云娜:从计算、存储角度,谈网易数据治理工具产品实践
导读:在公司内部,业务线经常面临数据有哪些、质量如何、是否可用、能产生多大价值的困惑,并且,随着数据量的增加,计算和存储资源面临瓶颈。本次将围绕数据治理重点关注的计算、存储等方面,分享数据治理的产品实践。通过分享,一方面可以了解当前业务线主要面临的待治理的数据问题;另一方面,从计算、存储等主要方面,了解数据治理需要重点关注的内容,同时,对数据治理的整体产品实践有宏观的认识,对内部业务线的数据治理提供针对性的建议。本次分享将主要包括以下几大方面:
- 过往数据治理回顾
- 当前治理痛点
- 产品整体策略
- 未来规划
--
01 过往数据治理回顾
这部分主要介绍网易内部业务线,包括严选、传媒和音乐,做数据治理工作中遇到的问题、对应的产品解决策略,以及治理成果。
1. 专项治理背景回顾
专项数据治理活动有着以下背景:
- 随着业务的发展,数据部门的存储、计算资源会陆续遇到瓶颈;
- 难以判断是否应该继续扩容还是通过治理解决成本危机;
- 难以清晰定义和处理劣质资源;
- 缺乏统一数据标准;
- 没有明确数据的权责;
- 无法判断数据的价值意义。
2. 专项治理策略
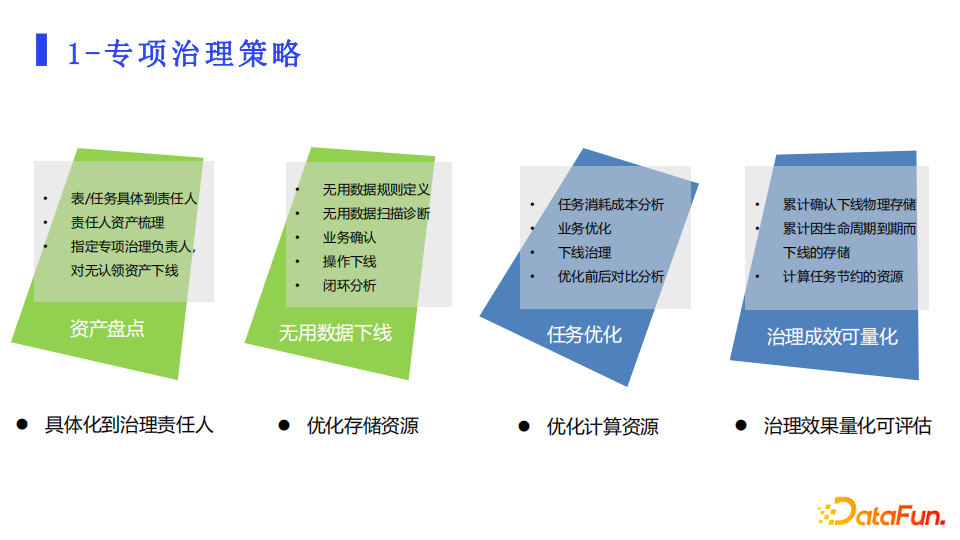
在专项治理活动中,我们对各个业务线面临的问题给出了针对性的策略。
首先是确权,明确责任人,每个数据表和调度任务都要落实到一个具体的责任人。由责任人负责推进治理中的具体任务。对于无人认领的资产,要各个业务线指定专项治理的负责人去做处理。
第二,优化存储资源。首先要定义什么是“无用数据”,把分析自动化,工具化之后进行优化操作,形成分析闭环。
