【深究系列】手撕HashMap
【深究系列】手撕HashMap
一、HashMap数据结构
1、取模的数组
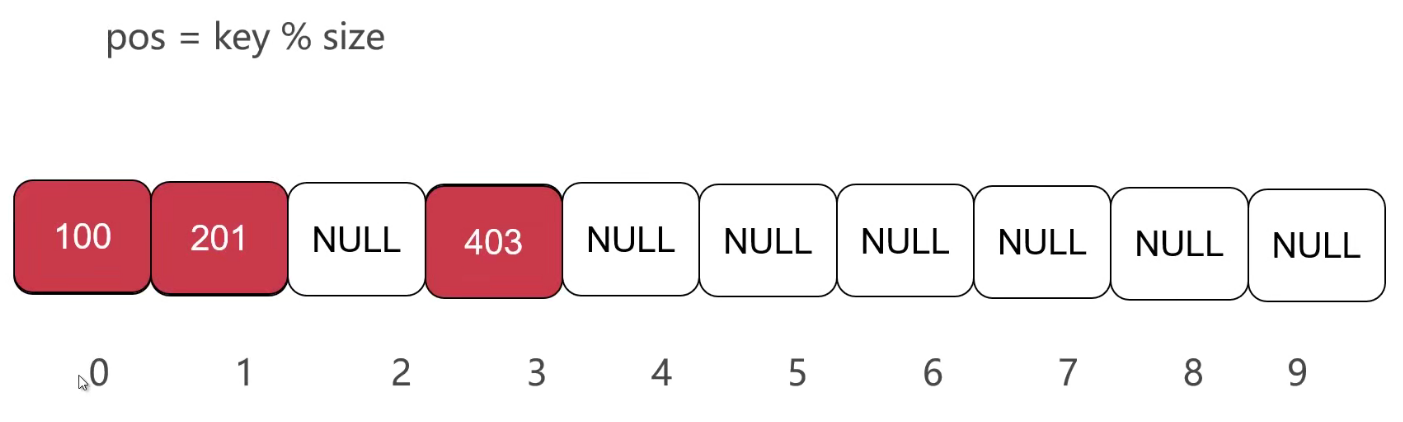
- 存储一个数,100,100模10为0,那么就存放在下标为0的位置。403%10为3,放在下标为3的位置。
- 那么如果200也进来,300也要进来,该往哪里放呢?(此时便发生了冲突)
2、冲突问题
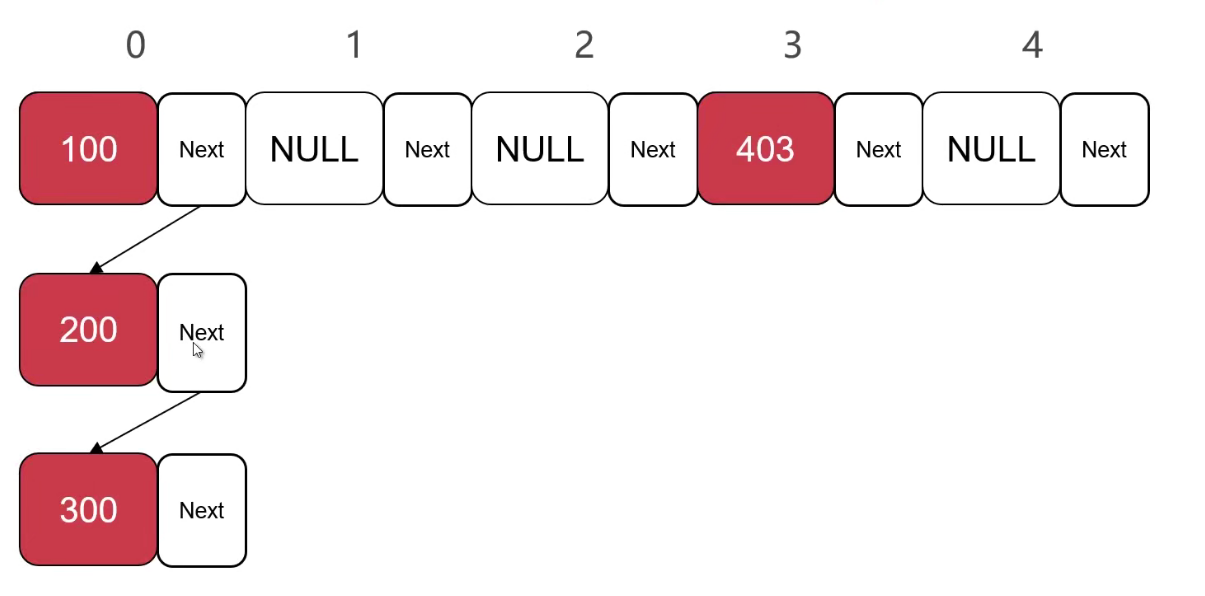
-
通过Next指针逐渐往下添加,可以快速的找到。
-
那么现在又遇到了新的问题,如果100,200,300,400,.....,许多对模长度的值都是0的数据都存放在下标为0的位置,那么此时,0这个位置的链表就又变成了一个单链表,单链表就存在查找复杂,但是插入修改方便的特性。
-
那么为了解决称为单链表查询效率很低的问题,JDK1.8对HashMap做了改进,当链表数据超过一个阈值8的时候,会转变为红黑树,以提高查询的效率。
