大数据初级笔记一:大数据入门介绍
人人都是数据咖
-
大数据产生背景
1.信息基础设施持续完善,包括网络带宽的持续增加、存储设备性价比不断提升,犹如高速公路之于物流,为大数据的存储和传播准备物质基础。
2.互联网领域的公司最早重视数据资产的价值,最早从大数据中淘金,并且引领大数据的发展趋势。
3.云计算为大数据的集中管理和分布式访问提供了必要的场所和分享的渠道。大数据是云计算的灵魂和必然的升级方向。
4.物联网与移动终端持续不断的产生大量数据,并且数据类型丰富,内容鲜活,是大数据重要的来源。
-
大数据发展重大事件
2005年,hadoop项目诞生。Hadoop其最初只是雅虎公司用来解决网页搜索问题的一个项目,后来因其技术的高效性,被Apache Software Foundation公司引入并成为开源应用
2008年末,“大数据”得到部分美国知名计算机科学研究人员的认可,它使人们的思维不仅局限于数据处理的机器,并提出:大数据真正重要的是新用途和新见解,而非数据本身。此组织可以说是最早提出大数据概念的机构。
2009年印度政府建立了用于身份识别管理的生物识别数据库,联合国全球脉冲项目已研究了对如何利用手机和社交网站的数据源来分析预测从螺旋价格到疾病爆发之类的问题。
2009年中,美国政府通过启动Data.gov网站的方式进一步开放了数据的大门,这个网站向公众提供各种各样的政府数据。该网站的超过4.45万量数据集被用于保证一些网站和智能手机应用程序来跟踪从航班到产品召回再到特定区域内失业率的信息,这一行动激发了从肯尼亚到英国范围内的政府们相继推出类似举措。
2009年,欧洲一些领先的研究型图书馆和科技信息研究机构建立了伙伴关系致力于改善在互联网上获取科学数据的简易性。
2010年2月,肯尼斯库克尔在《经济学人》上发表了长达14页的大数据专题报告《数据,无所不在的数据》。库克尔在报告中提到:“世界上有着无法想象的巨量数字信息,并以极快的速度增长。从经济界到科学界,从政府部门到艺术领域,很多方面都已经感受到了这种巨量信息的影响。科学家和计算机工程师已经为这个现象创造了一个新词汇:“大数据”。库克尔也因此成为最早洞见大数据时代趋势的数据科学家之一。
2011年2月,IBM的沃森超级计算机每秒可扫描并分析4TB(约2亿页文字量)的数据量,并在美国著名智力竞赛电视节目《危险边缘》“Jeopardy”上击败两名人类选手而夺冠。后来纽约时报认为这一刻为一个“大数据计算的胜利。”
2011年5月,全球知名咨询公司麦肯锡(McKinsey&Company)肯锡全球研究院(MGI)发布了一份报告——《大数据:创新、竞争和生产力的下一个新领域》,大数据开始备受关注,这也是专业机构第一次全方面的介绍和展望大数据。报告指出,大数据已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。报告还提到,“大数据”源于数据生产和收集的能力和速度的大幅提升——由于越来越多的人、设备和传感器通过数字网络连接起来,产生、传送、分享和访问数据的能力也得到彻底变革。
2011年12 月,工信部发布的物联网十二五规划上,把信息处理技术作为4 项关键技术创新工程之一被提出来,其中包括了海量数据存储、数据挖掘、图像视频智能分析,这都是大数据的重要组成部分。
2012年1月份,瑞士达沃斯召开的世界经济论坛上,大数据是主题之一,会上发布的报告《大数据,大影响》(Big Data, Big Impact) 宣称,数据已经成为一种新的经济资产类别,就像货币或黄金一样。