第三,优化计算资源。从离线任务、实时计算到即席查询,所有的消耗计算资源的任务都要纳入成本分析核算。业务方看到相应的计算任务和成本后,才可以做优化治理的决策。另外要提供优化前后的效果分析比对来看是否达到预期。
第四,量化治理成效。存储、计算治理累计的效果、单次的效果,需要变成一种量化指标。让治理的成果一目了然。

上图是成本度量体系的设计。红色线框中是账单体系,定义了成本的算法,让用户轻松理解自己的账单费用。黄色线框中是计算成本模块,根据规则把调度执行的计算成本算好形成账单。绿色线框中会算出存储成本。上边的功能都会依赖于底层的调度任务/表的血缘等元数据信息。
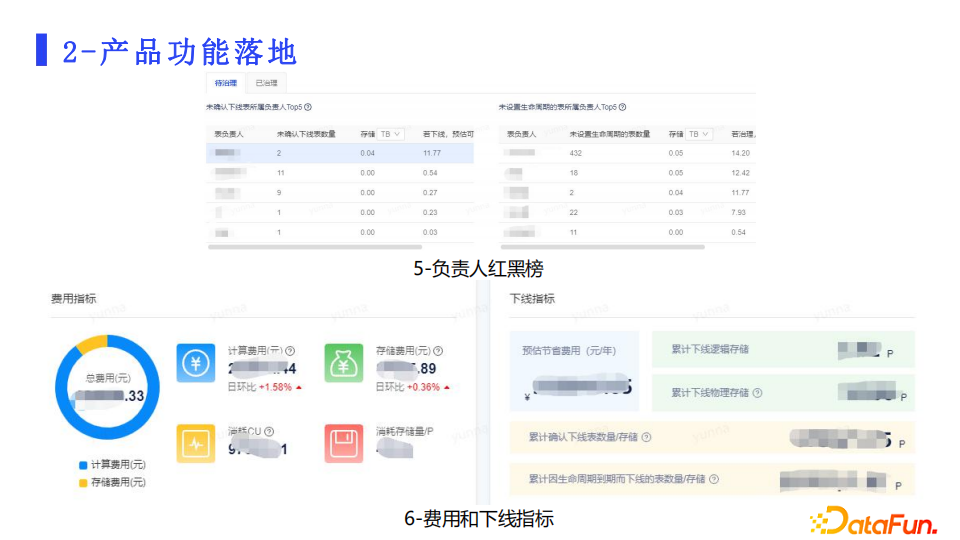
3. 产品功能落地
针对于上节所说的策略,我们做了对应产品功能的落地。整体有八个功能模块:
- 任务/表具体化到责任人:负责人可以查看、筛选、治理、交接自己负责的资源。
- 无用数据下线功能:负责人使用这个模块来完成下线治理操作,下线的资源会放入回收站一段时间后删除。
- 表生命周期设置:任何资源,包括内部表和外部表都需要设置生命周期,到期后如果不进行延期就会自动下线删除。
- 计算任务成本分析:给用户提供计算成本的明细视图。
- 负责人红黑榜:通过这个抓手,把各个负责人的资产健康好坏做一个榜单,推动促进治理。
- 费用和下线指标:这块展示治理的成效,用户在这里可以看到治理累计下线了多少逻辑数据、物理数据、节省的费用。也包括自动下线的成效。
