
haddop从单机改为集群
Host配置
vim /etc/hosts
如果没有足够的权限,可以切换用户为root。 三台机器的内容统一增加以下host配置: 可以通过hostname来修改服务器名称为master、slave1、slave2
192.168.71.242 master
192.168.71.212 slave1
192.168.71.213 slave2配置SSH无密码登录
设置ssh免密码登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/
authorized_keys修改vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改/hadoop-2.8.2/etc/hadoop/slaves
将原来的localhost删除,改成如下内容
vim /hadoop-2.8.2/etc/hadoop/slaves
slave1
slave2最后,将整个hadoop-2.8.2文件夹及其子文件夹使用scp复制到slave1和slave2的相同目录中:
scp -r /usr/local/hadoop-2.8.2 root@slave1:/usr/local
scp -r /usr/local/hadoop-2.8.2 root@slave2:/usr/local
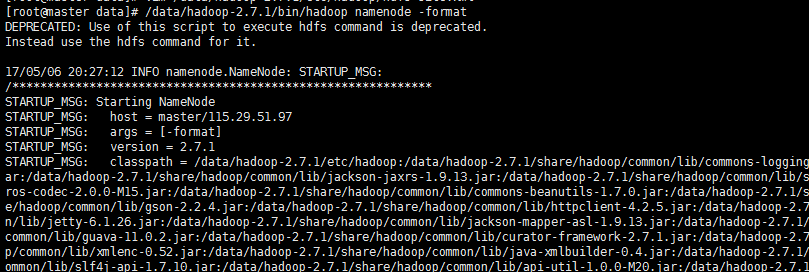


在Master上执行jps命令,得到如下结果:


master

slave1

slave2

说明ResourceManager运行正常。

jps
Master显示:
SecondaryNameNode
ResourceManager
NameNode
Slave显示:
NodeManager
DataNode
五、测试hadoop
5.1 测试HDFS
最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:

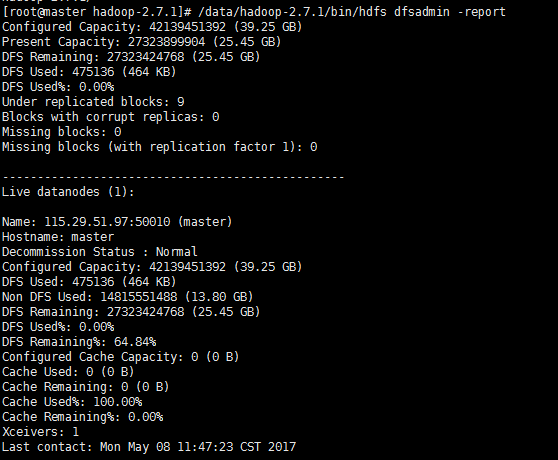
5.2 查看集群状态
/data/hadoop-2.7.1/bin/hdfs dfsadmin -report
5.3 测试YARN
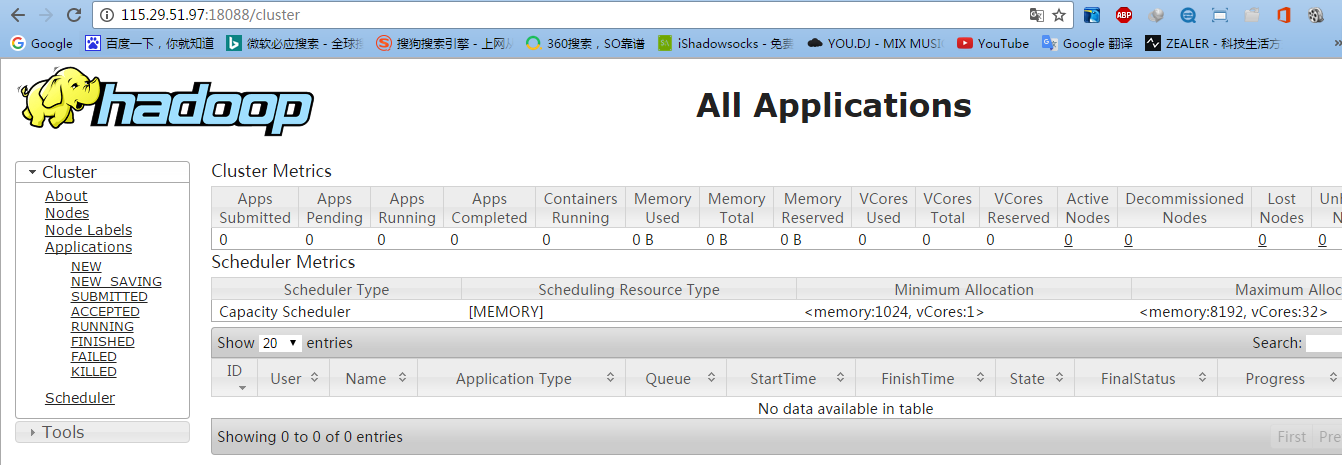
5.4 测试mapreduce
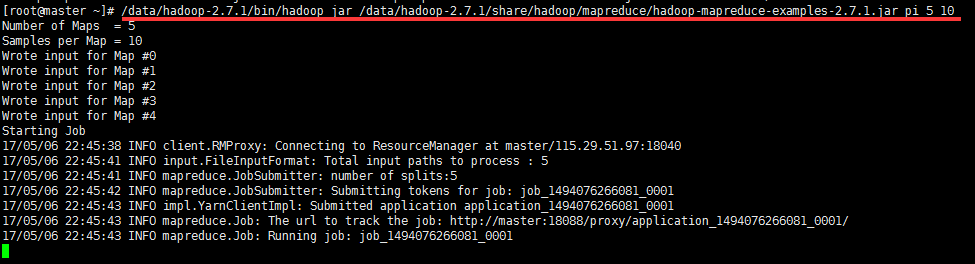
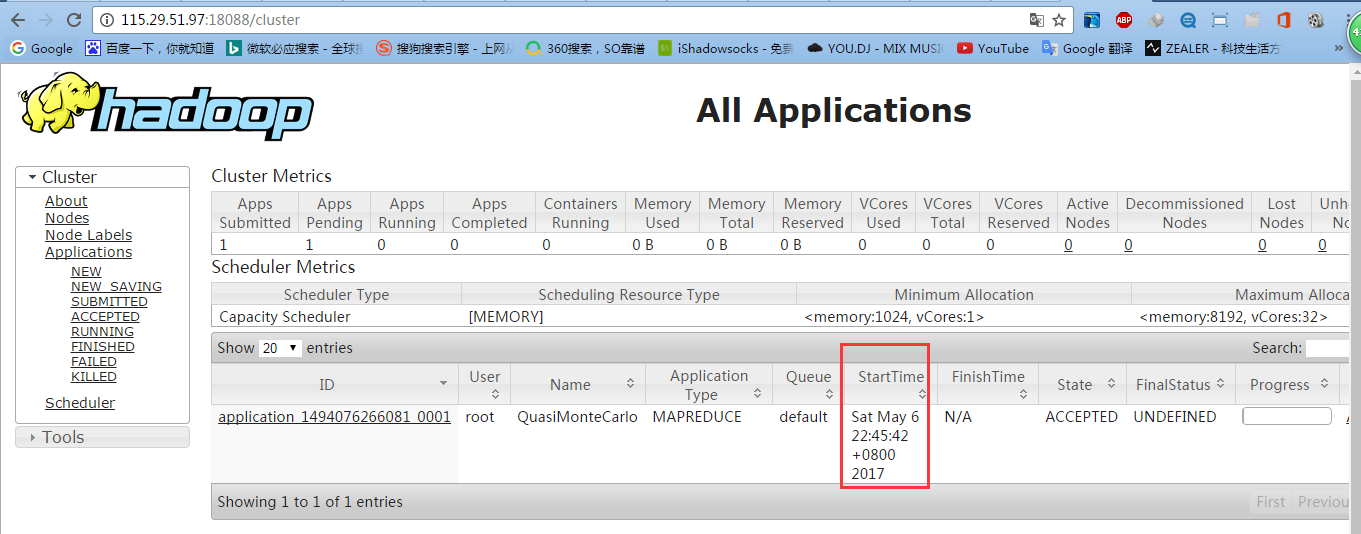
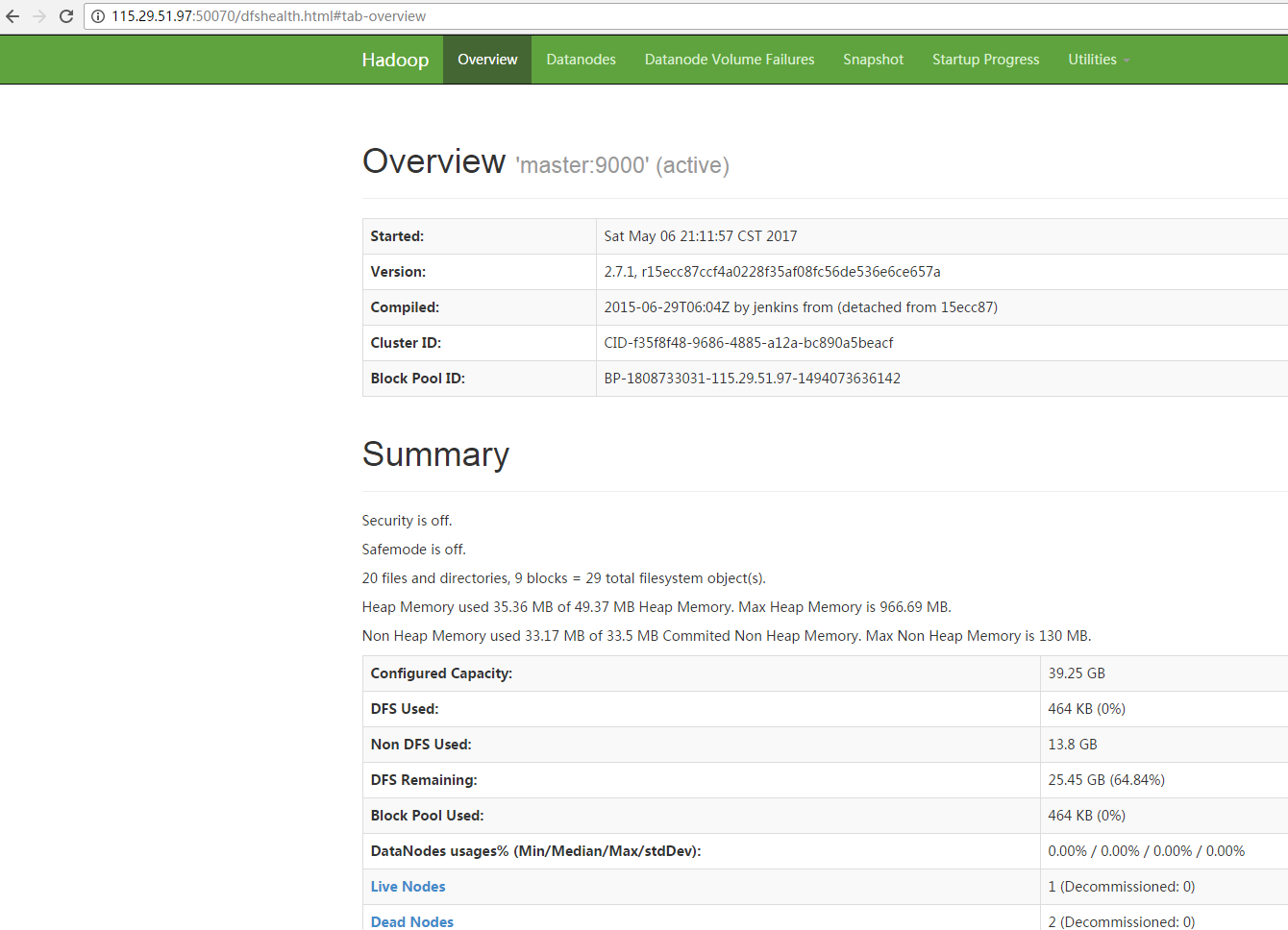
5.5 测试查看HDFS:
http://115.29.51.97:50070/dfshealth.html#tab-overview