2012年3月,美国奥巴马政府在白宫网站发布了《大数据研究和发展倡议》,这一倡议标志着大数据已经成为重要的时代特征。2012年3月22日,奥巴马政府宣布2亿美元投资大数据领域,是大数据技术从商业行为上升到国家科技战略的分水岭,在次日的电话会议中,政府对数据的定义“未来的新石油”,大数据技术领域的竞争,事关国家安全和未来。并表示,国家层面的竞争力将部分体现为一国拥有数据的规模、活性以及解释、运用的能力;国家数字主权体现对数据的占有和控制。数字主权将是继边防、海防、空防之后,另一个大国博弈的空间。
2012年4月,美国软件公司Splunk于19日在纳斯达克成功上市,成为第一家上市的大数据处理公司。鉴于美国经济持续低靡、股市持续震荡的大背景,Splunk首日的突出交易表现尤其令人们印象深刻,首日即暴涨了一倍多。Splunk是一家领先的提供大数据监测和分析服务的软件提供商,成立于2003年。Splunk成功上市促进了资本市场对大数据的关注,同时也促使IT厂商加快大数据布局。
2012年7月,联合国在纽约发布了一份关于大数据政务的白皮书,总结了各国政府如何利用大数据更好地服务和保护人民。白皮书还指出,人们如今可以使用的极大丰富的数据资源,包括旧数据和新数据,来对社会人口进行前所未有的实时分析。联合国还以爱尔兰和美国的社交网络活跃度增长可以作为失业率上升的早期征兆为例,表明政府如果能合理分析所掌握的数据资源,将能“与数俱进”,快速应变。
2012年7月,为挖掘大数据的价值,阿里巴巴集团在管理层设立“首席数据官”一职,负责全面推进“数据分享平台”战略,并推出大型的数据分享平台——“聚石塔”,为天猫、淘宝平台上的电商及电商服务商等提供数据云服务。随后,阿里巴巴董事局主席马云在2012年网商大会上发表演讲,称从2013年1月1日起将转型重塑平台、金融和数据三大业务。马云强调:“假如我们有一个数据预报台,就像为企业装上了一个GPS和雷达,你们出海将会更有把握。”因此,阿里巴巴集团希望通过分享和挖掘海量数据,为国家和中小企业提供价值。此举是国内企业最早把大数据提升到企业管理层高度的一次重大里程碑。阿里巴巴也是最早提出通过数据进行企业数据化运营的企业。
2014年5月,美国白宫发布了2014年全球“大数据”白皮书的研究报告《大数据:抓住机遇、守护价值》。报告鼓励使用数据以推动社会进步,特别是在市场与现有的机构并未以其他方式来支持这种进步的领域;同时,也需要相应的框架、结构与研究,来帮助保护美国人对于保护个人隐私、确保公平或是防止歧视的坚定信仰。
-
大数据相关技术的发展
大数据技术是一种新一代技术和构架,它以成本较低、以快速的采集、处理和分析技术,从各种超大规模的数据中提取价值。大数据技术的发展可以分为六大方向:
(1)在大数据采集与预处理方向。这方向最常见的问题是数据的多源和多样性,导致数据的质量存在差异,严重影响到数据的可用性。针对这些问题,目前很多公司已经推出了多种数据清洗和质量控制工具(如IBM的Data Stage)。
(2)在大数据存储与管理方向。这方向最常见的挑战是存储规模大,存储管理复杂,需要兼顾结构化、非结构化和半结构化的数据。分布式文件系统和分布式数据库相关技术的发展正在有效的解决这些方面的问题。在大数据存储和管理方向,尤其值得我们关注的是大数据索引和查询技术、实时及流式大数据存储与处理的发展。
(3)大数据计算模式方向。由于大数据处理多样性的需求,目前出现了多种典型的计算模式,包括大数据查询分析计算(如Hive)、批处理计算(如Hadoop MapReduce)、流式计算(如Storm)、迭代计算(如HaLoop)、图计算(如Pregel)和内存计算(如Hana),而这些计算模式的混合计算模式将成为满足多样性大数据处理和应用需求的有效手段。