3、总结说明
- HashMap的数据结构包括了初始数组、链表、红黑树;
- 插入数据的时候使用pos = key % size来进行插入数据。
- 当两个或者两个以上的key的key相同且key值不同的时候(发生冲突),就会挂在数组初始化位置的链表之后。
- 当某个结点后出现过多的链表结点的时候,就会转换成红黑树以提高效率。
二、HashMap源码分析
内部数据结构
Node类
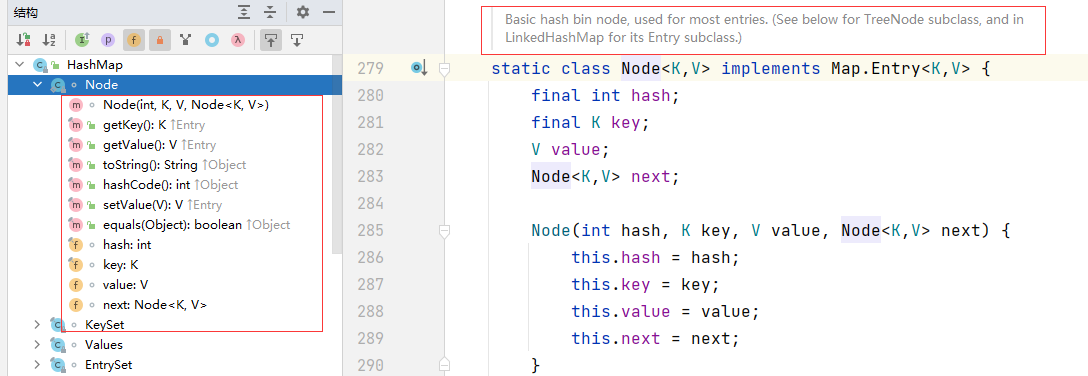
英文翻译:基本的哈希bin节点,用于大多数条目。(参见下面的TreeNode子类,以及LinkedHashMap的Entry子类。)
TreeNode类
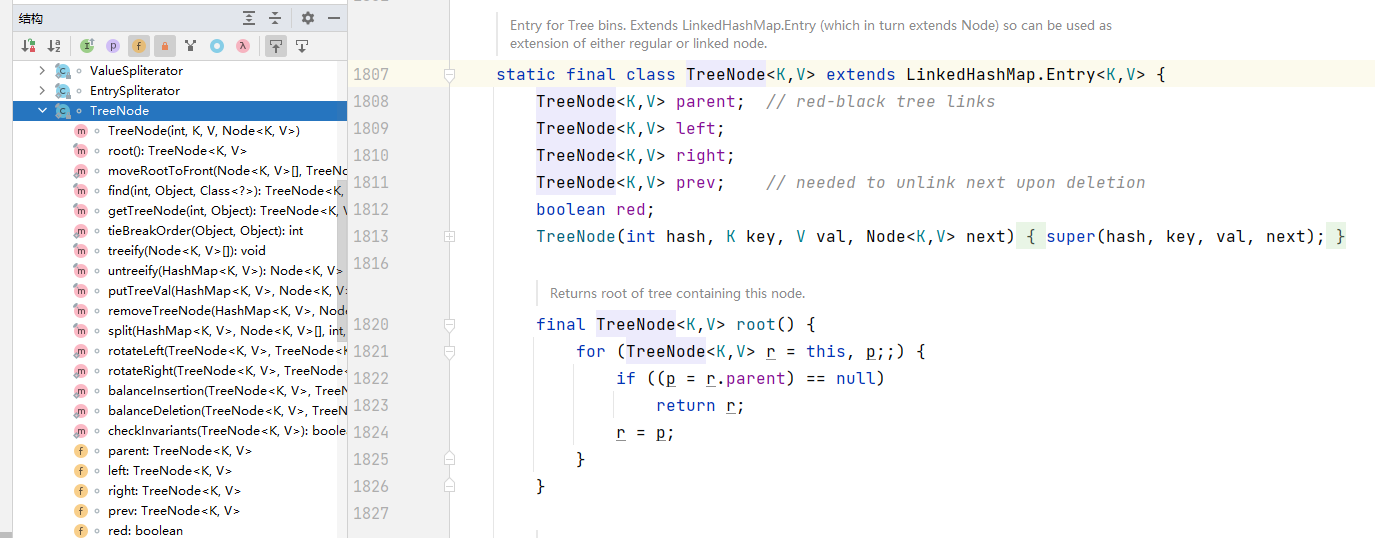
属性分析
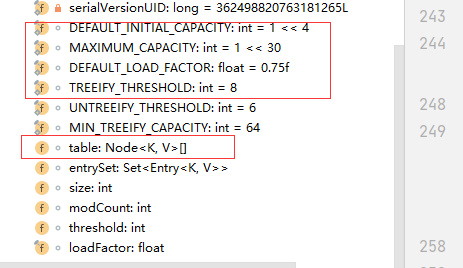
table:

表在第一次使用时初始化,并根据需要调整大小。当分配时,长度总是2的幂。(我们还允许一些操作的长度为0,以允许当前不需要的引导机制。
我们可以看到,table是一个数组,这个transient是个什么玩意。
transient详解:其实就是不需要序列化的属性用这个关键词修饰。
1、hash()方法分析

首先计算出这个key的散列值,返回一个32位的int赋给h,然后让hashCode的高16位和低16位进行异或操作。
为什么要这么设计?
-
降低hash碰撞是基础,位运算的效率更高。
-
右移16位,低位掩码:就是利用高位码去替换低位码。
-
这也叫扰动函数:
- 为了降低hash码的冲突,加大随机性,混合后的低位掺杂了一些高位信息。
-
JDK7进行了四次,而JDK8进行了一次,提高了效率。

另外一个原因就是在这个地方与hashmap中的数组槽位异或计算

高区的16位很有可能会被数组槽位数的二进制码锁屏蔽,如果我们不做刚才移位异或运算,那么在计算槽位时将丢失高区特征
参考
https://blog.csdn.net/a314774167/article/details/100110216
2、put()方法分析
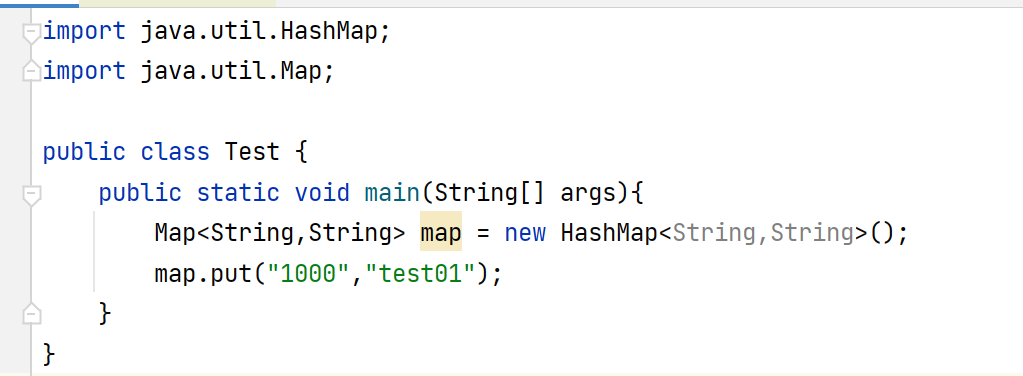
这是个测试用例
①进入HashMap()的构造函数

