如何构建阿里小蜜算法模型的迭代闭环?
导读:伴随着AI的兴起,越来越多的智能产品诞生,算法链路也会变得越来越复杂,在工程实践中面临着大量算法模型的从0到1快速构建和不断迭代优化的问题,本文将介绍如何打通数据分析-样本标注-模型训练-监控回流的闭环,为复杂算法系统提供强有力的支持。
新技术/实用技术点:
- 实时、离线场景下数据加工的方案选型
- 高维数据的可视化交互
- 面对不同算法,不同部署场景如何对流程进行抽象
01. 背景 - 技术背景及业务需求
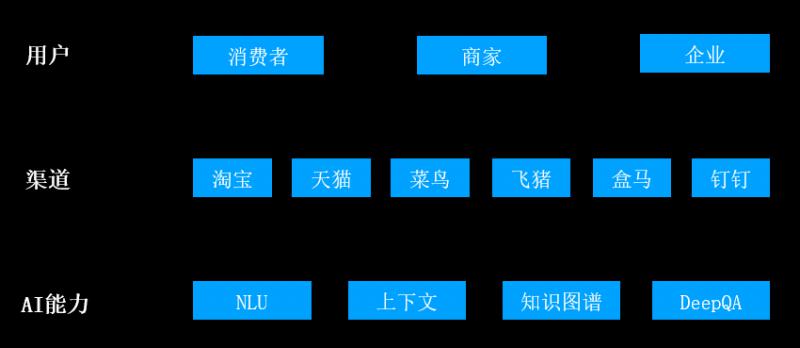
小蜜系列产品是阿里巴巴为消费者和商家提供的智能服务解决方案,分别在用户助理、电商客服、导购等方面做了很多工作,双十一当天提供了上亿轮次的对话服务。其中用到了问答、预测、推荐、决策等多种算法模型,工程和算法同学在日常运维中会面临着如何从0到1快速算法模型并不断迭代优化,接下来将从工程角度介绍如何打通数据->样本->模型->系统的闭环,加速智能产品的迭代周期。
![file]()
- 实现
实现这一过程分为2个阶段:
0->1阶段:
模型冷启动,这一阶段更多关注模型的覆盖率。
实现步骤:
A. 抽取对话日志作为数据源
B. 做一次知识挖掘从日志中挑出有价值的数据
C. 运营人员进行标注
D. 算法对模型进行训练
E. 运营人员和算法端统一对模型做评测
F. 模型发布