(4)大数据分析与挖掘方向。在数据量迅速膨胀的同时,还要进行深度的数据深度分析和挖掘,并且对自动化分析要求越来越高,越来越多的大数据数据分析工具和产品应运而生,如用于大数据挖掘的R Hadoop版、基于MapReduce开发的数据挖掘算法等等。
(5)大数据可视化分析方向。通过可视化方式来帮助人们探索和解释复杂的数据,有利于决策者挖掘数据的商业价值,进而有助于大数据的发展。很多公司也在开展相应的研究,试图把可视化引入其不同的数据分析和展示的产品中,各种可能相关的商品也将会不断出现。可视化工具Tabealu 的成功上市反映了大数据可视化的需求。
(6)大数据安全方向。当我们在用大数据分析和数据挖掘获取商业价值的时候,黑客很可能在向我们攻击,收集有用的信息。因此,大数据的安全一直是企业和学术界非常关注的研究方向。通过文件访问控制来限制呈现对数据的操作、基础设备加密、匿名化保护技术和加密保护等技术正在最大程度的保护数据安全。
-
大数据运用场景及分析案例
-
-
场景应用
-
(1)Uber
派单系统(自动匹配算法)、峰时定价系统
(2) Netflix的纸牌屋
作为世界上最大的在线影片租恁服务商,Netflix几乎比所有人都清楚大家喜欢看什么。它已经知道用户很喜欢Fincher(社交网络、七宗罪的导演),也知道Spacey主演的片子表现都不错,还知道英剧版的《纸牌屋》很受欢迎,Netflix花1亿美元买下版权,请来David Fincher和老戏骨Kevin Spacey,首次进军原创剧集就一炮而红,在美国及40多个国家成为最热门的在线剧集。
(3)股票投资预测
华尔街“德温特资本市场”公司首席执行官保罗·霍廷每天的工作之一,就是利用电脑程序分析全球3.4亿微博账户的留言,进而判断民众情绪,再以“1”到“50”进行打分。根据打分结果,霍廷再决定如何处理手中数以百万美元计的股票。霍廷的判断原则很简单:如果所有人似乎都高兴,那就买入;如果大家的焦虑情绪上升,那就抛售。这一招收效显著——当年第一季度,霍廷的公司获得了7%的收益率。 最让人吃惊的例子是,社交媒体监测平台DataSift监测了Facebook(脸谱) IPO当天Twitter上的情感倾向与Facebook股价波动的关联。在Facebook开盘前Twitter上的情感逐渐转向负面,25分钟之后Facebook的股价便开始下跌。而当Twitter上的情感转向正面时,Facebook股价在8分钟之后也开始了回弹。最终当股市接近收盘、Twitter上的情感转向负面时,10分钟后Facebook。
(4)大数据服务于服饰改进
有一个有趣的故事是关于奢侈品营销的。PRADA在纽约的旗舰店中每件衣服上都有RFID码。每当一个顾客拿起一件PRADA进试衣间,RFID会被自动识别。同时,数据会传至PRADA总部。每一件衣服在哪个城市哪个旗舰店什么时间被拿进试衣间停留多长时间,数据都被存储起来加以分析。如果有一件衣服销量很低,以往的作法是直接干掉。但如果RFID传回的数据显示这件衣服虽然销量低,但进试衣间的次数多。那就能另外说明一些问题。也许这件衣服的下场就会截然不同,也许在某个细节的微小改变就会重新创造出一件非常流行的产品。
-
-
应用分析
-
- 货架上永远有最受欢迎的时装?
- 众口难调,大数据如何预测客户需求,使得高层决策更精确?
- 产品生命周期(原料,产品外观等)过程如何与客户需求同步?