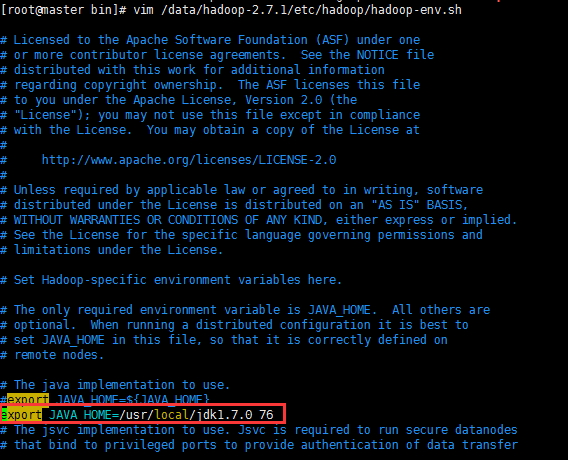
六、配置运行Hadoop中遇见的问题

则需要/data/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路径
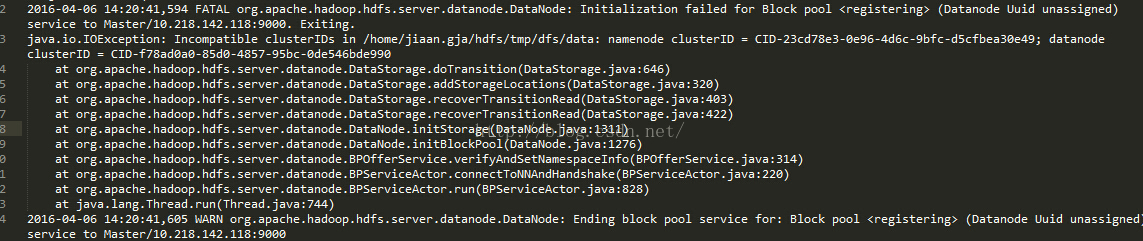
6.2 ncompatible clusterIDs
由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题:
6.3 NativeCodeLoader的警告
在测试Hadoop时,细心的人可能看到截图中的警告信息:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号