Cassandra存储附带索引(SAI)全新上线
新一代Apache Cassandra索引现已在Astra和DataStax Enterprise 6.8.3中正式开放使用 (general availability or GA),很快您也将在开源版的Apache Cassandra中看到这项全新功能。
01 SAI简介
DataStax非常高兴地宣布——具有高伸缩性且可以全局分布的存储附带索引(Storage-Attached Indexing or SAI),现已在Astra和DataStax Enterprise(DSE)中正式面世。
开发者可以在Apache Cassandra中使用关系型WHERE的模式,从而充分利用用户期望的数据库索引功能。相比Cassandra现行的索引或外部扩展的搜索方案,SAI赋予架构师高效且更简单的过滤筛选能力。另外,SAI解决了Cassandra用户面临的数据建模、查询灵活性以及运维方面的挑战。
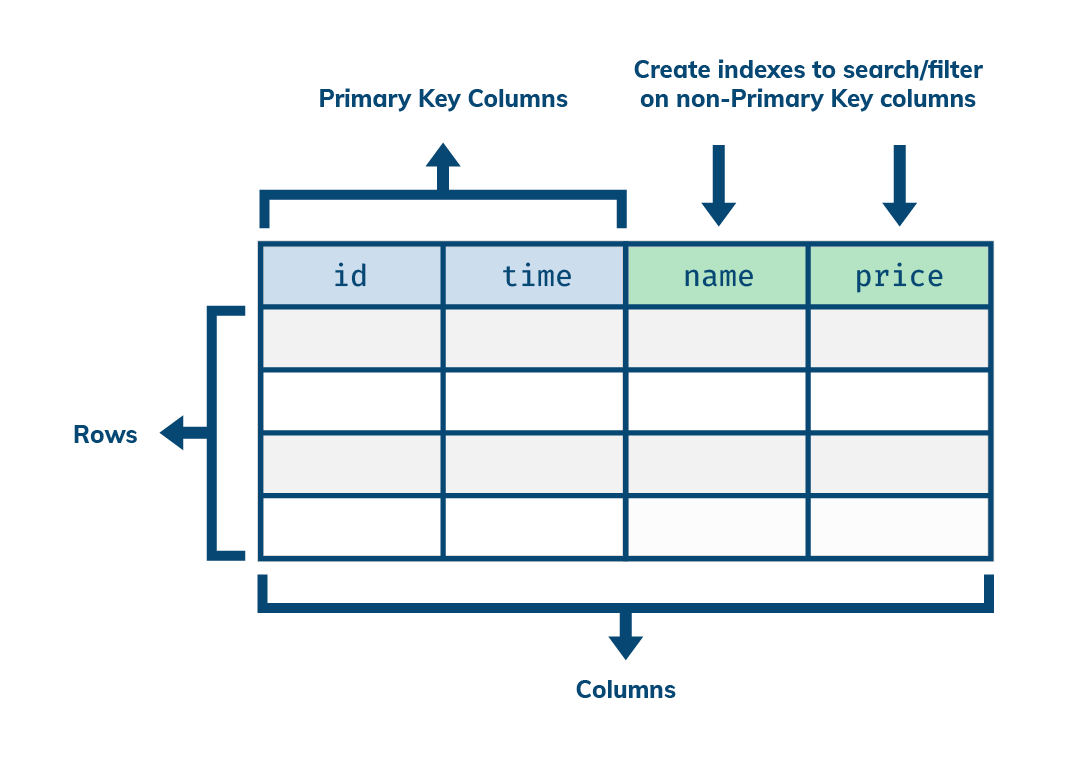
为了更好地解释这些,我们借助一个例子来进一步说明。假设有一个简单的表,它的结构如下。
CREATE TABLE products ( id int, time date, name text, price int, PRIMARY KEY (id), time );
下面这个SELECT示例查询语句在SAI问世之前是不可用的,因为其中没有引用任何主键。
SELECT name, price FROM products WHERE price < 30
现在有了SAI,上面的查询语句不仅可以使用,而且在数据规模很大时依然高速。
关键且现代的应用程序具有突破性的置信度、伸缩性、可用性以及性能。正在构建这些应用程序的开发者和架构师们选择使用Cassandra,因为其伸缩能力在任何负载下都能横跨裸机、多云、混合环境以及其它任何介于这三者之间的环境。只用写一次代码就可以大规模部署并实现自动化运维,这种灵活性改变了代码驱动的伸缩性的相关成本。
