原文地址:http://chuansong.me/n/355827651252
泰康在线微信公众号系泰康在线财产保险股份有限公司旗下平台,希望可以通过持续不断的创新,提升客户对于保险的认知及体验,通过对大数据技术的应用,精准的为客户设计产品以及提供服务。泰康在线微信公众号,现有1000多万粉丝。在日常的运营中,借助于红包奖励、卡券分享、消息通知、微信分享等手段,通过好的内容,好的活动、好的产品以及相应的精准营销来增强用户的粘性和活跃度。
在日常运营中,公众号会通过给用户下发营销或者科普类的消息来通知客户。 根据经验,微信消息下发后10分钟后流量会逐步上升,30分钟左右到达峰值,1个小时后会显著下降。在这个时间段内,系统的压力会很大。
在系统设计和改进中,系统的很多场景使用异步进行实现,一方面能缩短主流程的时间处理,另一方面能够通过异步队列进行一定程度的削峰。今天重点介绍单个JVM内的异步优化实践,不涉及分布式时的异步优化实践。在异步执行时,可以调用远程的服务集群来实现一定的任务分解。
部署示意图
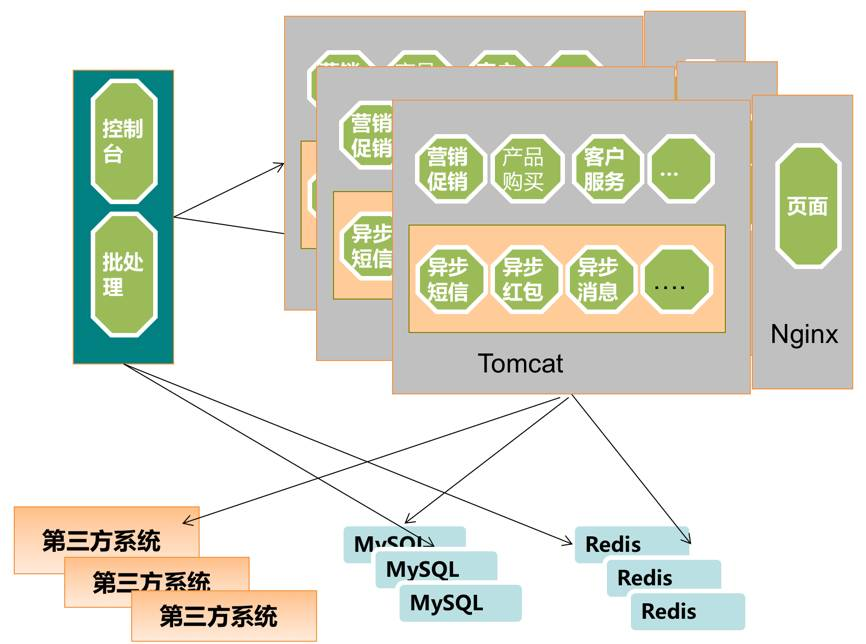
整个系统都部署在公有云上,虚拟机上有部署1个Nginx,4个Tomcat,Nginx使用随机的方式负载均衡到Tomcat上面。虚机之间通过LB将客户请求转发到Nginx上面负载均衡,Nginx再将请求分配到tomcat应用服务器上。