- 邮件通知 & 内部工具通知:通知内容分为了两个视角,一方面是治理负责人,可以了解当前自己还有哪些数据需要进行治理,治理后可以给项目节省多少年费用;另一方面是项目的管理员/负责人,可以知道当前项目下一共还有多少数据需要治理,治理后总共可以节省多少年费用,也可以知道整个项目中治理做的好的负责人Top5,以及还有哪些人占据的成本最多,可以以此为依据,催促负责人进行治理工作。
下边是产品功能截图:


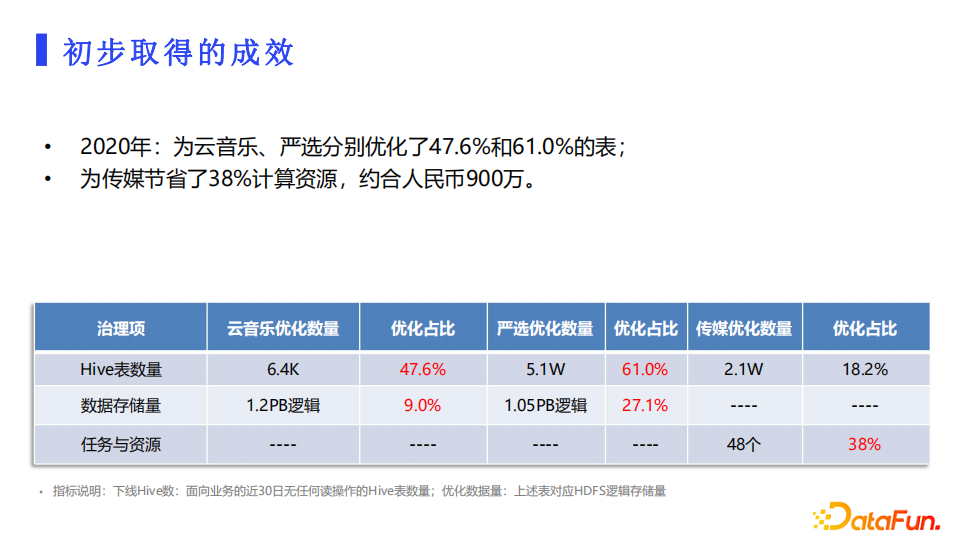
4. 初步取得成效
从下图中可以看到我们的治理成果数据。通过上述的多种策略,初步取得了治理成效。2020年,为云音乐和严选分别优化了47.6%和61%的表,也为传媒业务线节省了约38%的计算资源,数据治理各个业务线的专项活动策略得到了业务方的肯定。
--
02 当前治理痛点
这部分主要介绍当前治理的痛点,以及我们在制定落地策略的时候,会遇到的各种各样的“坑”。
1. 当前遇到的痛点

上图是我们已经解决的一些痛点:
- 首先就是数据开发中的痛点。在做开发过程当中,缺少经验的同学,会创建一些不规范的目录;没有按照规范创建外表等问题都会导致在下线删除资源时候带来丢失数据的风险。
- 由于业务数据需求的优先级高于治理,所以开发会疲于治理,缺少动力。再加上由于人员变更带来的大量历史遗留任务,治理起来比较费力。
- 没有形成治理的闭环,周期性的被动去做治理,没有形成长效治理运营机制,无法形成良性循环。
- 治理效果量化粗糙,导致价值无法精准体现,影响治理参与人的积极性。
2. 依旧填不完的数据“坑”