-
-
传统营销的问题:
-
- 新款原料供给不足或者是原料囤积严重
- 尺码,颜色,款式可能不符合大众口味
- 商品如果热卖,补货可能跟不上
-
- 大数据业务分析
- 原料:提前订购稀缺布料
- 制造:动态调整尺码,颜色,款式的产量
- 物流:合理的选择物流组合
- 库存:不积压,不断货
- 销售:实时补货
-
海量数据是大数据分析基石
1.强化税收管理
数据来源:企业在工商、税务部门的登记、申报、缴款等数据;增值税全部销售收入数据、所得税营业收入数据;企业经营数据、发票数据、商务活动数据等。
2.治理交通拥堵
数据来源:实时交通报告,包括大量的交通摄像头数据、信号灯数据、天气数据等
3.预测犯罪
数据来源:警方归档数据、相关图像记录以及案件卷宗等信息:指纹、掌纹、人脸图像、签名等生物信息识别数据
4.监控社交网络
数据来源:微信、微博、qq、论坛、贴吧或者是其它的社交平台
5.交通大数据
数据来源:市政网实时采集的交通信号灯、二氧化碳传感器数据、汽车位置数据
6.用户画像
用户信息、购物信息、医疗信息、家庭信息、学历信息、工作经历…
-
数据挖掘
社交网络的数据挖掘
1.言论偏好度和可信度
2.虚拟和现实反差与性格关联度
3.网购与诚信度的关联性
4.职业观念和网络言论关联度(潜质!)
5……
基础数据:
姓名xxx,年龄19,出生在xxx,父亲姓名xxx,母亲姓名xxx,父亲曾经有过重大的手术史,母亲身体健康,曾读学校xxx,先读xxx大学,任职xxx,喜欢英语,经常刷facebook…
这份数据信息是非常有价值的,首先进行数据分析:
1、父亲有重大手术史,那么对于其父亲身体必定不那么健康,肯定需要各种补品,此外,做过手术的人应该不能干重活,那么家庭的顶梁柱就相当于失去一半了,而此人还读大学,所以基本可以推出此人家庭不是非常殷实,
但孝顺是人的天性;
2、此人大学很喜欢英语,经常逛facebook,可以推出此人非常有可能从事那种和外国人打交道的职业,比如去外企,但是对于一个有想法的人,想提高自己的人,对于一定的证书、培训是不会拒绝的。
所以基于上面2点的分析,可以给这个人精准的投放的广告如下:
1、 医院的定期体检优惠券(对于医院可以推广此类广告)
2、 各种有利于身体健康的补品(如果有医院的手术内容就更能精准的投放相应的补品广告了)
3、 各种外语考试,比如雅思、托福之类的(多送点福利,价格优惠之类的)
4、 各种商务英语培训(如果此人打算从事海外商务贸易,那么应该会买单,但要注意天时地利人和的推广此广告,因为此人的消费能力有限)
5、 推送各种vpn专线流量(能够爬墙到国外去逛facebook,对低延迟更快捷的vpn专线的需求绝对不会很冷漠)
6、 …
或者如下信息挖掘:
A. 父亲有重大手术史,假设是因为意外创伤造成,是否对劳动能力造成影响,是否有恶化可能,要吸取经验提高风险意识,及早为家庭财务作安排;
B. 父亲有重大手术史,是否遗传因素所致,女儿虽然性别不一样,但是仍存在健康风险,所以要为自己准备健康保险,及为家庭财务作安排。——意外险/健康险+储蓄型理财产品
C.19岁,先读XX大学,任职XX——年龄上看,学历不高,大专毕业或者尚未毕业实习当中,此后有进一步提升学历的需求,可以推送各种业余学习机构的广告。
D.喜欢英语,经常刷facebook,性格外向,喜欢新事物,可以推送国外品牌的广告,比如Linkedle,各类直邮网站,亚马逊的图书广告,甚至是谢丽尔的书《向前一步》等……至于VPN,好像是程序员更需要……总之,她年轻,
有风险,要早做保险及理财方面的准备;学历不高,要提升,要寻找各种发展的机会,职场或者小兼职,代购等赚点钱。