由多台应用服务器,对外服务提供Rest服务,在每个Tomcat内部使用异步队列。同时由一台控制服务器,进行异步任务的补偿任务和管理功能。Tomcat和Redis使用多级缓存来降低对Redis的压力,并减少依赖。
为什么要在虚机上部署Nginx将请求转发到Tomcat,而不是由LB直接转发到Tomcat。这是因为LB能够支持的IP个数是有限的。
典型的用户场景
在公众号的运营过程中,典型的事件包括:
-
发送短信验证码
-
购买成功或者抽奖成功短信通知
-
卡券或优惠券发放
-
发放微信红包
-
微信消息通知
-
订单流程处理
-
定时批处理(比如数据同步)
-
工作流性质的异步任务(未完成异步任务补偿)
面详细说明不同场景能够异步的原因:
-
不同场景(用户注册,用户购买产品等)下的短信验证码发送,可以使用异步方式发送: 一方面是因为客户这个时效性要求没有那样高,另一方面在特定时间范围内用户没有收到验证码,用户可以点击再次发送验证码。
-
购买成功或者抽奖成功后短信或者邮件通知,可以通过异步的方式进行。 因为涉及用户的利益,要谨慎对待。一方面一定要把数据先存到数据库或者日志里面(注意信息安全^-^,别存敏感明文信息或者加密存储),然后再放入到异步队列中执行。