![file]()
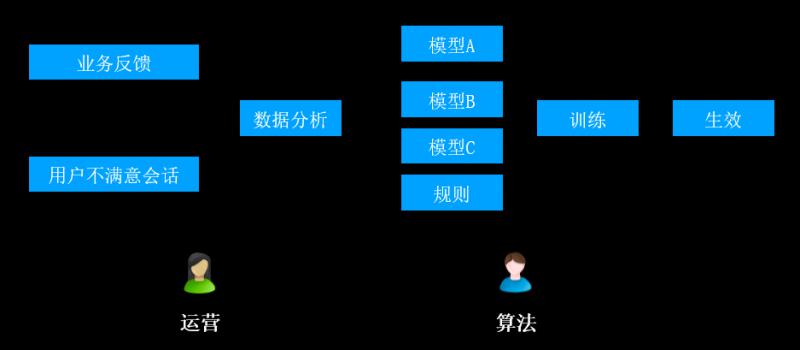
1->100阶段:
badcase反馈和修复阶段,主要目标是提升模型的准确率。
实现步骤:
A. 运营端根据业务反馈(顶踩按钮)、用户不满意会话(如:转人工)收集badcase信息
B. 进行数据分析,将分析结果给到不同的模型模块、规则模块
C. 算法端对以上模型分别进行训练
D. 最终发布到线上生效
![file]()
- 痛点
在以上过程中,会遇到如下几个痛点:
A. 不同算法需要不同的标注交互形式,如何快速支持
B. 运营方的标注凭借个人感觉,缺少指导,无法保障质量
C. 线上badcase如何快速发现和修复
D. 机器人中部署了上百个算法模型,日常维护需要占用工程师大量的精力
E. 数据样本在业务和算法之间来回传递,有安全隐患
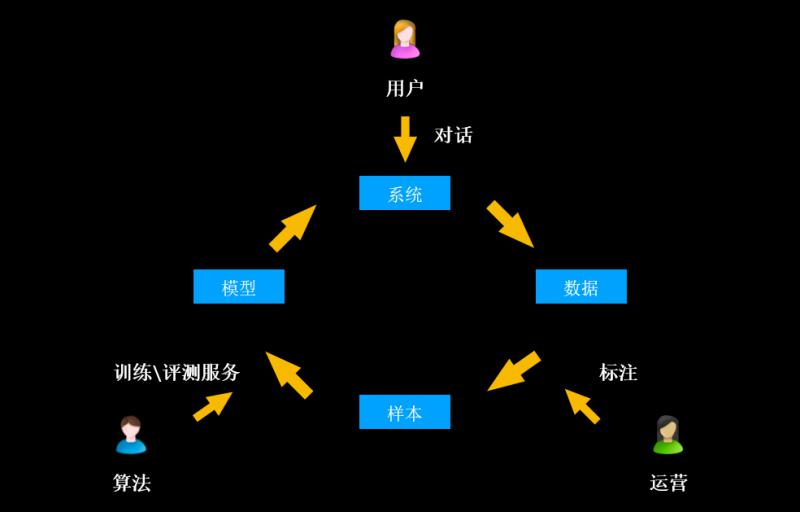
02. 闭环迭代模型的产生 - 模型训练闭环
基于以上的痛点,阿里小蜜团队构建了模型训练闭环。该闭环系统主要包括对话系统层、数据层、样本层和模型层这4个部分。
![file]()
彼此之间的关系、流程如下:
A. 对话系统层:用户端会跟机器人系统进行对话
B. 对话产生的日志经过数仓埋点进入到数据层
C. 数据层由运营人员做标注
D. 完成标注的数据作为样本,借助算法团队提供的训练/评测服务,进入到模型层