数据挖掘必须依靠于很多历史数据信息,而且逻辑推理还得依赖于实际情况推导,比如对于一个深度为H的井,一只熊掉落井底,耗时t秒,请推测它的种类?那么在推导这个问题的时候其实也得依赖于实际情况进行推导。
-
金融街的天之骄子
摩羯智投,打造“人+机器”智能化投资模式,2016年12月24日,招商银行摩羯智投发布会在杭州举行,活动宣布招商银行最新的“摩羯智投”智能化投资组合上线,开启智能化、机器化投资趋势。招商银行APP5.0上搭载的“摩羯智投”,虽然大量运用了人工智能技术中的机器学习算法,但并非完全依赖机器,而是人与机器的智能融合方式,此乃智能投顾领域的革命性创举。

-
相关性分析图解
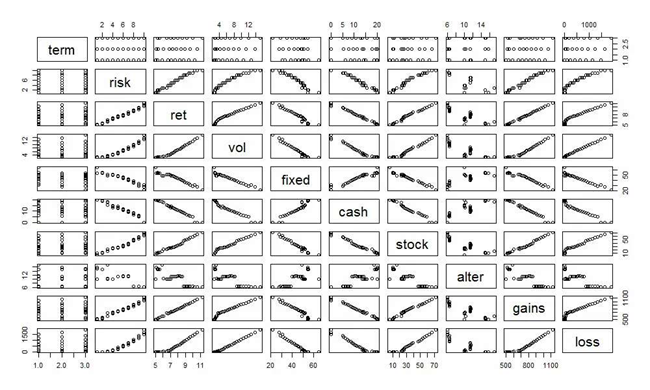
把数据变成可视化来显示,对于我们理解数据是非常有帮助的。
term列,和其它列的散点图,完全呈现离散的分布,说明term列和其它列并没有相关性的关系
risk列,除了和alter列没有线性关系,和其它列呈现明显的线性关系。
上文字段说明:
term字段:大致投资期限,risk字段:风险承受能力,alter字段:另类和其它
把上面的相关性图,再追加上相关系数、拟合曲线、分布图,重新绘制图形如下:
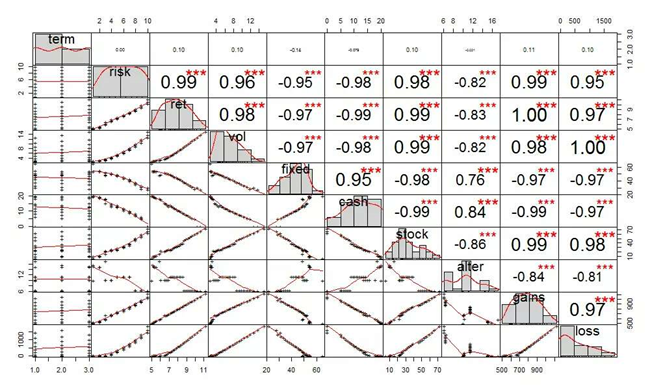
risk列,与固定收益(fixed)和现金及货币(cash),极度负相关;与股票类(stock),极度正相关;另类及其他(alter),负相关。这种情况,与资产的风险收益属性是匹配。
vol列,与亏损(loss),是100%线性相关。
ret列,与拟历史收益(gains),是100%线性相关,这里可以获得公司:gains = 10000 * ret 。
上面展现了金融界如何利用大数据进行风险预测评估。
大数据就业前景
Boos直聘网查看。
主流大数据工具介绍
-
Hadoop
根据googel公开的MapReduce和GFS论文山寨出来的一个开源版本,适合做离线业务分析,对于小批量数据增量业务处理不适合。
-
CDH(Cloudera Hadoop)
CDH是Cloudera的100%开源平台发行版,包括Apache Hadoop,专门用于满足企业需求。 CDH提供企业使用所需的一切,开箱即用。 通过将Hadoop与十多个其他关键的开源项目集成,Cloudera创建了一个功能高级的系统,可帮助您执行端到端的大数据工作流程
-
Percolator Google
国内资料比较少, Percolator的目标是在海量规模的数据集上提供增量更新的能力,并通过支持分布式的事务来确保增量处理过程的数据一致性和整体系统的可扩展性。这个目标的需求来源于对谷歌的网页索引系统的改进,此前谷歌的网页索引系统采用的是基于MapReduce的全量批处理流程,所有的网页内容更新,都需要将新增数据和历史全量数据一起通过MapReduce进行批处理,带来的问题就是网页索引的更新频率不够快(从爬虫发现网页更新到完成索引进入检索系统,需要2-3天或者更长的周期)
经典论文:《Large-scale Incremental Processing Using Distributed Transactions and Notifications》
中文翻译:http://www.importnew.com/2896.html
-
Google Dremel
国内资料较少,它是一种列状存储全量检索系统。
经典论文《Dremel: Interactive Analysis of Web-Scale Datasets》【Dremel:Web规模数据集的互动分析】
-
Apache Pig