另一个方面,要考虑到应用服务意外停止时,没有发送成功数据的补偿机制。 这种情况不常见,并且为了减少耦合和当前异步程序的复杂度。我们使用单独的服务上部署异步任务补偿程序,来扫描未完成的任务,并且进行重放(一定要注意严谨性)。
-
优惠券和卡券的发放,跟购买成功或抽奖成功的方式类似。\u000b可以在当前活动高峰后延时发放,并且使用异步的方式进行。
-
微信红包,因为需要跟微信进行交互,并且微信会通知客户红包的情况,可以使用异步的方式进行。 当涉及资金或者礼品时,一定要谨慎对待设计,并且需要有方便进行异步任务停止和启动的功能。
-
微信消息通知,因为跟微信进行交互,成功后微信进行通知,可以使用异步。 这个跟短信验证码类似。
-
订单流程处理,可以使用异步,因为涉及到后续步骤可以使用简单工作流来完成。有几个开源的框架可以参考。
-
数据同步或者异步任务补偿,因为是延时处理,可以使用异步进行处理。在使用时,可以配合定时任务,比如cron4j来周期性的进行补偿。适合后面总-分-总的任务处理模式。
针对这些“无处不在的异步”,后面详细分析其内在模型。
无处不在的异步
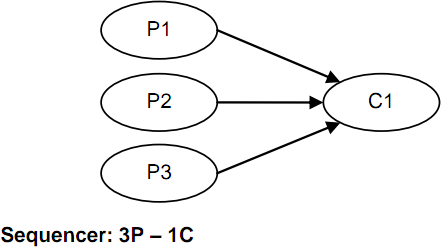
