储设计
存储最重要的就是 “主题推荐结果表”,需要满足如下特性
KV查询,根据用户id查询推荐结果;
保留一定时间内历史推荐数据。
根据上述两个特点,我们决定选用HBase。HBase的kv、多版本属性满足上述需求。有如下两个要点
读写分离
我们使用HBase主从方式,来读写分离,采用HBase主从的主要原因是
在CAP理论里面HBase牺牲的是可用性保证强一致性,flush、split、compaction都会影响可用性。检测region server挂断、恢复region都需要一定时间,这段时间内region数据不可用。
离线任务大量读写,对region server造成压力(gc、网络、flush、compaction),影响前端响应速度。
Cache
为了进一步提高响应速度,我们在服务层增加了一级缓存,采用1号店内部分布式缓存ycache(与memcache的封装)。
产品效果如图7所示
图7
2.4 HBase的维护
热点均衡:不要指望预split解决一切问题,热点的造成不可避免,尤其随着业务数据的增长,一些冷region该合并就合并。
做好为HBase修复bug的准备,尤其是升级新版本。
三、Lambda的未来
与其说Lambda的未来,不如说“实时处理范式”与“批处理范式”的未来。工程实践中Lambda之前提到的缺点有不少体会
逻辑一致性。许多公共数据分析逻辑需要实现两套,并且需要保证一致性。换个角度来看就是公共逻辑提取费力。
维护、调试两套平台
Jay Kreps认为Lambda架构是大数据方案中的临时解决方案,原因是目前工具不成熟。 他提供了一个替代架构,该架构基于他在Linkedin构建Kafka和Samza的经验,他还声称该架构在具有相同性能特性的同时还具有更好的开发和运维特性。
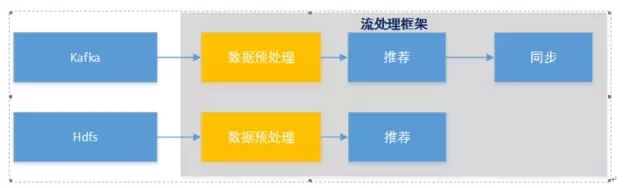
图8
让我想起了Spark streaming既可以做实时处理,又很自然做批量。让我想起了Storm的DRPC,就是为了做离线处理。有人说streaming本质是批量方式,实际上“实时”没有绝对界限,关键在于延迟。你认为10s,我也可以认为2s内才算实时。
对于Lambda架构问题,社区提出了Kappa架构,一套系统满足实时、批处理需求。 目前看来,是朝着 “实时”框架去主动包含“批量处理”的方向发展
四、个人的两点思考
两种不同的需求,一个框架搞定,是不是很熟悉?我们都想搞大而全,一劳永逸的事情,但许多往往被证明是错的。
MR是不是过时了?we need more,期待着数据与逻辑更便捷、更深入的交集。
五、Q&A
Q1:HBase你们遇到最诡异的是啥问题?
因为hdfs客户端没有设置读超时,导致HBase lock hang住,最后集群宕机。
Q2:玩推荐引擎首先想到的是mahout,王老师是否也有这方面的涉猎?
mahout、mlib 这些东西都是数据挖掘框架,主要看算法好坏,选谁区别不大。
Q3:日志量多大?Kafka集群配置怎样broker、replica等?碰到什么坑吗?
1天2T多数据,Kafka是整个公司公用。Kafka还是比较稳定,我们这边几乎没遇到问题,Storm问题出了不少。Kafka集群replica有些是2、有些3,broker是10。遇到大量数据的时候Kafka每隔一阵可能出现CLOSE_WAIT的问题
Q4:千人千面引擎最后体现的效果是什么?用在什么地方?
千人千面效果,针对小区用户转化率提升100%
Q5:请问下推荐排序时使用了什么算法,以及大概多少人负责算法模块?
在app首页正在尝试逻辑回归和learn to rank,7~8人做算法
Q6:1号店对新登陆用户做什么推荐处理? 主题推荐人工介入量有多大?1号店对其推荐算法出过转化率外,从算法角度会关心哪些指标?
新用户冷启动,采用两个策略
数据平滑
热销优质商品补充
推荐最重要的是看排序效果,主要是推荐位置的转换率。
Q7:Storm都遇到哪些填好久都填不完的坑可以分享下么?
Storm在高tps时候容易消息堆积。之前读Kafka,拉的模式。实时推荐需要实时的反应用户的行为,用户明明下单了还在推荐。后来读取订单的行为用了自主研发的jumper,推的方式解决了快速得到订单行为,其他行为用Kafka。
资源分配、隔离不合理。其他任务出现内存泄露等问题会影响其他任务task。
Q8:HBase热点问题怎么解决的呢?是分析key的分布,然后写脚本split么?
基本思路一样,写工具检测。重点在request量,不在key的分布。
Q9:批处理层向服务层推送离线计算结果的周期是怎样的?会因数据量大而对线上的HBase造成冲击吗?
目前是一天一次,冲击不大。 1、错峰; 2、bulkload;3、读写分离。

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号