E. 模型发布到系统中,形成训练闭环 - 系统 => 数据
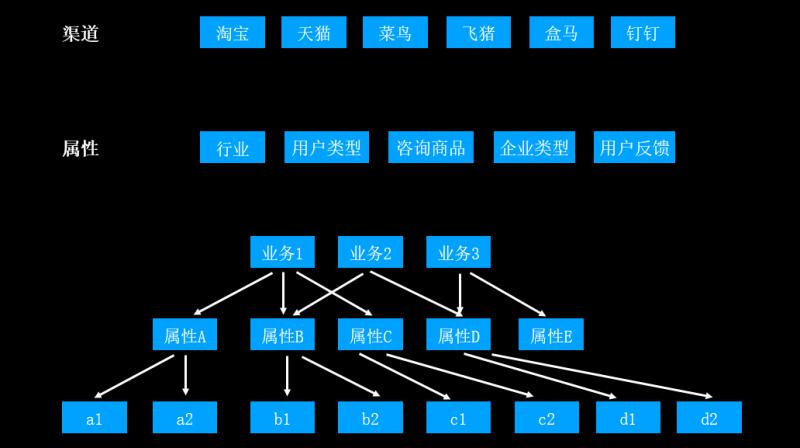
① 多维数据查询
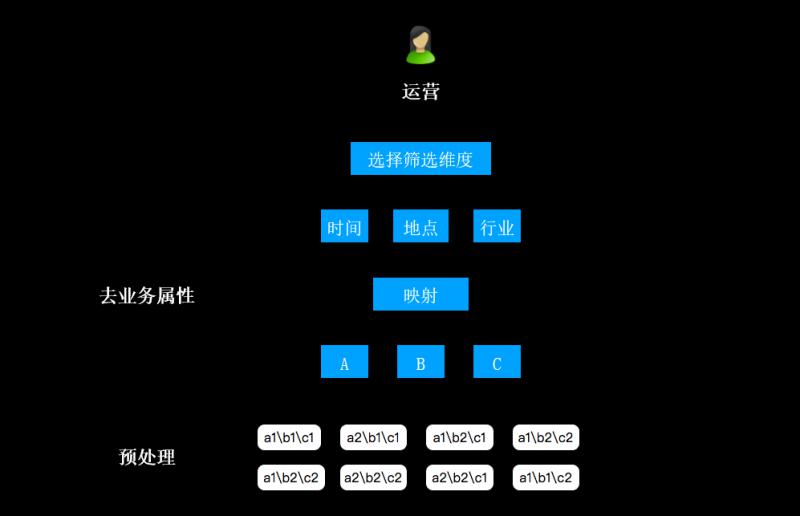
这一部分讲述如何从系统层到达数据层,这里会涉及到“多维数据查询”这样一个概念。前面提到,数据来源的渠道是多种多样的;这些数据会具备多种多样的属性,例如:行业属性、用户类型属性等。不同业务的对话日志带有各自的业务属性。
![file]()
在应用多维数据查询的过程中,难点是属性相交等问题。平台的第一项工作就是数据预处理,遍历出所有的业务-属性组合;运营人员取数据的时候,先选择业务维度;接着从业务维度到数据维度进行一层映射,从而去掉其业务属性(例如,时间、地点、行业等维度分别映射成A、B、C)
![file]()
② OLAP与“数据立方体”
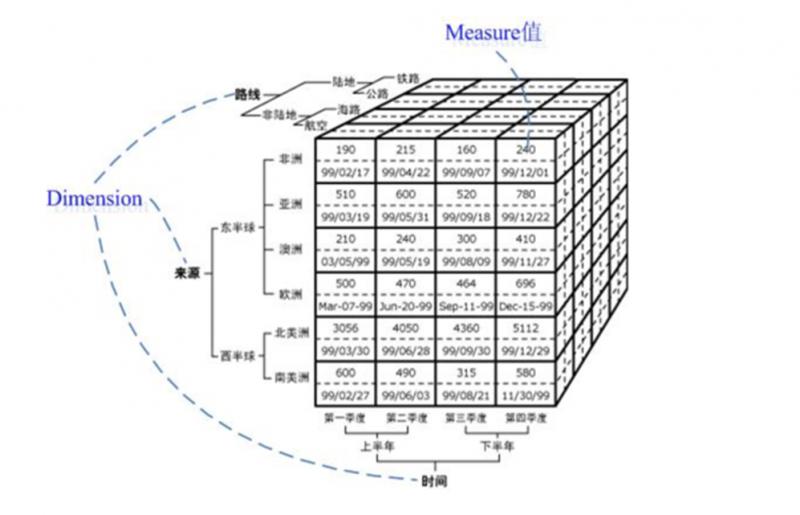
这里用到了联机分析处理(OLAP ,On-Line Analytical Processing,一种数据动态分析模型)技术。首先会构造“数据立方体”这样一种数据结构,将数据分成多种维度,包括:来源维度、路线维度、时间维度。
![file]()
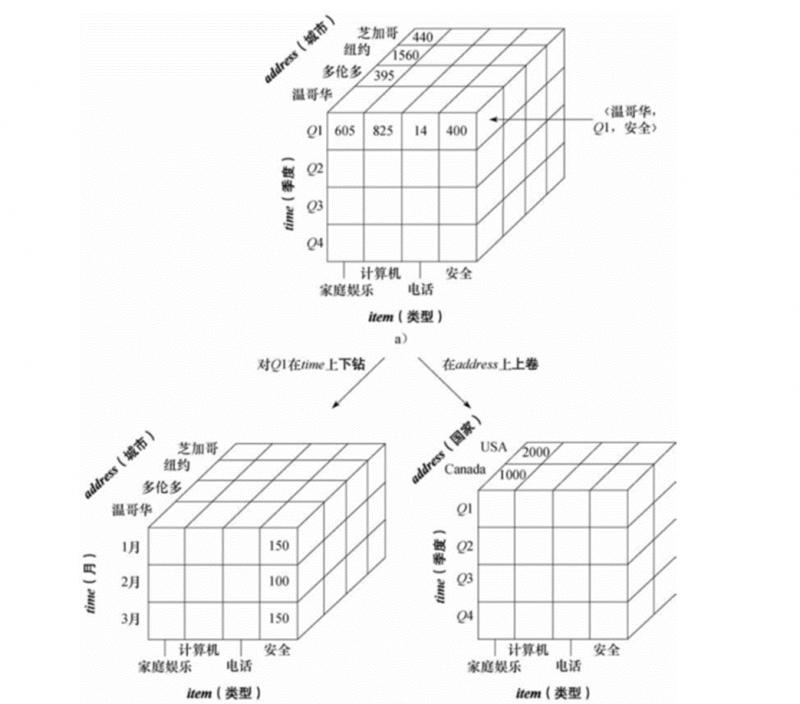
