
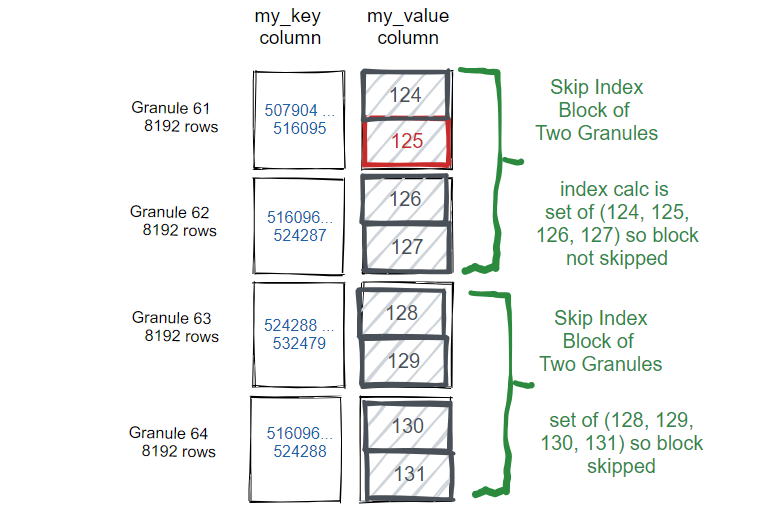
1、minmax
下面是为url建立最大最小值的跳数索引 ALTER TABLE hits_UserID_URL ADD INDEX url_skipping_index URL TYPE minmax GRANULARITY 4; ALTER TABLE hits_UserID_URL MATERIALIZE INDEX url_skipping_index;
每4个颗粒创建用一个索引,这个索引存储了url的最大值和最小值,在查询执行过程中,ClickHouse 可以在不扫描列的情况下快速检查列值是否超出范围,并跳过不满足最大最小值的颗粒块。有点类似clickhouse建立多个主键。所以当列的值随排序顺序缓慢变化时,它的效果最好。
官网说可以使用优化
- Creating a second table with a different primary key.用不同的主键建立多个表,这样子的话那就考虑两张表的数据同步问题,如果这样实现可以试下物化视图
![]() Creating a materialized view on our existing table.建立物化视图:比上一种我们不需要考虑两张表的数据同步,物化视图会自动同步。
Creating a materialized view on our existing table.建立物化视图:比上一种我们不需要考虑两张表的数据同步,物化视图会自动同步。
-
![]()
- Adding a projection to our existing table.建立投影(还不会,不知道怎么评价)
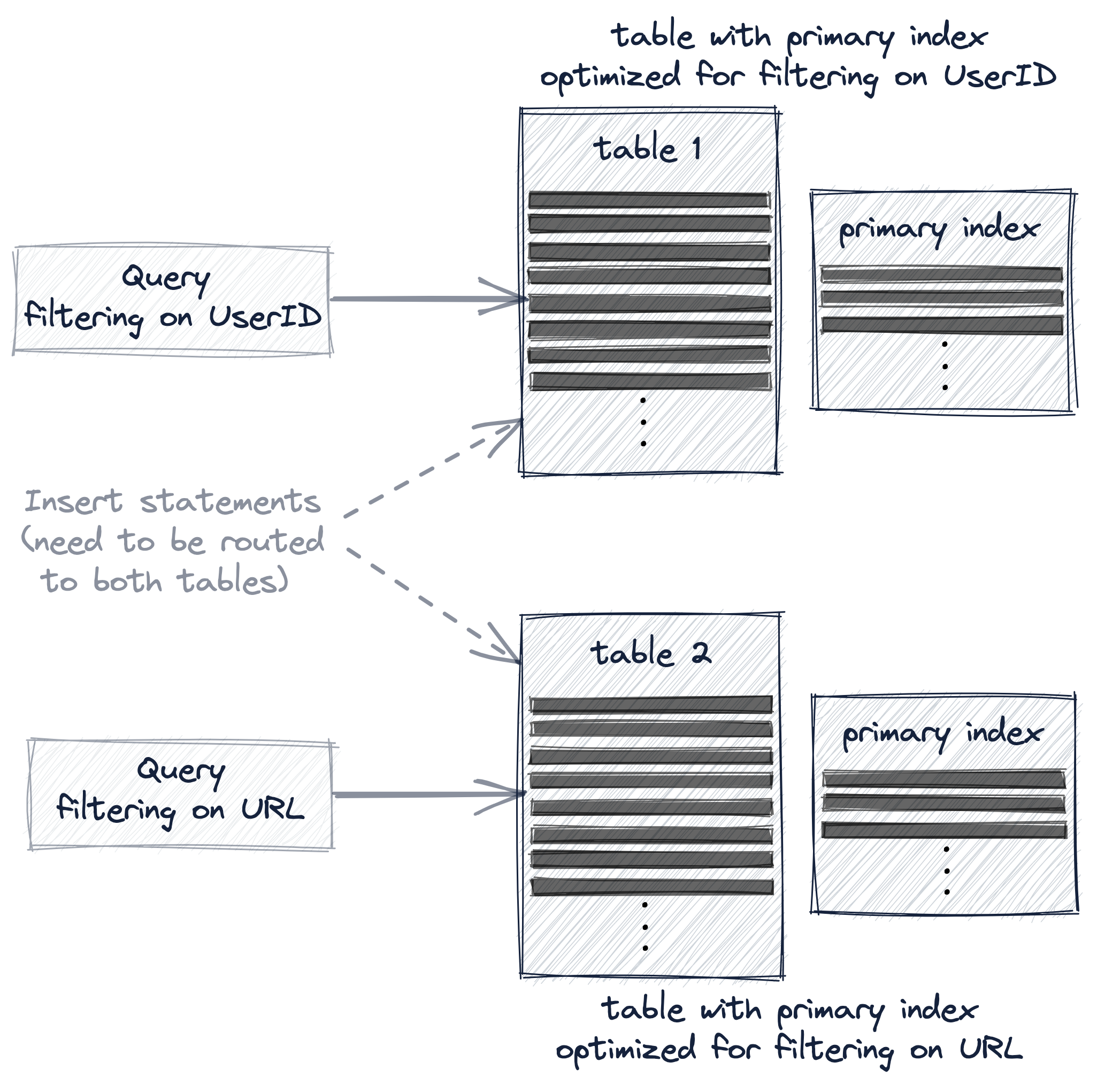


这三种我都没用过,感觉有点麻烦
键列之间的基数差越大,这些列在键中的顺序就越重要。
2、set:
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
这种轻量级索引类型接受单个参数max_size,这种索引会将指定颗粒中的所有不同值存储起来,如果不同值数量超过了max_size,该索引就不生效。
ClickHouse 在使用 where 条件查询时,如果遇到了 set 类型的跳数索引,则会检查 where 条件中的值是否在 set 集合中,如果不在就跳过这些颗粒。
ClickHouse 在使用 where 条件查询时,如果遇到了 set 类型的跳数索引,则会检查 where 条件中的值是否在 set 集合中,如果不在就跳过这些颗粒。
适合聚集那种的,特别是枚举的,例如省份
3、布隆过滤器
布隆过滤器tokenbf_v1:
这是按照token进行分词的布隆过滤器索引,它会将长文本中的单词按照非字母数字字符(如空格、数字、汉字)进行分词,每个分词就是一个token,然后这个token映射到布隆过滤器的bitmap中。
举个例子, https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree#table_engine-mergetree-data_skipping-indexes这个字符串,经过分词后,会变成如下的token
['https', 'clickhouse', 'com', 'docs', 'en', 'engines', 'table', 'engines', 'mergetree', 'family', 'mergetree', 'table', 'engine', 'data', 'skipping', 'indexes']
从分词中可以看出,比较死板,如果查询条件中有特殊字符,索引就会失效
无法支持中文、数字
布隆过滤器ngrambf_v1:
ngrambf_v1和tokenbf_v1的区别在于不是按照token分词而是按照长度分词
举个例子:Hell Flink;按照n=4分词得到的是[Hell, Fli]
优点是:解决了特殊字符以及汉字的问题