-
可以看到只有一行代码,loadFactor可以看做是一个负载因子,然后把默认的负载因子赋值。
-

-
可以看到默认的这个负载因子是0.75f;
②进入put()方法

- put方法调用了putVal方法。
可以看出,在构造函数的时候,是并没有初始化map的。
3、putVal()方法分析1

首先这个方法进去之后,先声明了一个Node<K,V>[]类型的数组tab,一个空的结点;
然后做了一个判断,先将table赋给tab,然后判断是不是为空。现在刚声明,肯定为空。下面就会进入resize函数
4、resize()方法分析
接着分析putVal()方法会发现进入了resize函数。
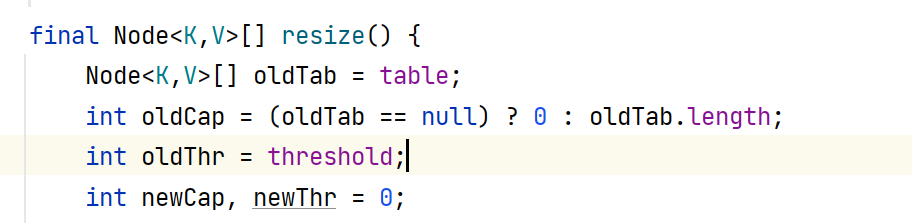
首先还是先把这个table,赋给了一个新的Node[]数组。然后oldCap意思就是原来table这个容量是多少吧,还有一个threshold,threshold意思就是阈值,门槛的意思(多少开始转化为红黑树)。
可以看到这里是记录下来了原来这个table的容量,和原来的阈值。然后声明了新的容量和阈值。
接着往下分析resize()函数,是三个判断。
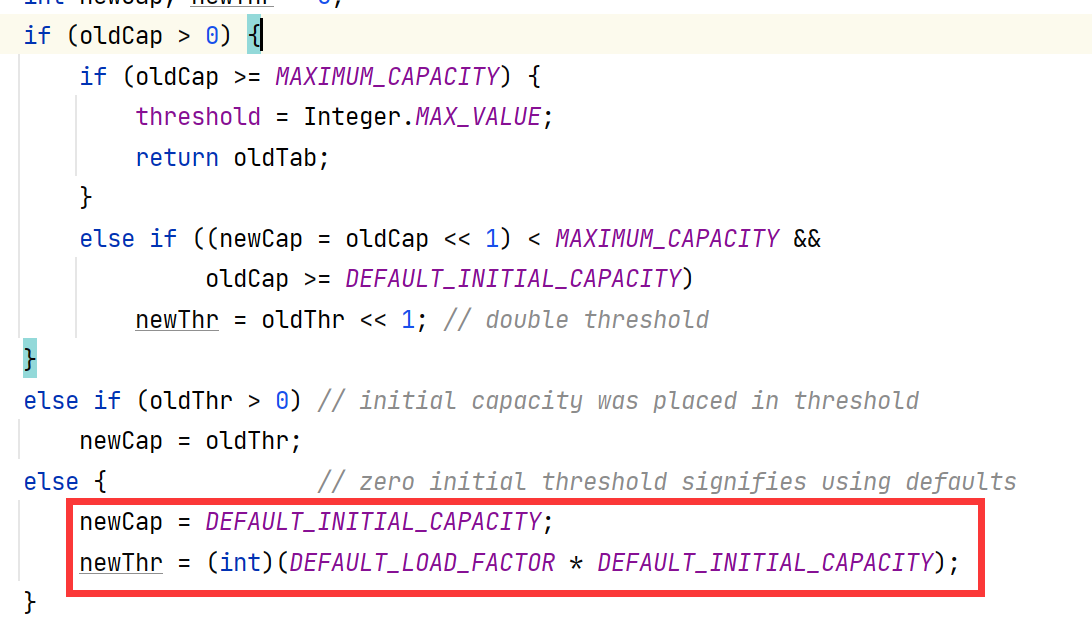
很显然,我们声明的是空的HashMap,oldCap和oldThr都是0,最终进入到了这个else,那么这个else干了什么呢,两个赋值的操作。赋予了新的空间的新的阈值,那我们看一下这个默认空间和默认阈值是什么呢?

newThr = 16 * 0.75f(前面我们看了DEFAULT_INITIAL_CAPACITY的值是0.75) = 12;新的阈值是12
问:那么此时就有一个问题,在扩容的时候,为什么都是2的倍数呢?
答:一个是因为计算机2进制,这样申请内存可以避免内存碎片。进行移位操作比加减乘除操作效率高。还有一个原因就是会提高hash散列的复杂度。
接着往下分析resize()函数