当前我们依然面临成本问题,对于历史数据较多的公司,数据治理需要一个过程。这个过程“前路漫漫,道阻且长”,我们亟待解决的几方面问题包括存储成本、计算成本、数据质量、模型规范、数据安全和数据价值这几方面。具体如下图所示:
--
03 产品整体策略
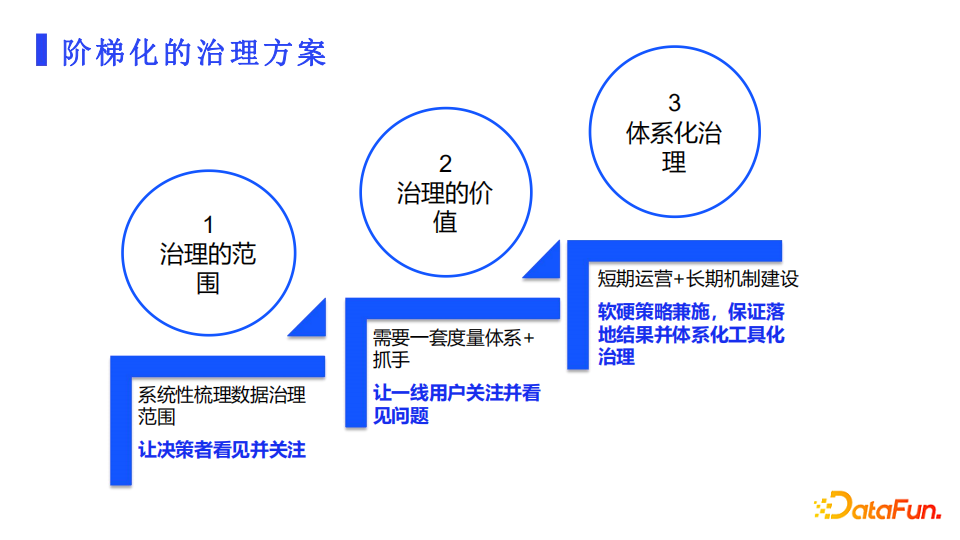
正如上文提到的诸多痛点,解决起来无法一蹴而就。我们选择采取了阶梯化的治理方案,整体分为三个阶段:
- 首先就是要明确治理的范围,从数据产出到数据管理的整体流程中,明确哪些要做,顺序是什么,产出的预期效果是什么。能够让决策者知道我们行动的范围和影响范围。
- 第二就是明确和量化治理的价值。通过一套度量体系作为抓手,让管理者在内的所有干系人看到我们治理会带来的价值,为治理的行动创造良好的环境。
- 第三就是体系化治理,把短期运营治理的方法策略工具化产品化,在流程上形成长期建设机制,形成一个良性的闭环,提升治理的效率和数据质量。让所有人都从中受益看到效果。
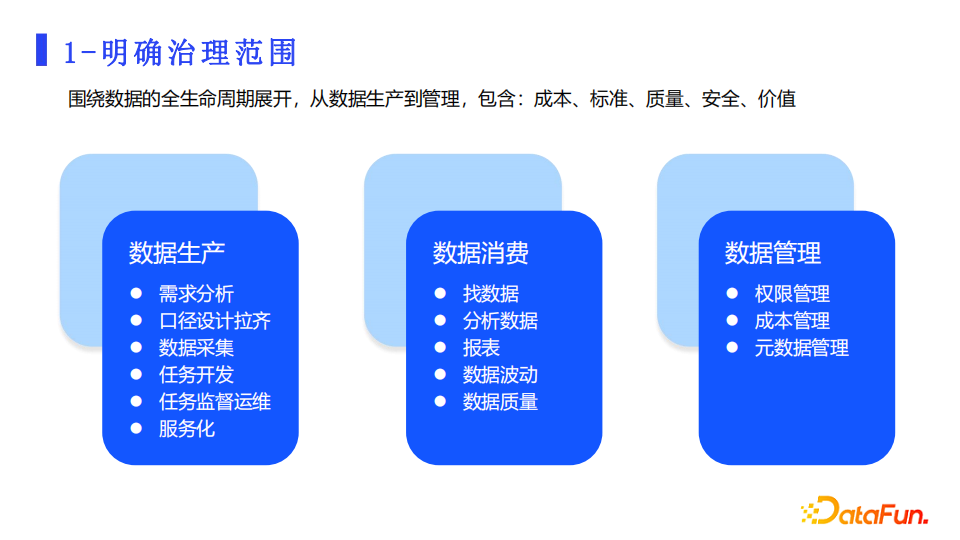
1. 明确治理范围
我们围绕数据生命周期,从生产、消费到管理来梳理治理的范围。在数据生产阶段,需要对需求进行分析,明确业务口径,对数据进行规范采集、任务开发和监控运维;在数据消费阶段,涉及到快速的查找数据,对数据的分析和对数据质量的探查;在数据管理过程中,包含权限和成本管理等。整个流程涉及到成本、标准、质量、安全和价值,各个阶段都会面临对数据的治理工作。
2. 量化数据治理价值
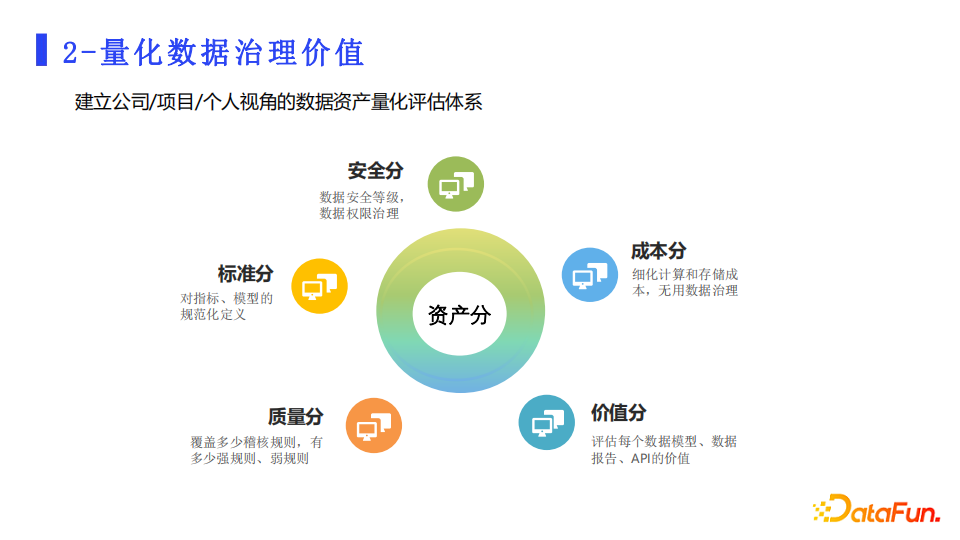