即使Cassandra很擅长注入数据,它严格的查询模式对习惯于关系型数据库的开发者来说仍有限制,这导致了开发周期的延长和市场交付时间的延迟。但这种情况不再会出现,因为SAI使Apache Cassandra具有了全局索引的能力。
操作员和数据库管理员对于支持在Cassandra上运行的至关重要的应用程序很有信心,因为Cassandra不仅没有宕机时间,而且用来维护正常运行以及性能服务级别协议(SLAs)的时间也更少。有了SAI,操作员无需过多担忧与伸缩、备份和修复相关的运维。因为相比之前的补充索引,SAI这种解决方案使这些运维过程更合理化也更简单。
02 SAI使用说明
DataStax不仅已经在Astra和DSE 6.8.3中开放使用SAI,同时还提交了Apache CEP(Cassandra Enhancement Proposals,即Cassandra改进提案)以便用户可以在开源的Apache Cassandra版本中用到此项功能。
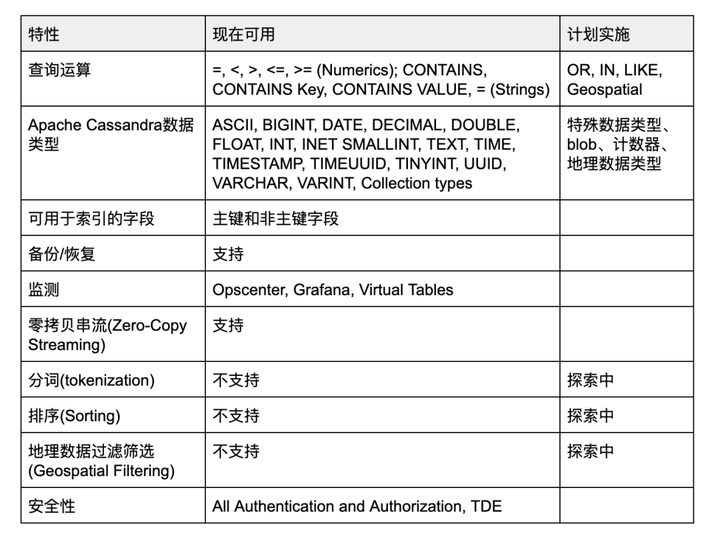
下面是已经开放使用的SAI版本所支持的功能。
03 现在开始体验吧
存储附带索引非常容易上手。
假设有一个这样的表——
CREATE TABLE products ( id int, time date, name text, price int, PRIMARY KEY (id), time );
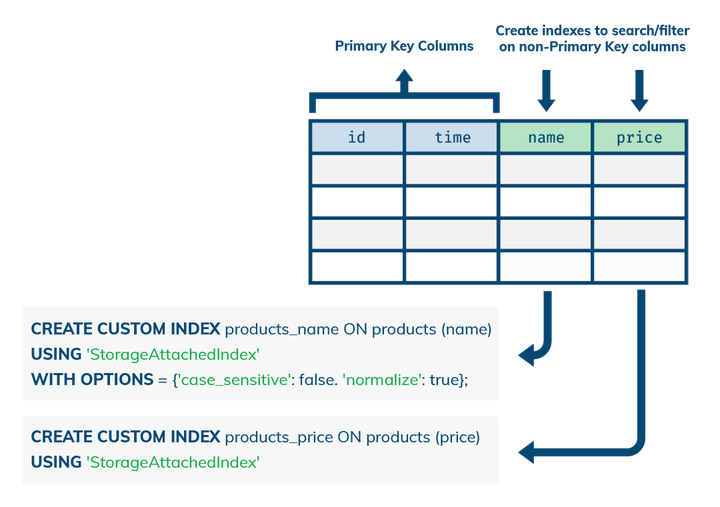
如何定义SAI索引?在创建完数据库、键空间(keyspace)以及一个或多个表后,使用下面的DDL(Data Definition Language,即数据定义语言)命令语句在你希望索引的表格上定义一个或多个SAI索引。
CREATE CUSTOM INDEX ... USING 'StorageAttachedIndex'
一旦索引创建完成,接下来就只剩书写查询语句和指定索引字段的步骤了。就是这么简单!