截止目前来看,这个我们声明的HashMap,在这里就是这个table,是一个HashMap()对象中的一个属性,一个成员变量,table是Node<K,V>[]类型的,table指向这个数组的引用,现在重新赋值,给table一个新的空间。
接着往下分析resize()函数
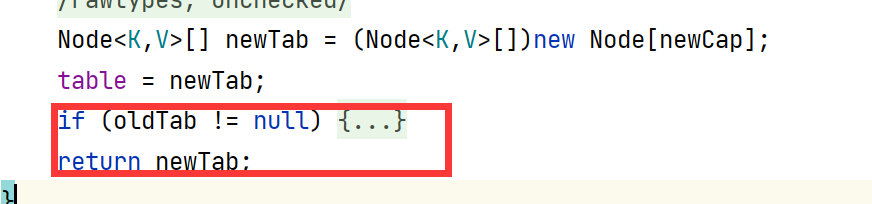
这个if里面的具体细节现在不做具体分析,只是分析我们实例代码中运行到这里的逻辑,因为oldTab是为空的,所以直接返回新的Tab。
5、putval()方法分析2
从上面的resize()函数返回之后
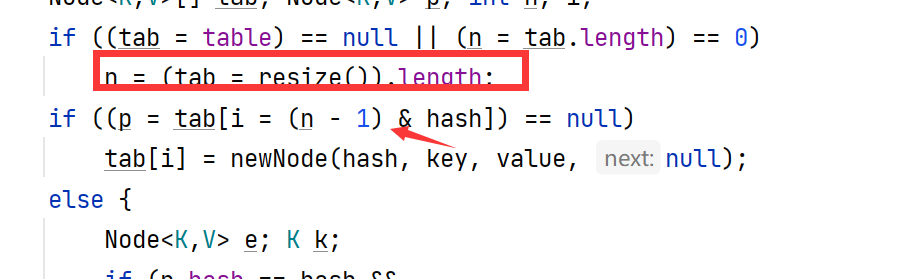
从resize()函数返回之后,把这个tab的长度赋值给了n。
然后下面马上将(n-1)与hash值做了一个与运算,这里重点分析一下

所以采用2的倍数会提高散列度。
三、HashMap小结
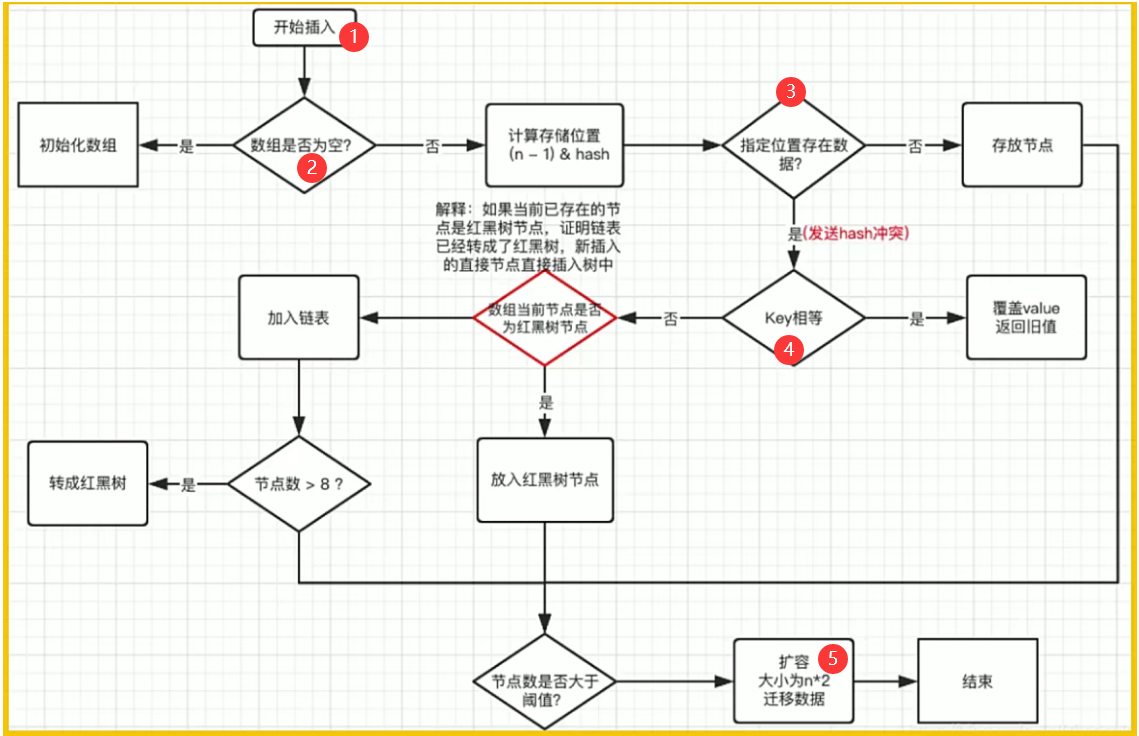
1、插入原理图示
2、怎么设定初始容量大小