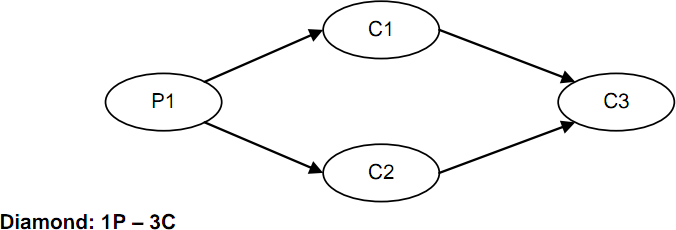
下图包含了4种典型的异步队列模型(图片来源于网络):
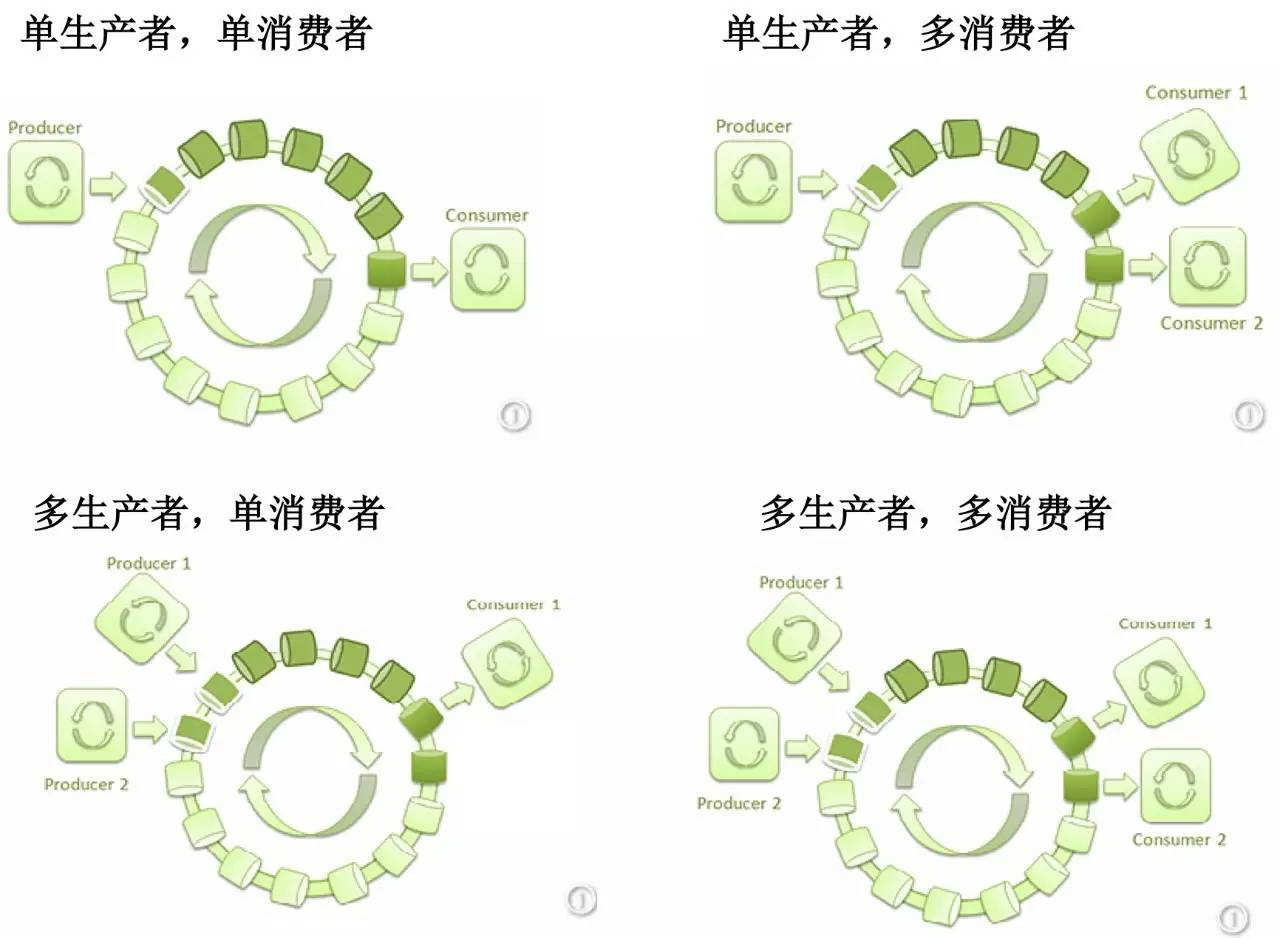
一个生产者生产数据,一个消费者消费数据,一般用在后台处理的业务逻辑中。
-
一个生产者生产数据,多个消费者消费数据(这里面有两种情况:同一个消息,可以被多个消费者分别消费。或者多个消费者组成一个组,一个消费者消费一个数据)。
-
多个生产者生产数据,单个消费者消费数据,可以用在限流或者排队等候单一资源处理的场景中。
-
多个生产者分别生产数据,多个消费者消费数据(这里面有两种情况:同一个消息,可以被多个消费者分别消费。或者多个消费者组成一个组,一个消费者消费一个数据)。

总分总任务模型:特别适第一个线程取出一批数据放到队列中(比如select);由多个线程分别执行业务逻辑;执行后的结果由一个线程来执行(比如update操作,这样能够防止数据库锁)
这是从技术上分析的几种常见模型,在实践中涉及怎样选择框架。
-
使用堵塞队列的线程池
-
使用固定步长或固定时间的队列
-
使用Disruptor
-
使用MQ或Kafka
使用线程池实现异步 (支持多生产者,多消费者)