我们基于数据的全生命周期,通过资产的健康分来体现数据治理的价值,健康分涵盖了成本、质量、安全、标准和价值五个维度,每个维度都要有可量化的指标项。
- 首先是成本分,治理前后的成本变化可以体现治理的价值,成本是也衡量业务数据使用ROI的必要指标。
- 第二是价值分,价值分体现衡量数据资产在业务上的重要程度,也是计算业务ROI的重要数据。有了成本和价值分,就为评估数据资产的优劣打了一个基础。
- 第三是质量分,通过一组规则来体现数据质量,这个是体现数据负责人和开发团队对数据质量管理控的好坏,同时为数据质量的治理提供了参考依据。
- 第四是标准分,涉及到数仓模型规范。规范的模型利于上层应用的效率,也是治理的一个重点。
- 第五是安全分,涉及到资产安全等级和权限管控的好坏。
- 五个方面,每一个方面都会有一个计算权重,最后形成资产健康分。不同健康程度的资产涉及到不同的处理策略,比如说某人负责的数据低于某一个分值的时候,我们会限制此人新建任务的优先级。我们通过类似的手段来推进数据治理的运营和数据健康的提升。
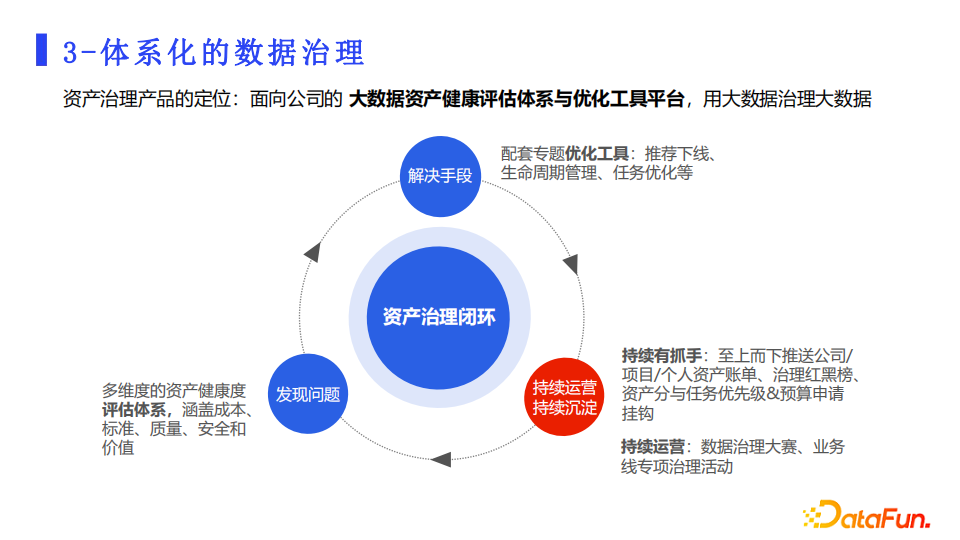
3. 体系化的数据治理
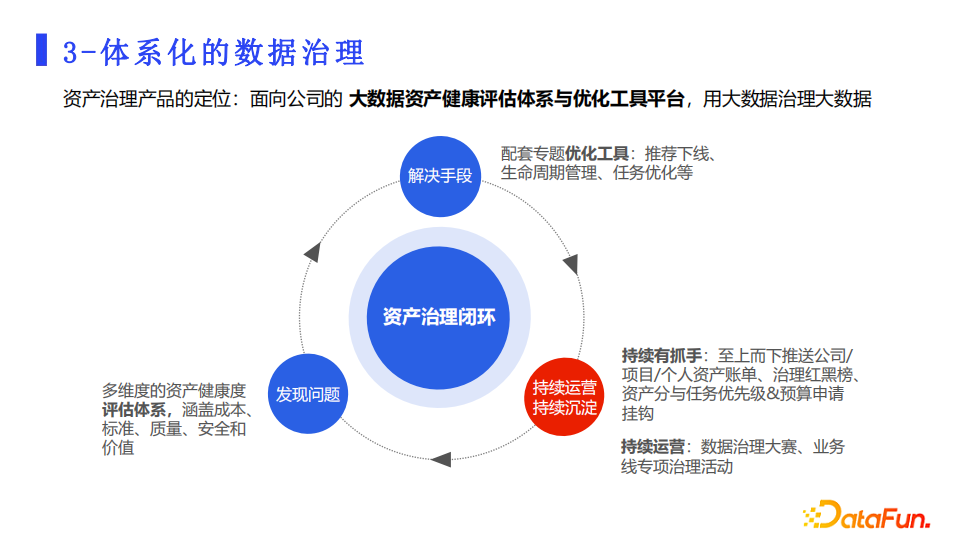
最后就是把数据治理进行体系化,让数据治理活动形成闭环,能够持续进行,从而保证数据资产的健康。首先是发现问题,我们配套多维度健康评估体系来量化发现问题。同时通过工具把问题和建议的解决方式推送给负责人去解决问题。配套资产账单、治理红黑榜,同时把健康分和预算申请进行关联,促使治理能够形成闭环。最后日常我们会做数据治理大赛、业务专项治理等专题活动来推动数据治理运营,让数据治理形成一个良性的循环。