下图中可以看到具体的查询示例代码。
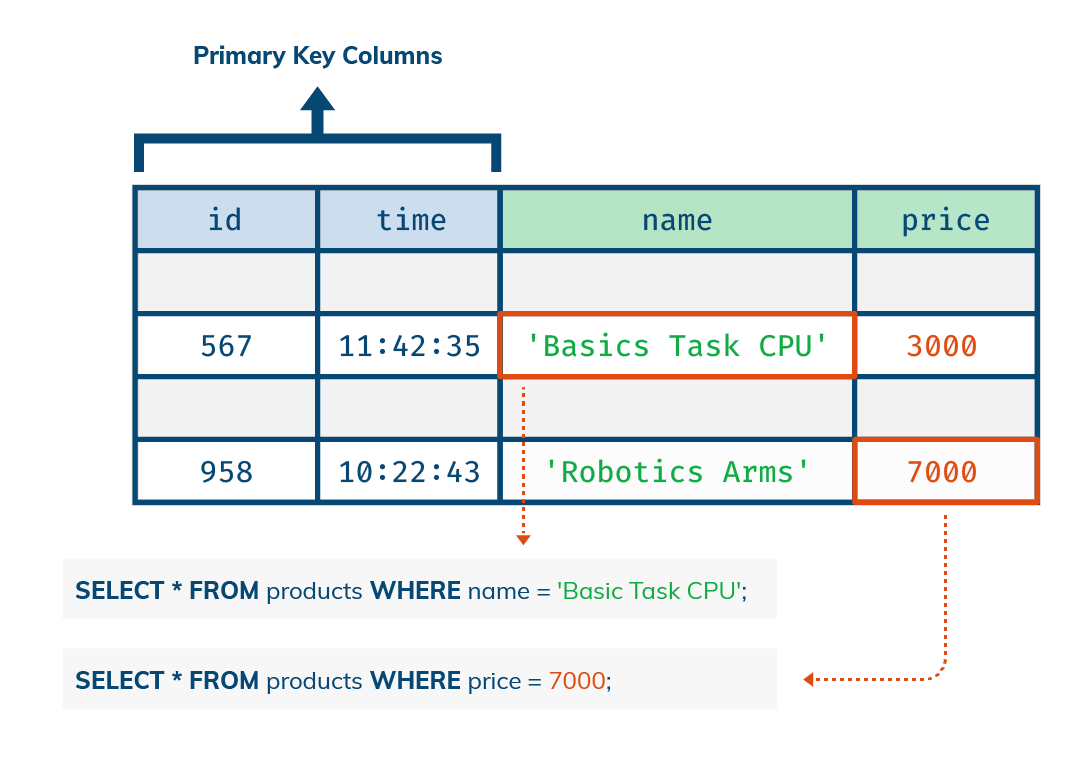
在系统内部,这个索引已经根据所选列的数据类型进行了优化。比如,数字类型的字段为区间查询做了优化。系统会选择正确的索引执行方式,所以你无需考虑这些。
想要了解更多?点击下面的链接,跟随SAI文档中的初学教程来学习使用这个超棒的新索引。快速上手SAI
04 SAI的设计
存储附带索引的构建基于两部分:一是现行的Cassandra索引的最佳实践;二是常见的扩展分布式索引及搜索解决方案中最佳的分布式索引算法。
SAI与Apache Cassandra的存储引擎深度集成,这也正是为什么我们称之为“存储附带索引”。
SAI并不是抽象的索引表,随着数据的写入,它将Cassandra内存中的Memtable和磁盘上的SSTable这两个数据结构都编入索引。在读取时,SAI可以过滤筛选内存中和磁盘上的多种数据结构,智能地返回结果。
SAI几乎没有增加核心数据库运维的复杂性。从快照创建到模式(schema)管理再到数据过期,SAI与核心数据库的性能和机制紧密集成。
存储附带索引还与零拷贝串流完全兼容。这意味着当你增加或删除节点时,存储附带索引会与SStables完整同步。这样你就无需将这些索引序列化,也无需在接收节点的一端重建索引。
SAI并不需要引入任何特别的配置或“神奇的”设置来实现高性能,标准的Cassandra调校技巧依然适用。
比如,如果你有严格的读取延迟要求,调整压实操作(compaction)参数就很重要——因为你会想要确保Cassandra持续进行压实,从而让SSTable的数量保持在低点。这些用于调整无索引表的压实过程的方法,同样适用于那些使用了SAI的表。
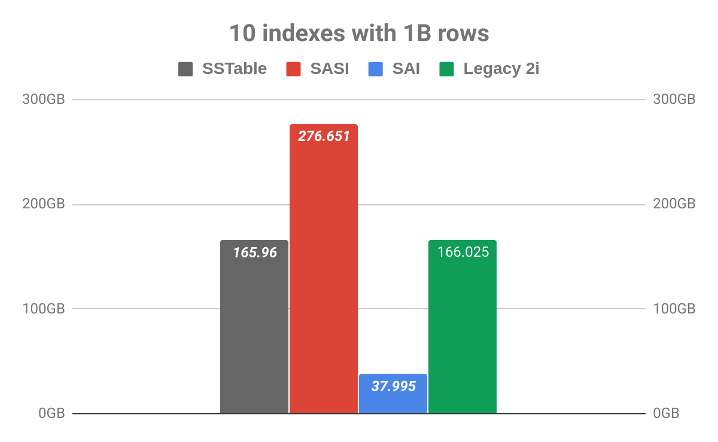
05 总体拥有成本(TCO)
SAI所需的磁盘使用量远远低于其它Cassandra原生或扩展的索引解决方案。下图分别展示了SAI、Cassandra SASI和二级索引的磁盘占用空间。
与SASI不同,SAI不会为每个索引词(term)都创建ngram,所以能节省大量的磁盘空间。与二级索引相比,SAI无需复制整张表来添加新的分区键。