返回根据负载因子的容量。

3、JDK1.8对于JDK1.7的优化
数据结构的改变

发生冲突的时候,往链表里放,1.7是将原始结点作为新节点的后继。可能会出现死循环的问题(头插法,多线程扩容)
扩容的方案

那么扩容的时候,为什么1.8不用重新hash就可以直接定位源节点在新数据的位置呢
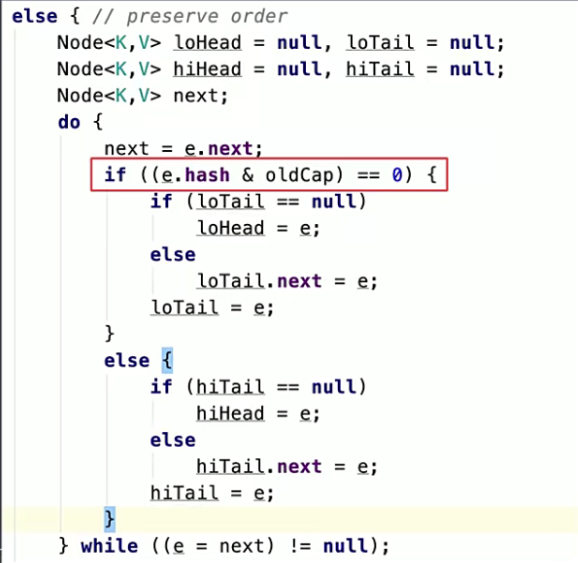
因为每次扩容是2的倍数,不用重新计算hash。
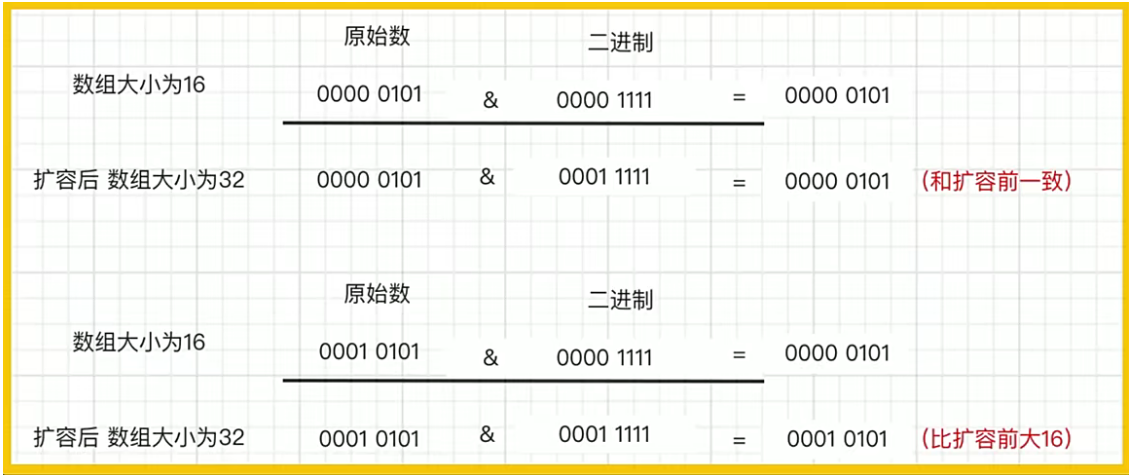
如果原始数的高位是0的时候,那么是不需要重新计算的。如果高位是1的时候,新位置就是原来的位置加上新数组的长度就可以了。这样就避免了重新计算散列值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号