对数据立方体由上卷和下钻这两种基本操作,生成新的立方体。下图中,右半部分是将城市维度进行了上卷操作,左半部分是将季度维度进行了下钻操作。
![file]()
数据立方体结构的不足:
A. 维度类型。对于商家这种百万数量级的维度,搜索起来效率低下。针对这种缺点,选择对于重点商家重点维度进行存储。
B. 多条件的or关系查询,在这种立方体结构中无法实现。
C. 枚举数量和效率的平衡。需要根据具体覆盖业务定义属性等。 - 数据 => 样本
① 标注组件
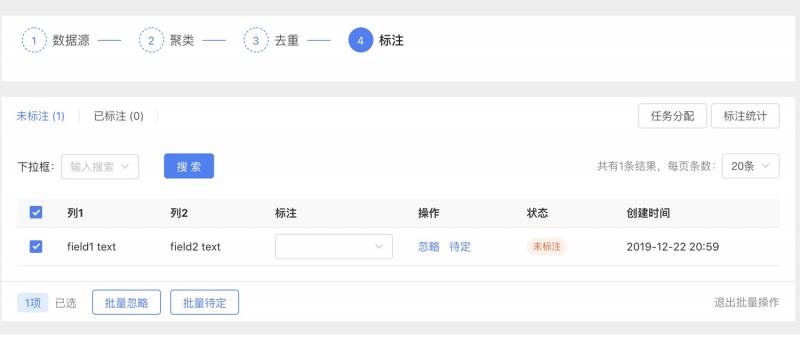
数据标注环节由“人工智能训练师”这个角色参与,标注形式会根据算法的选择而调整,包括:标签、实体、属性间关系等。
如下图所示:
![file]()
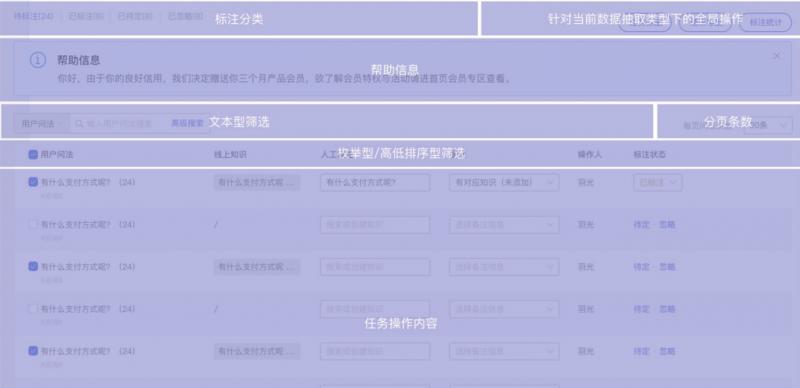
组件包括状态栏、搜索框、表格(支持配置),可进行标注分类、文本型精选、排序型筛选、任务操作内容等多个模块(详见下图)。
![file]()
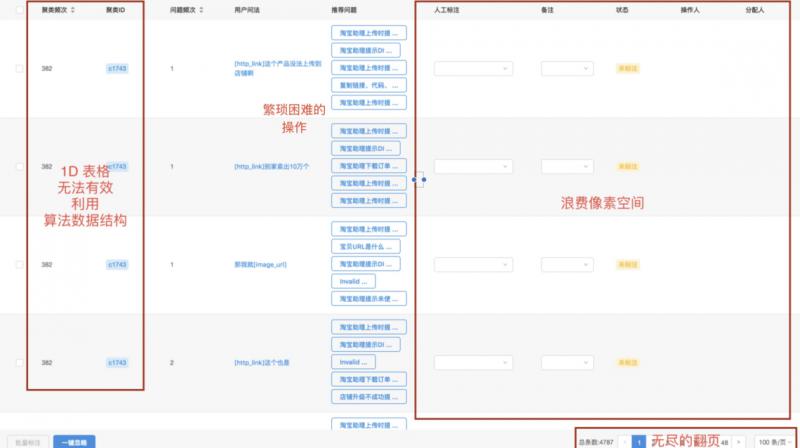
这样的组件有如下的缺点:
A. 1D表格无法有效利用算法数据结构
B. 操作繁琐困难
C. 浪费像素空间
D. 无尽的翻页
![file]()
② 高维数据可视化
基于组件存在的以上种种缺点,我们选择了将数据降维。
什么是高维数据?