06 SAI的性能
在初步测试中,我们已经看到SAI相较于其他Cassandra原生索引方案,在数据的更新(增、改、删)方面有着极大的性能提升。大致来说,使用者可以期待SAI比二级索引多出大约40%的吞吐量并减少230%的延迟时间。在读操作方面,SAI比二级索引略快一些。
相比Cassandra其它的索引方案,使用SAI将会为你带来更多的功能和更高的性能。
07 我们的下一步计划
我们非常努力地奠定了SAI的基础,现在我们将集中开发新功能。在接下来的几个月里,我们将优先做以下两件事:
- 通过CEP(Cassandra改进提案)流程,使SAI加入到开源的Apache Cassandra版本中
- 研发全局排序、分词、地理数据支持等功能,继续拓宽Cassandra索引的边界
08 我们一直在这里
存储附带索引是DataStax工程团队酷爱的项目,我们以解决Cassandra用户在数据建模、运维和查询灵活性方面遇到的挑战为使命。
根据查询语句来设计表的结构是一项Cassandra通用的最佳实践,但是它带了来许多数据的冗余和开发者的疑惑。而SAI可以让用户根据表中的任意字段筛选数据,这意味着用户不再需要迎合查询语句来建构表——你只需简单地以最自然的方式创建表,并使用SAI索引字段灵活地查询数据且不受主键的任何限制。
针对多种分布式索引引擎的经年累月的研发,加上数年来通过解决最复杂的分布式数据的问题所积累的知识,DataStax已经通过SAI这个新的分布式索引解决了从Cassandra中灵活读取数据的挑战。
我们希望您同我们一样喜欢SAI。如果您有任何问题或反馈,请通过下方邮件直接与我们联系:
product.feedback@datastax.com
我们的工程团队随时准备着,非常乐意提供帮助、听取反馈以及开展对话。
References:
https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiQuickStart.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号