--
04 未来规划
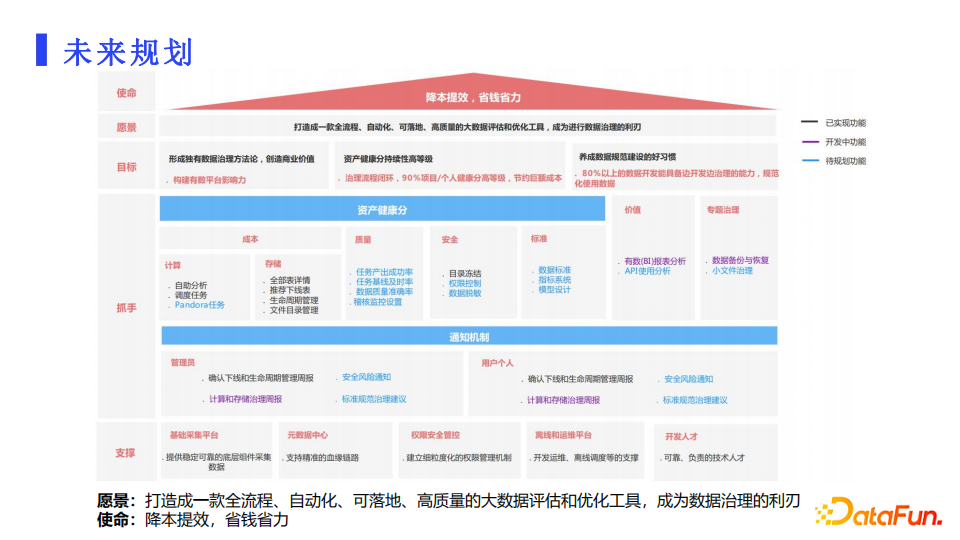
接下来用一个房子图来介绍下我们的未来规划。我们的愿景是打造一款全流程、自动化、可落地、高质量的大数据评估和优化工具。数据治理工具的使命本是降本提效,省钱省力。
房子图中愿景以下分别是目标、抓手和支撑层。图中可以看到,支撑层的完成度更高,因为这层是一个基础。抓手层的两大块分别是健康分和通知机制,这两块已经实现了部分功能,已经能够初步形成治理的闭环,接下来我们会继续围绕健康分把质量、安全和标准这部分做好。通过围绕着健康分把数据治理的工作运营好,形成一个从问题发现到快速治理的高效闭环,来保证数据使用的效率、质量和安全,充分发挥数据价值。
--
05 精彩问答
Q:怎么让数据治理工作能够内嵌到开发工作当中,而不是多出来的一项工作?
A:很多业务在使用数据的时候,是只开发不治理,这种方式会遗留下来不少需要治理的问题。很难避免要去单独做数据治理。如果在业务开发初始阶段就把数据规范、指标体系、指标口径有一个规划设计,并且按照规范落实。那么后续会减少很多治理的动作。比如一开始创建表的时候,就要指定好是否分区表,数据的生命周期,这样到期后,就可以自动删除掉,也不会涉及这个表占用了很多存储,需要额外梳理和确定是否需要下线的工作。
Q:资产健康资产分是基于什么得出来的?
A:健康分涉及到很多方面,成本、价值、规范、质量、安全等等。健康分的五个维度,都是从实际需要治理的任务抽象出来的,涉及到数据生命周期的各个环节。有了这样一个资产健康分,再和用户的开发权限申请和资源申请进行挂钩,能够促进数据治理形成一个高效的闭环。