高维数据包括:
A. 机器人阿里小蜜的文本数据
B. 图片
C. 语音数据
可视化后的高维数据长什么样子?
![file]()
可视化前
![file]()
可视化后
上图是对文本数据可视化后的结果。实现步骤:
A. 对文本数据进行聚类,根据相似度变成平面结构
B. 用颜色区分类别
这种方式可以直观看出线上的语料分布,包括分布类别、分布集中趋势等。
这里用到的技术方案包括:
A. 降维:主要用PCA和T-SNE两种降维方式
B. 向量化:数据拆分之后,将数据转变为可比较的表示形式。对于文字,主要使用word2vec;而对于图片,主要使用phash编码。
C. 聚类:聚类主要使用k-means。
![file]()
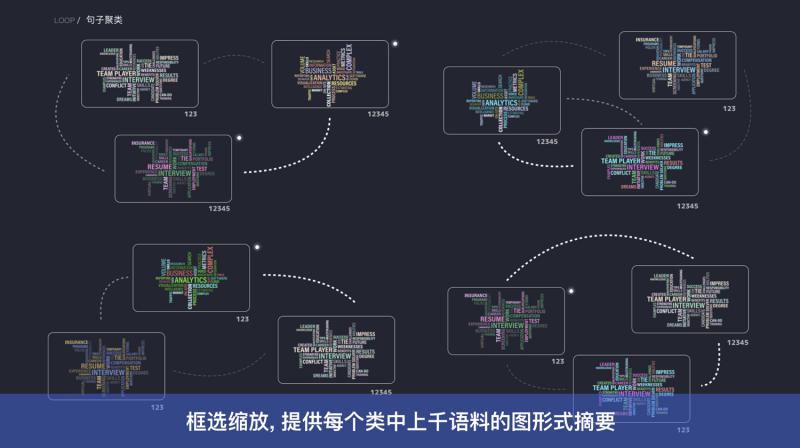
③ 散点图塌缩及其交互
下图中的左图是聚类后的效果图。聚类完成后,每一类图片的每一类都会分布到一起;再通过散点图塌缩算法,将每一个类压缩成一个散点,通过颜色区分类别种类。
利用这种方式,可以找出badcase中占比最高的一类,从而进行修复。
![file]()
在对类的交互中,有一些特殊的操作,例如:框选。上图右图的散点图中,可以通过框选的方式抽取每一类的关键词。
![file]()
03. 实时布防 - 语料关键词的识别与添加
![file]()
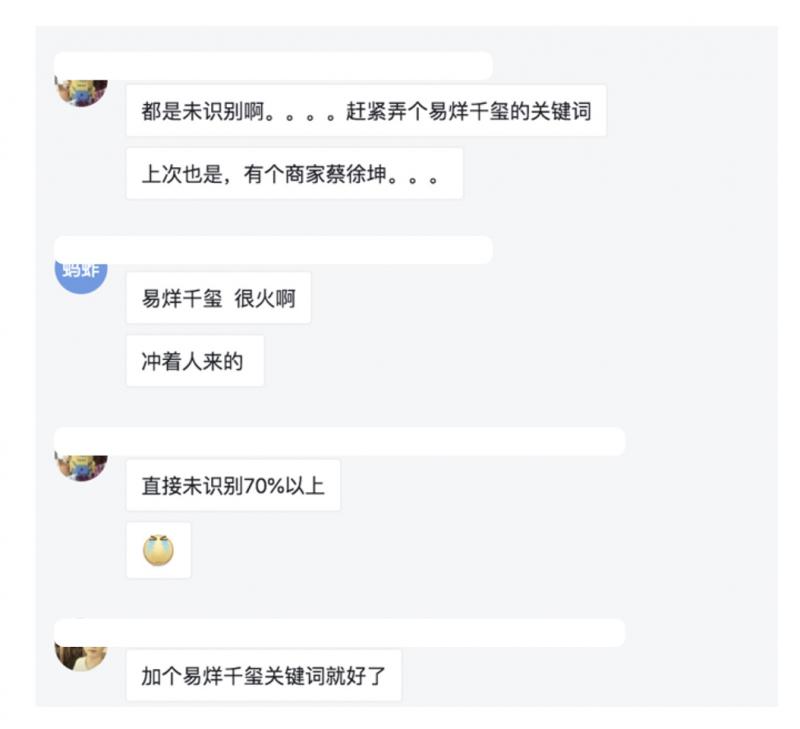
