requests 库和beautifulsoup库
python 爬虫和解析
库的安装:pip install requests; pip install beautifulsoup4
requests 的几个常用方法:
requests.request() #以下各方法的基础
requests.get(url,params=None,**kwargs) #获取html内容
requests.head() #获取网页头部内容
requests.post()
requests.put()
requests.patch()
requests.delete()
重点为:get()其有12个控制关键字参数 返回为response对象
r.status_code #200为正常
r.text #html内容
r.encoding 编码
r.apparent_encoding 备选编码
r.content 二进制形式返回,爬取 图片,视频,音频等的关键
常使用try,except框架
import requests import os url = 'http://image.ngchina.com.cn/2018/1010/20181010031434134.jpg' root = 'd://pics//' path = root + url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r=requests.get(url) with open(path,'wb') as f: f.write(r.content) f.close() print('文件保存成功') else: print('文件已存在') except: print('失败')
import requests import os url = 'http://mov.bn.netease.com/open-movie/nos/mp4/2016/05/16/SBM8NN8G6_shd.mp4' root = 'd://vidio//' path = root + url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r=requests.get(url) with open(path,'wb') as f: f.write(r.content) f.close() print('文件保存成功') else: print('文件已存在') except: print('失败')
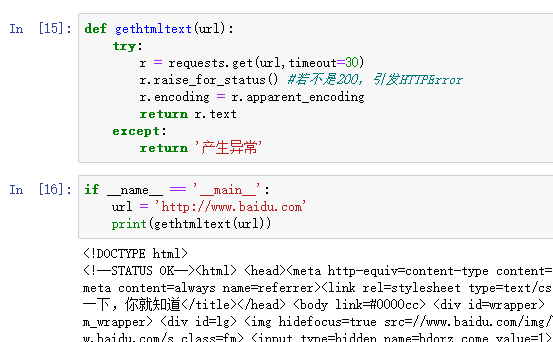
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 def gethtmltext(url): 5 try: 6 r = requests.get(url,timeout=30) 7 r.raise_for_status() 8 r.encoding=r.apparent_encoding 9 return r.text 10 except: 11 return '' 12 13 14 def fillunivlist(ulist,html): 15 soup = BeautifulSoup(html,'html.parser') 16 for tr in soup.find('tbody').children: 17 if isinstance(tr,bs4.element.Tag): 18 tds = tr('td') 19 ulist.append([tds[0].string,tds[1].string,tds[2].string]) 20 21 def printunivlist(ulist,num): 22 print('{:^10}\t{:^6}\t{:^10}'.format('排名','学校名称','总分')) 23 for i in range(num): 24 u=ulist[i] 25 print('{:^10}\t{:^6}\t{:^10}'.format(u[0],u[1],u[2])) 26 27 28 def main(): 29 uinfo = [] 30 url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' 31 html = gethtmltext(url) 32 fillunivlist(uinfo,html) 33 printunivlist(uinfo,20) 34 35 main()
查看爬虫协议在最后加上robots.txt 如:www.jd.com/robots.txt
Beautiful Soup库 #解析网页用
BeautifulSoup(text,'html.parser')
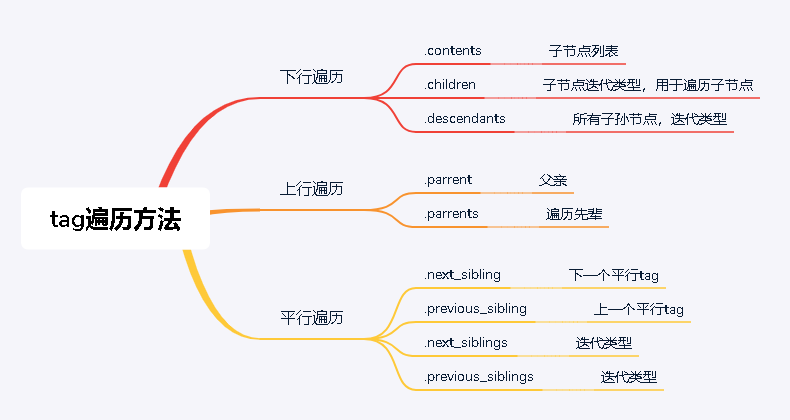
SOUP库的基本元素:
Tag 标签,最基本的信息单元,对应<>....</>
Name 标签名
attributes 标签属性:Tag.attrs
Navigablestring 标签内非属性字符串<>....</>中的字符串 格式:Tag.string
Comment 标签的注释部分
如:<p class='title'>.....</p> p标签
p.name p.attrs p.string

 浙公网安备 33010602011771号
浙公网安备 33010602011771号