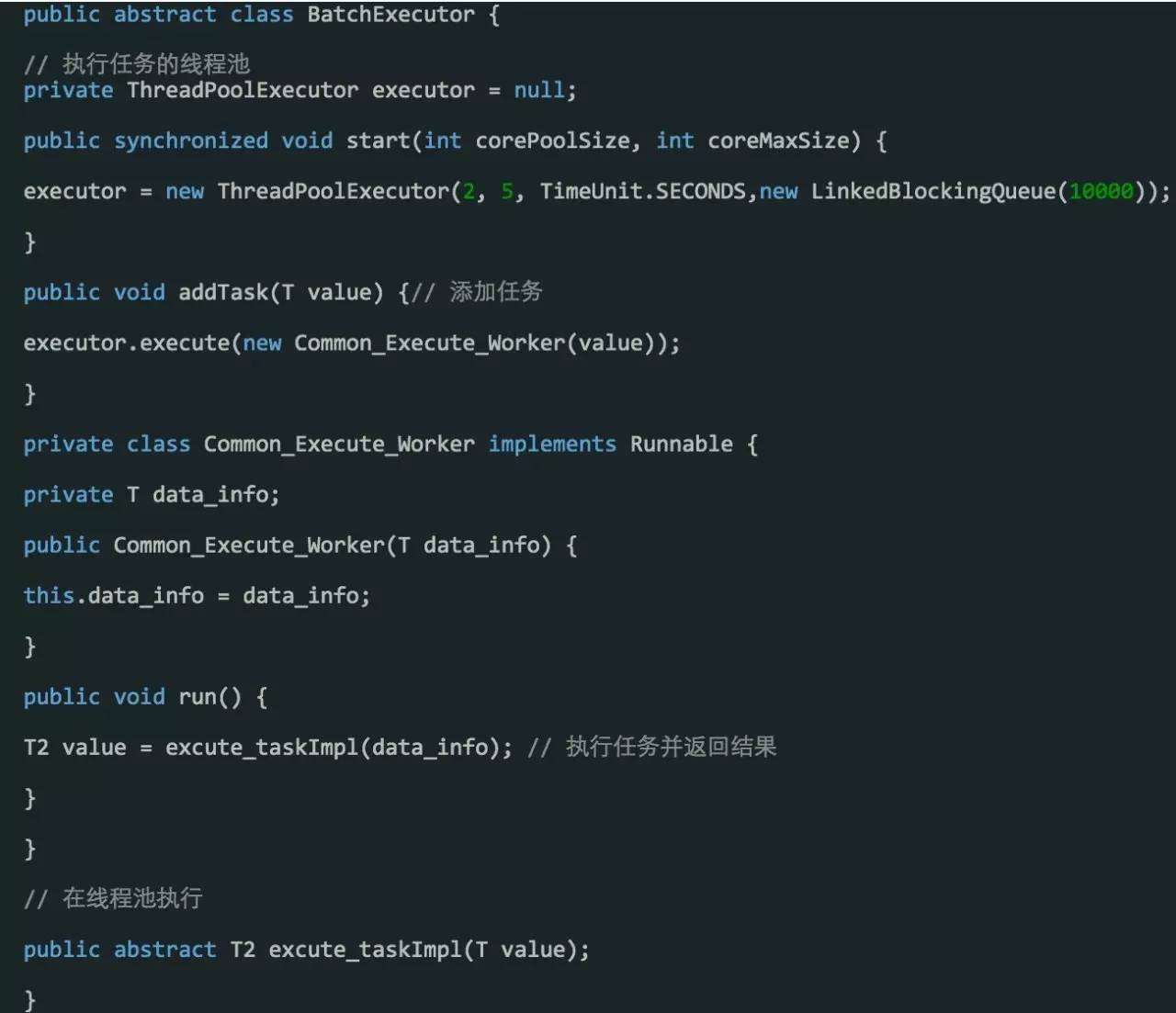
特点:可以使用JDK自带的线程池实现异步,编程简单,资料多。建议在并发量小的场景下优先选择。
使用Guava Queues (支持多生产者单消费者)

特点:异步批量队列,在队列到达指定长度,或者到达指定时间后,批量进行数据处理。适合于对响应时间要求低,能够容忍一定的数据丢失的场景。比如短小文本数据的批量保存。
在经过一段时间调研后,我们发现Disruptor更能满足我们需要。
首先介绍一下Disruptor的强悍的性能。

这张图包含我列举的上述的异步队列模型景,因此很有代表意义。Disruptor因为使用无锁的队列方式,具有很高的性能。具体的原理不详述,大家可以搜索看到。Disruptor支持上面典型场景,并且灵活使用Disruptor的工作流机制,能简化编程。
英文文章入门:https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started
中文的demo链接:http://my.oschina.net/u/2273085/blog/507735?p=1
并发框架Disruptor相关译文:http://ifeve.com/disruptor/
再贴一下官方的测试结果。