Q:数据治理,一般由谁来做?
A:数据治理涉及到资源方、使用方和管理方。一般来说我们会明确具体的负责人,他有义务对负责的表、任务做治理。实际执行时候,会碰到一些任务最早的负责人离职了,针对这种我们会指定专人治理。专人除了把自己负责的任务、表做好治理之外,还需要处理历史遗留的治理任务。
Q:中台当中的数据治理都做什么?只是数据库表的原数据吗?
A:其实刚才也说过,治理不只针对于数据库表的原数据。数据从入仓到加工到后续生命周期的管理的这个流程上,每个阶段都会涉及到数据治理。比如创建模型的时候,涉及到指标口径的定义和模型的规范。再比如离线开发中的ETL加工,会涉及到数据源配置,数据质量校验等,这些都涉及到治理的动作。那么在应用层出报表时候,涉及到是否要建中间表等,也要有规范。整个生产应用的链条上都会涉及到治理,表和元数据只是其中的一方面,其他的比如涉及到计算资源的治理、安全的治理等。
Q:数据治理一般要花多长时间?
A:其实数据治理没有一个既定的时间就能够完成它,它不是做完之后就不用再做了,而是一个持续的过程。因为你的项目当中的表,你的计算任务随着业务的需求肯定是慢慢在增加,一直在增加的。就像收拾屋子一样,只要屋子有人用,总会再需要收拾。
Q:计算成本是怎么核算的?
A:计算成本是看任务对CPU的消耗,折算成以CU为单位的数据,然后就可以根据硬件成本折算成费用。
今天的分享就到这里,谢谢大家。
分享嘉宾:

本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号