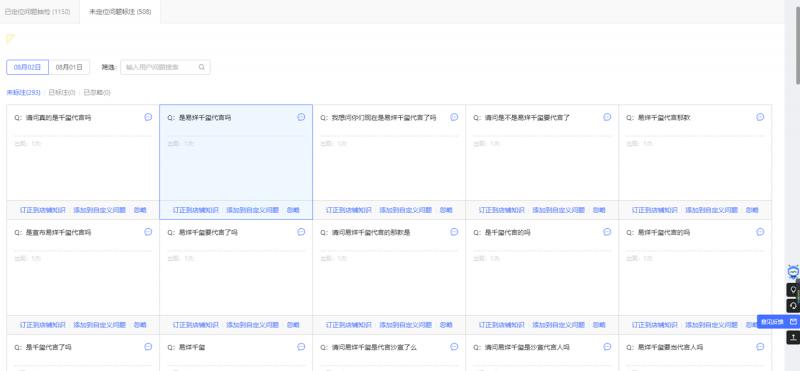
上图是某一天猫商家的海报图:某商家正在搞一个促销活动,找易烊千玺作为代言人。由于机器人预先不知道会有这样一个活动发生,模型中自然不包含这样的关键词。商家发现当天的未识别语料全部都和“易烊千玺”相关,但是机器人不识别这个关键词(未识别率达70%以上)。怎样快速帮商家解决这类问题呢?
![file]()
- 实时布防
![file]()
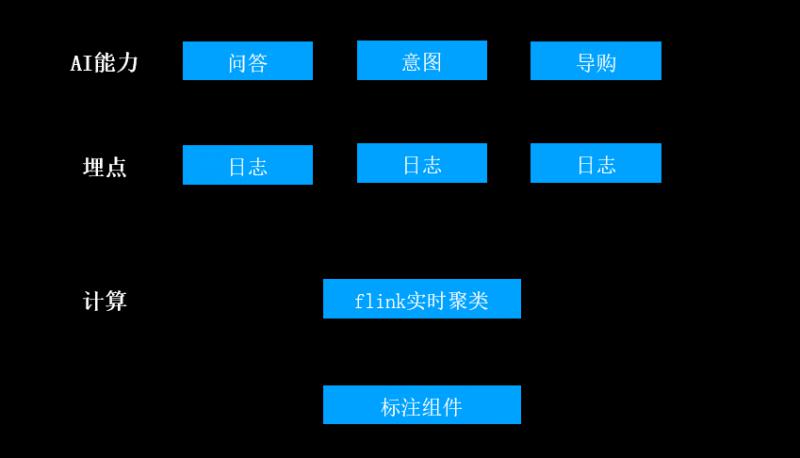
这类的AI能力如何做实时布防呢?将这类问答、意图等AI能力在自己的服务器上以日志的形式做埋点,服务器会将日志收集起来通过flink平台做实时流式聚类,商家工作台通过标注组件的形式展现当前时段的高频问题,并通过交互式选项选择如何修复(以上图中的蓝色选定区域为例),从而让机器人能够识别该语料。
![file]()
- 数据加工
从业务日志中提取模型需要的语料需要进行一些基本的算法加工,这些步骤除了面临大数据的压力,研发工程师还要考虑对这种加工能力的封装和复用。
![file]()
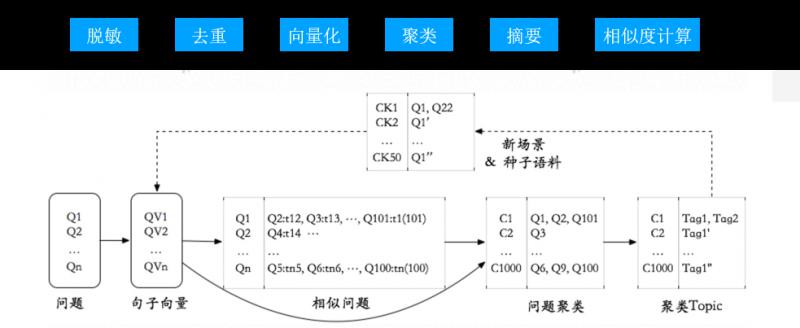
A. 首先,对日志数据做脱敏:将日志中的手机号、地址、人名等去掉,对单字型文本、语聊型文本的去除;
B. 接下来对数据做去重和向量化;
C. 下一步是对处理完成的数据做聚类;
D. 聚类后的数据做摘要,进而做相似度计算。