下面从代码层面说明disruptor的几种用法。
使用Disruptor(单生产者多消费者)

Disruptor 提供了多个 WaitStrategy的实现,每种策略都具有不同性能和优缺点,根据实际运行环境的 CPU 的硬件特点选择恰当的策略,并配合特定的 JVM的配置参数,能够实现不同的性能提升。 例如,BlockingWaitStrategy、SleepingWaitStrategy、YieldingWaitStrategy 等,其中:
-
BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现;
-
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
-
YieldingWaitStrategy的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于 CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
我们现在使用BlockingWaitStrategy这种模式。
使用Disruptor(多生产者多消费者)
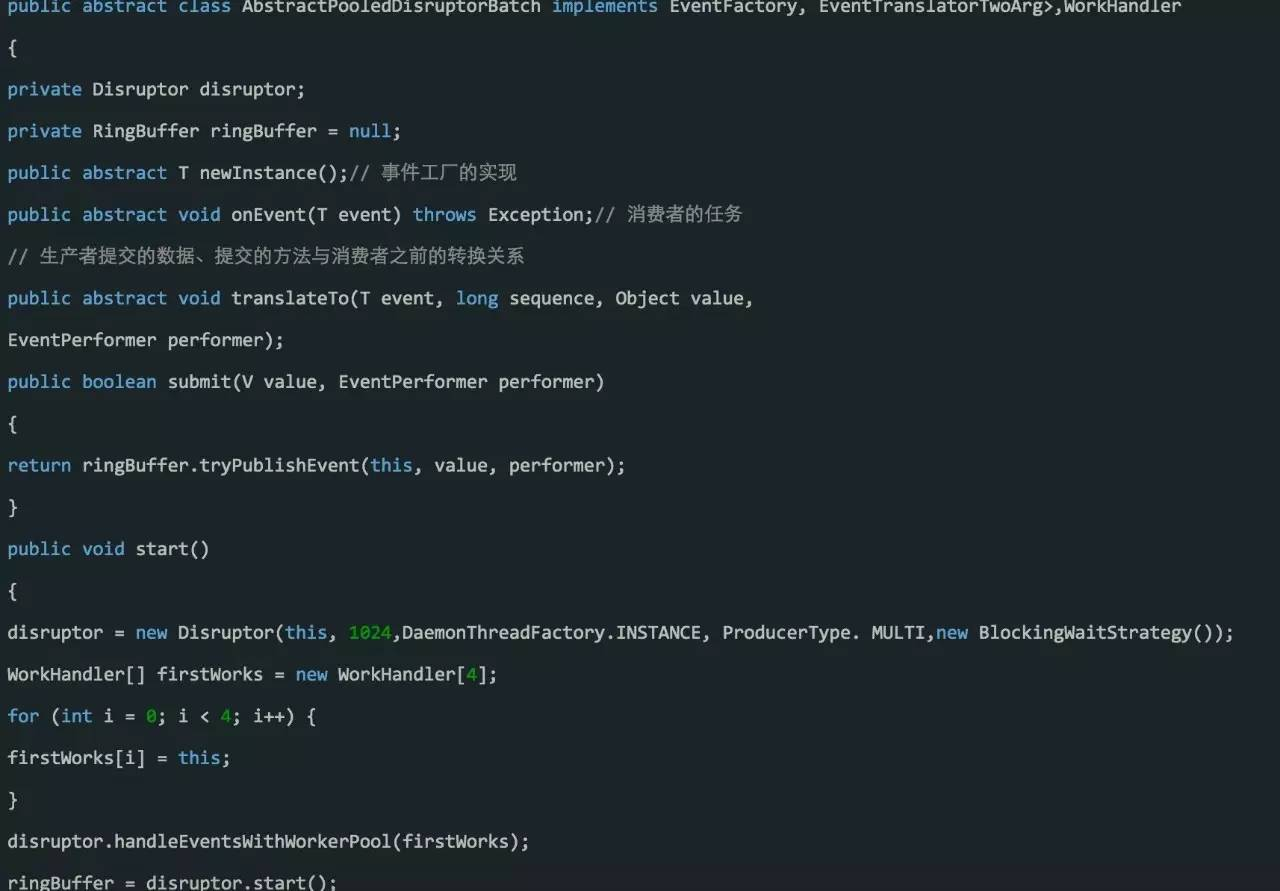
