记一次HBase的NotServingRegionException问题
1. 问题
在hbase测试集群上,访问一些hbase表,均报类似下面的错误:region不可用
Wed Oct 28 14:00:56 CST 2020, RpcRetryingCaller{globalStartTime=1603864856185, pause=100, maxAttempts=4}, org.apache.hadoop.hbase.NotServingRegionException: org.apache.hadoop.hbase.NotServingRegionException: tbl_ishis_hb_tips_levy_inf,,1578557543052.0ca2591b1209239ee963893abdfa4b53. is not online on vm3928.hadoop.com,16020,1603800273275
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:3325)
......
2. 排查问题
首先怀疑是HBase集群内正在进行Region的Split和不同机器之间的Region Balance,这时候Region是不可用的状态,但是Region切分和再均衡持续时间不会很久,而现在的问题昨天已经出现了,于是看下 HMaster 日志,一直在报错,关键信息如下:
2020-10-28 14:00:17,941 WARN org.apache.hadoop.hbase.coordination.SplitLogManagerCoordination: Error splitting /hbase/splitWAL/WALs%2Fvm3928.hadoop.com%2C16020%2C1598158651562-splitting%2Fvm3928.hadoop.com%252C16020%252C1598158651562.vm3928.hadoop.com%252C16020%252C1598158651562.regiongroup-0.1603692260004
2020-10-28 14:00:17,942 WARN org.apache.hadoop.hbase.master.SplitLogManager: error while splitting logs in [hdfs://nameservice1/hbase/WALs/vm3928.hadoop.com,16020,1598158651562-splitting] installed = 1 but only 0 done
2020-10-28 14:00:17,942 WARN org.apache.hadoop.hbase.master.procedure.ServerCrashProcedure: Failed state=SERVER_CRASH_SPLIT_LOGS, retry pid=1, state=RUNNABLE:SERVER_CRASH_SPLIT_LOGS, locked=true; ServerCrashProcedure server=vm3928.hadoop.com,16020,1598158651562, splitWal=true, meta=true; cycles=3455
java.io.IOException: error or interrupted while splitting logs in [hdfs://nameservice1/hbase/WALs/vm3928.hadoop.com,16020,1598158651562-splitting] Task = installed = 1 done = 0 error = 1
at org.apache.hadoop.hbase.master.SplitLogManager.splitLogDistributed(SplitLogManager.java:271)
at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:401)
at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:386)
at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:283
......
可以推断是拆分WAL日志时出错或中断导致的问题,该问题影响到了 region 恢复
https://www.w3cschool.cn/hbase_doc/
Write Ahead Log
Write Ahead Log(WAL)将HBase中数据的所有更改记录到基于文件的存储中。在正常操作下,不需要WAL,因为数据更改从MemStore移动到StoreFiles。但是,如果在刷新MemStore之前RegionServer崩溃或变得不可用,则WAL确保可以重播对数据所做的更改。如果写入WAL失败,则修改数据的整个操作将失败。WAL位于HDFS中的/hbase/WALs/目录下,每个区域有子目录。
WAL拆分
RegionServer服务于许多region。分区服务器中的所有region共享相同活动的WAL文件。WAL文件中的每个编辑都包含有关它属于哪个region的信息。当打开region时,需要重播属于该region的WAL文件中的编辑。因此,WAL文件中的编辑必须按region分组,以便可以重播特定的集合以重新生成特定region中的数据。按region对WAL编辑进行分组的过程称为日志拆分。如果region服务器出现故障,它是恢复数据的关键过程。