Apache Pig是一个用于分析大型数据集的平台,其中包括用于表达数据分析程序的高级语言,以及用于评估这些程序的基础结构.Pig程序的显着特性是它们的结构适合于大量的并行化,这反过来使得它们能够处理非常大的数据集。编写 Map 和 Reduce 应用程序并不十分复杂,但这些编程确实需要一些软件开发经验。Apache Pig 改变了这种状况,它在 MapReduce 的基础上创建了更简单的过程语言抽象,为 Hadoop 应用程序提供了一种更加接近结构化查询语言 (SQL) 的接口。因此,您不需要编写一个单独的 MapReduce 应用程序,您可以用 Pig Latin 语言写一个脚本,在集群中自动并行处理与分发该脚本。
-
Apache Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
-
Apache Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
-
Elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
-
Logstash
Logst Logstash是一个开源的服务器端数据处理管道,它从多个源同时获取数据,对其进行转换,然后将其发送到您最喜欢的"存储"(这里指的自然是Elasticsearch)
-
Apache Storm
Apache Storm是一个自由和开源的分布式实时计算系统。
-
Alibaba JStorm
阿里巴巴JStorm是一个强大的企业级流式计算引擎,是Apache Storm 的4倍性能, 可以自由切换行模式或mini-batch 模式,JStorm 提供企业级Exactly-Once 编程框架,JStorm 不仅提供一个流式计算引擎, 还提供实时计算的完整解决方案, 涉及到更多的组件, 如jstorm-on-yarn, jstorm-on-docker, SQL Engine, Exactly-Once Framework 等等。JStorm 是Apache Storm的超集, 包含所有Apache Storm的API, 应用可以轻松从Apache Storm迁移到JStorm上。 并且如果是基于Apache Storm 0.9.5 的应用可以无需修改无缝迁移到JStorm 2.1.1 版本上。
-
Apache Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
-
Amazon Kinesis
Amazon Kinesis 是一种在 AWS 上流式处理数据的平台,提供了多种强大的服务,让您可以轻松地加载和分析流数据,同时还可让您根据具体需求来构建自定义流数据应用程序。Web 应用程序、移动设备、可穿戴设备、行业传感器和许多软件应用程序和服务都可能生成大量的流数据(有时达到每小时数 TB),需要对其进行连续地收集、存储和处理。Amazon Kinesis 服务让您能以较低的费用实现该目的。和kafaka很相似。
-
Azure EventHub
几乎每秒实时地记录数百万个事件,使用灵活的授权与节流来连接装置,以时间为基础处理事件缓冲
利用弹性化的规模来管理服务,使用原生客户端链接库连接广泛的平台,其他云端服务即插即用的配接器。
-
Logging Hub
实时的记录和可视化,整合您的分布式平台中的日志记录数据,使用Logging Hub实时查看并可视化数据。
-
Redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
l Redis 有三个主要使其有别于其它很多竞争对手的特点:
Redis是完全在内存中保存数据的数据库,使用磁盘只是为了持久性目的;
Redis相比许多键值数据存储系统有相对丰富的数据类型;