缺点是:长度一旦确定就不好修改了,查询的关键词小于n,索引就不会生效。ngrambf_v1比较适合提前知道查询的sql,针对性设置n的值。如果n设置过小会出现假阳性过高的问题。
所以在使用跳数索引的时候一定要确认自己的索引生效,不然会有出现负优化。
CREATE TABLE ck_log_test( `logType` String, `@timestamp` DateTime64(3), `ip` String, `filePath` String, `cloudId` UInt64, `time` DateTime64(3), `id` String, `tms` UInt64, `rowNumber` UInt64, `value` String, `@storageTime` DateTime64(3), `fd` UInt64 ) ENGINE = ReplicatedMergeTree() PARTITION BY toYYYYMMDD(`@timestamp`) ORDER BY (`@timestamp`); -- 建立索引 ALTER TABLE ck_log_test ADD INDEX idx_ngram3 value TYPE ngrambf_v1(48, 307200, 2, 0) GRANULARITY 1; ALTER TABLE ck_log_test MATERIALIZE INDEX idx_ngram3; EXPLAIN indexes = 1 SELECT count() FROM ck_log_test WHERE (value LIKE '%gfdsamnbvcxz-asdfghjkl-poiuytrewqlkjh-qwertyuiop%') AND (value LIKE '%[INFO]%'); ┌─explain───────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ Aggregating │ │ Expression (Before GROUP BY) │ │ Filter (WHERE) │ │ ReadFromMergeTree (ck_log_test) │ │ Indexes: │ │ MinMax │ │ Condition: true │ │ Parts: 9/9 │ │ Granules: 12929/12929 │ │ Partition │ │ Condition: true │ │ Parts: 9/9 │ │ Granules: 12929/12929 │ │ PrimaryKey │ │ Condition: true │ │ Parts: 9/9 │ │ Granules: 12929/12929 │ │ Skip │ │ Name: idx_ngram3 │ │ Description: ngrambf_v1 GRANULARITY 1 │ │ Parts: 9/9 │ │ Granules: 1253/12929 │ └───────────────────────────────────────────────────┘
分析执行计划
首先是minmax 这个是在见表时的orderby 的字段进行筛选的,因为没有带任何@timestamp所以还是完整的12929个块
接着是Partition 数据都在一个分区,所以过滤不掉
接着是primaryKey,但是在建表中没有显式指定主键索引,所以用了order by 的字段作为主键索引,也没过滤掉
重头戏来了:Skip 跳数索引,索引idx_ngram3是我们建立的,从12929个块过滤剩下1253个块。说明索引建立是生效的,也没起到作用
而且加索引是加快了读的速率,但是却影响了写的效率。读和写的一个效率的综合考虑去建立索引才是一个比较合适的方案。顾此失彼不是一个完美的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号