使用Disruptor(多生产者多消费者)
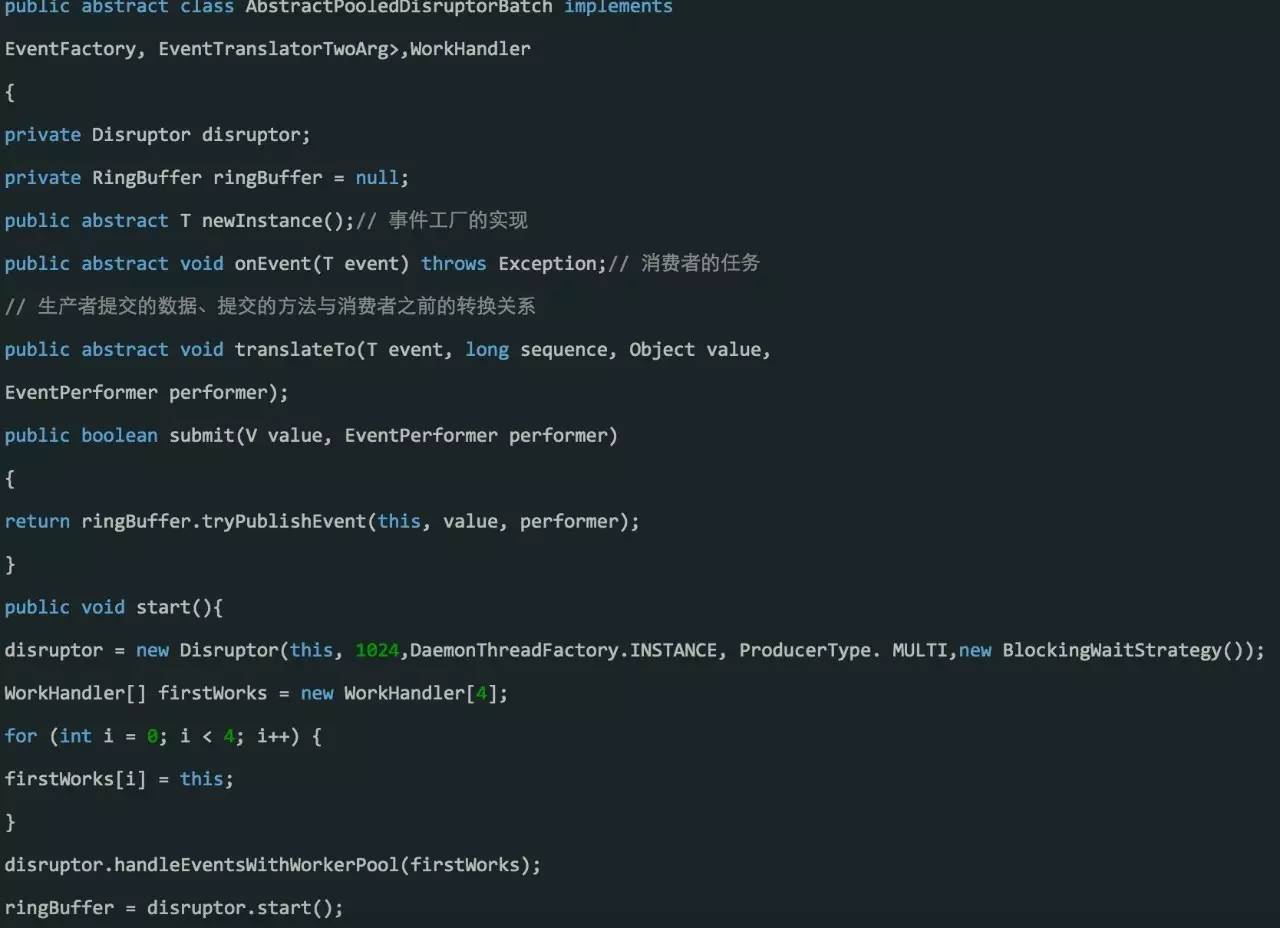
这个例子中,使用类似线程池的消费组处理数据。
多步模式工作流:Disruptor
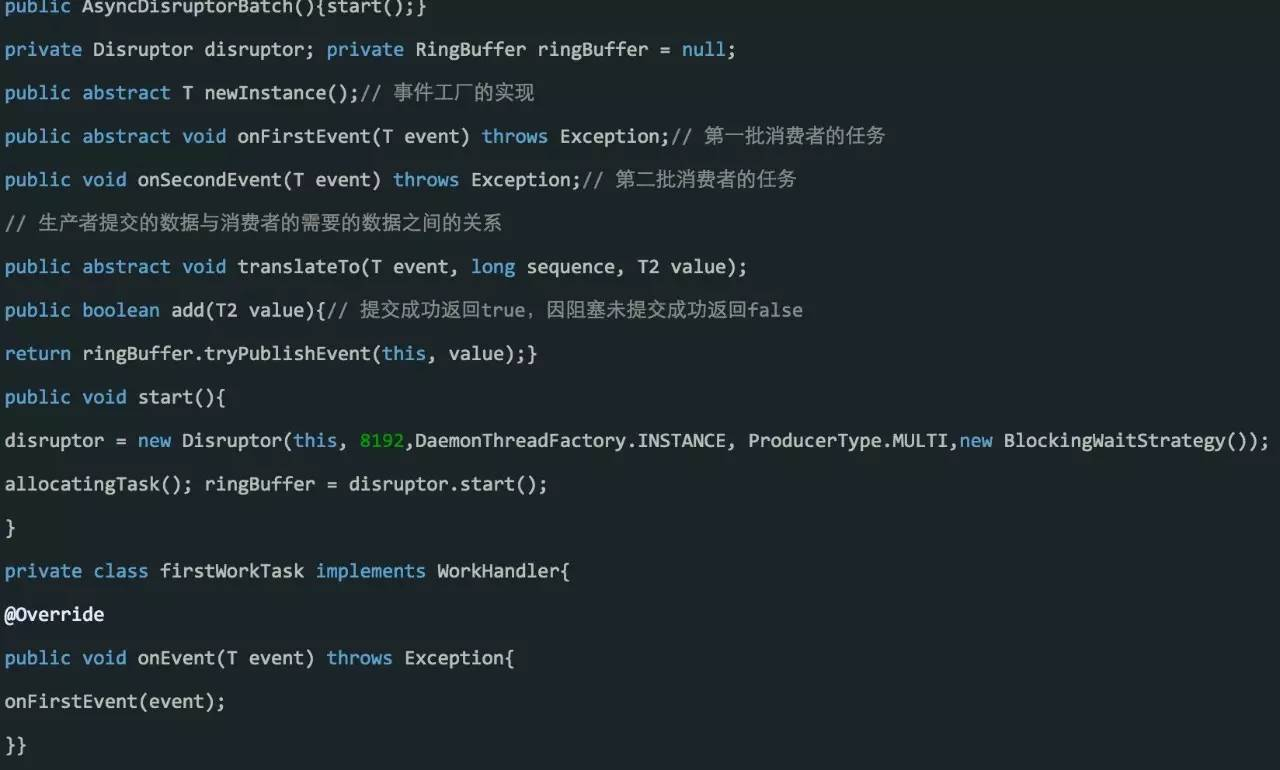

使用异步后的烦恼
烦恼一: 数据丢失的风险
解决方式:先写日志或数据库,后放入异步队列.
烦恼二:对其他系统的压力变大
解决方式:使用一定的限流和熔断,对其他系统进行保护。
烦恼三:数据保存后异步任务未执行
解决方式:使用异步任务补偿的方式,定期从数据库中获取数据,放到队列中进行执行,执行后更新数据状态位。
烦恼四:怎样队列长设置和消费者数量
解决方式:使用实际的压力测试来获得队列长度。或者使用排队论的数学公式得到初步的值,然后进行实际压测。
最后介绍一下项目中的经验:
-
量力而行:根据业务特点进行技术选型,业务量小尽量避免使用异步。有所为,有所不为
-
数据说话:异步时一定要进行必要的压力测试
-
先找出系统的关键点:优化单体系统内的性能,再通过整体系统分解来全局优化
-
根据团队和项目的特点选择框架。

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号