Redis可以将数据复制到任意数量的从服务器中;
l Redis优点
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
-
Apache Spark
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
-
Apache Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
-
Apache HBase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
大数据业务流程
-
数据采集
-
数据可视化
-
数据可视化工具介绍
大数据可视化,就是指将结构或非结构数据转换成适当的可视化图表,然后将隐藏在数据中的信息直接展现于人们面前。如下图所示:

-
D3

-
Gephi

-
Google Chart
-
Echarts
-
Fusion Charts Suit XT

Hadoop是什么
-
需求
有海量数据需要存储,要求数据不能丢失,计算有时效性,有速度要求,支持平滑水平扩展。
-
-
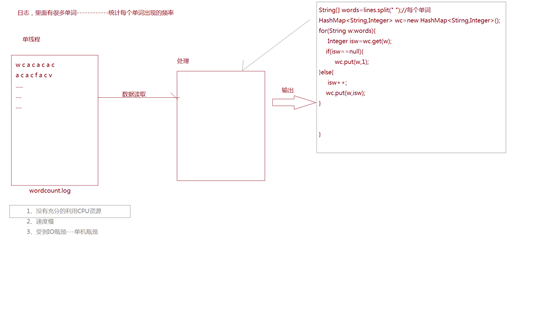
单机版架构
-
-
-
多线程版架构
-

-
-
分布式架构
-
集群架构
-

以上原图放在这里!(用电脑自带的画图工具打开更清晰)
-
Hadoop功能
Apache Hadoop 是用于开发在分布式计算环境中执行的数据处理应用程序的框架。类似于在个人计算机系统的本地文件系统的数据,在 Hadoop 数据保存在被称为作为Hadoop分布式文件系统的分布式文件系统。处理模型是基于“数据局部性”的概念,其中的计算逻辑被发送到包含数据的集群节点(服务器)。这个计算逻辑不过是写在编译的高级语言程序,例如 Java. 这样的程序来处理Hadoop 存储 的 HDFS 数据。
Hadoop是一个开源软件框架。使用Hadoop构建的应用程序都分布在集群计算机商业大型数据集上运行。商业电脑便宜并广泛使用。这些主要是在低成本计算上实现更大的计算能力非常有用。你造吗? 计算机集群由一组多个处理单元(存储磁盘+处理器),其被连接到彼此,并作为一个单一的系统。
-
Hadoop核心组件
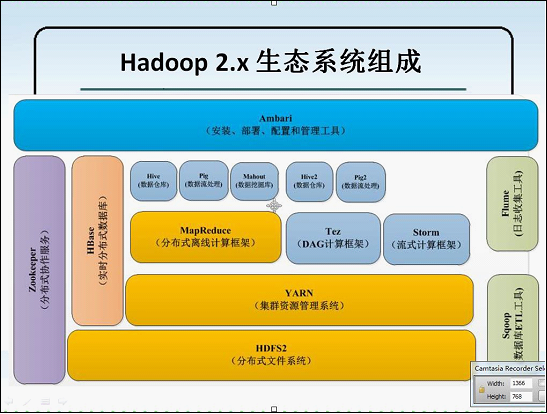
Hadoop=HDFS+Yarn+MapReduce+Hbase+Hive+Pig+…
1.HDFS:分布式文件系统,隐藏集群细节,可以看做一块儿超大硬盘
主:namenode,secondarynamenode
从:datanode
2.Yarn:分布式资源管理系统,用于同一管理集群中的资源(内存等)
主:ResourceManager
从:NodeManager
3.MapReduce:Hadoop的编程框架,用map和reduce方式实现分布式程序设计,类似于Spring。
4.Pig:基于hadoop的一门数据处理语言,类似于python等编程语言
5.Zookeeper:分布式协调服务,用于维护集群配置的一致性、任务提交的事物性、集群中服务的地址管理、集群管理等
主:QuorumPeerMain
从:QuorumPeerMain
6.Hbase:Hadoop下的分布式数据库,类似于NoSQL
主:HRegionserver,HMaster,HPeerMain(在使用zookeeper作为协调时没有此进程)
7.Hive:分布式数据仓库,让开发人员可以像使用SQL一样使用MR。
-
Hadoop生态圈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号