整个过程需要很多的算法模块,每一个模块都会封装成一个算法组件,提供到不同的模型迭代中。上图的下半部分就是语料经过了不同算法模块的变化,从向量到聚类,进而抽取不同Topic。
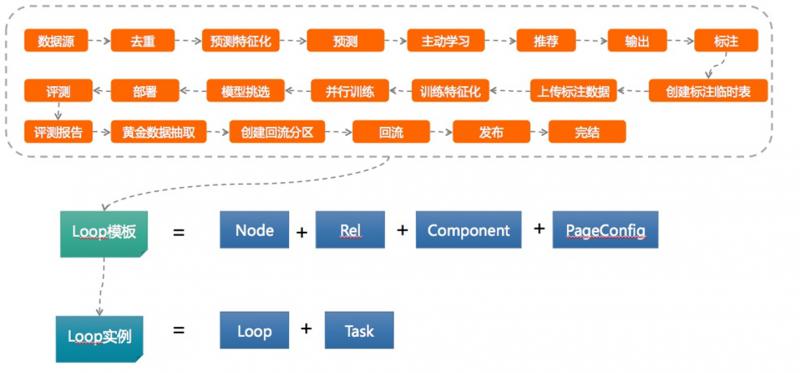
下图是以上过程抽象成的模板。
![file]()
模板中包含了算法组件、标注组件、训练组件等不同的组件;运营人员在线上可以挑选不同组件配置模板来优化对应的模型。
在模板执行的过程中,可使用mapreduce组件、UDF组件以及Spark组件。Spark组件是目前通用性较强的组件,既可本地调度,又可远程调度。 - 构建数据处理引擎
基于Spark构建数据处理引擎,分为客户端和计算集群两个系统。客户端包括组件库、调度引擎,以及Spark Client Runner。
![file]()
这种架构的好处:算法可以在本地开发spark组件,直接集成到模板中;同时支持远程集群模式和本机轻量级调度,大小数据量都适用;同时spark拥有 SQL和spark mllib两个组件库,研发通过封装可以直接开放给业务使用。
本次分享就到这里,谢谢大家。
欢迎加入DataFunTalk交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:交流,逃课儿会自动拉你进群。








 浙公网安备 33010602011771号
浙公网安备 33010602011771号