在群集启动时由HMaster完成日志拆分,或者在region服务器关闭时由ServerShutdownHandler完成日志拆分。为保证一致性,受影响的区域在数据恢复之前不可用。所有WAL编辑都需要在给定region再次可用之前恢复并重播。因此,受到日志拆分影响的region在该过程完成之前不可用。
过程:日志分割,分步执行
新目录按以下模式命名:
/hbase/WALs/, , 目录被重新命名。重命名该目录非常重要,因为即使HMaster认为它已关闭,RegionServer仍可能启动并接受请求。如果RegionServer没有立即响应,也没有检测到它的ZooKeeper会话,HMaster可能会将其解释为RegionServer失败。重命名日志目录可确保现有的有效WAL文件仍然由活动但繁忙的RegionServer使用,而不会意外写入。新目录根据以下模式命名:
/hbase/WALs/, , -splitting
这种重命名的目录的例子可能如下所示:
/hbase/WALs/srv.example.com,60020,1254173957298-splitting
每个日志文件都被拆分,每次一个。日志拆分器一次读取一个编辑项的日志文件,并将每个编辑条目放入对应于编辑区域的缓冲区中。同时,拆分器启动多个编写器线程。编写器线程选取相应的缓冲区,并将缓冲区中的编辑项写入临时恢复的编辑文件。临时编辑文件使用以下命名模式存储到磁盘:
/hbase/<table_name>/<region_id>/recovered.edits/.temp
该文件用于存储此区域的WAL日志中的所有编辑。日志拆分完成后,.temp文件将被重命名为写入文件的第一个日志的序列ID。要确定是否所有编辑都已写入,将序列ID与写入HFile的上次编辑的序列进行比较。如果最后编辑的序列大于或等于文件名中包含的序列ID,则很明显,编辑文件中的所有写入操作都已完成。
日志拆分完成后,每个受影响的区域将分配给RegionServer。打开该区域时,会检查recoverededed文件夹以找到恢复的编辑文件。如果存在任何这样的文件,则通过读取编辑并将其保存到MemStore来重播它们。在重放所有编辑文件后,MemStore的内容被写入磁盘(HFile),编辑文件被删除。
继续查看hdfs上的WAL目录,可以发现存在splitting目录,WAL切分正常结束的话不会出现该目录
hadoop fs -ls /hbase/WALs
Found 4 items
drwxr-xr-x - hbase hbase 0 2020-10-26 18:40 /hbase/WALs/vm3928.hadoop.com,16020,1598158651562-splitting
drwxr-xr-x - hbase hbase 0 2020-10-28 15:50 /hbase/WALs/vm3928.hadoop.com,16020,1603800273275
drwxr-xr-x - hbase hbase 0 2020-10-28 15:49 /hbase/WALs/vm3929.hadoop.com,16020,1603800273410
drwxr-xr-x - hbase hbase 0 2020-10-28 15:49 /hbase/WALs/vm3930.hadoop.com,16020,1603800273039
考虑到HMaster一直在报WAL切分失败的log,大致推测由于集群一直在做WAL切分任务,无法完成,受影响的那台RegionSerer上region都不可用,因此无法正常查询hbase数据。
3. 初步解决
参考网上的一些解决方法是优先恢复服务,将splitting目录move 其他地方,于是执行以下操作
hadoop fs -mv /hbase/WALs/vm3928.hadoop.com,16020,1598158651562-splitting /hbase/bk
这时在cdh管理界面上查看28这台服务器上region数量,可用的region由1个恢复到了244个
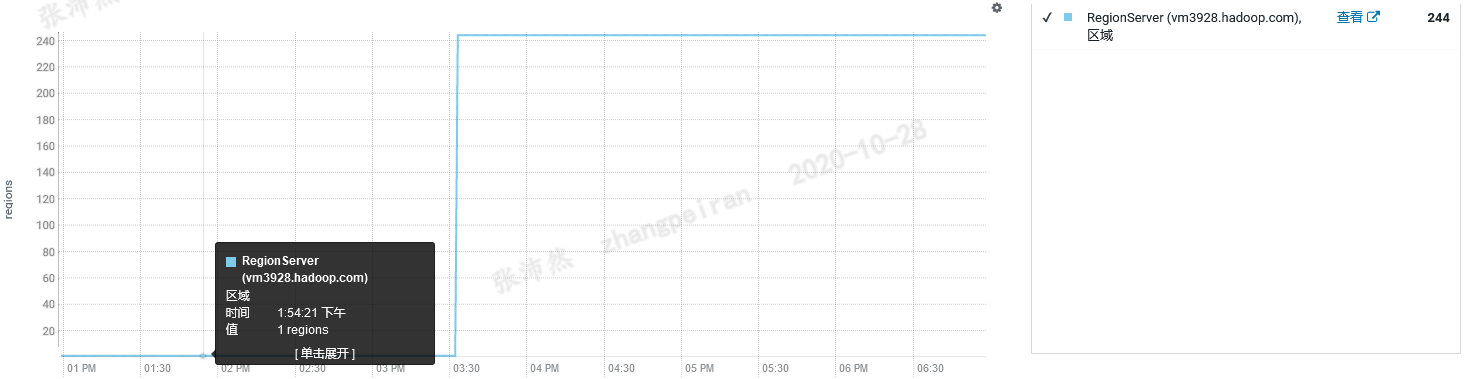
这时查询了一些hbase表的前几条数据,已经可以访问数据了(其实还有些问题,看后文)
4. 分析WAL切分失败原因
继续分析WAL切分失败的原因,查看splitting目录下面文件的部分内容
hadoop fs -cat /hbase/WALs/vm3928.hadoop.com,16020,1598158651562-splitting/vm3928.hadoop.com%2C16020%2C1598158651562.vm3928.hadoop.com%2C16020%2C1598158651562.regiongroup-0.1603692260004
20/10/28 11:00:10 WARN hdfs.DFSClient: Found Checksum error for BP-1135703146-10.200.39.28-1574043673848:blk_1084998682_11258280 from DatanodeInfoWithStorage[10.200.39.30:1004,DS-cfda5a02-d48f-4269-896e-083d55fdd33f,DISK] at 512
20/10/28 11:00:10 WARN hdfs.DFSClient: No live nodes contain block BP-1135703146-10.200.39.28-1574043673848:blk_1084998682_11258280 after checking nodes = [DatanodeInfoWithStorage[10.200.39.30:1004,DS-cfda5a02-d48f-4269-896e-083d55fdd33f,DISK], DatanodeInfoWithStorage[10.200.39.29:1004,DS-dffdf8e8-0f2a-4a43-b39d-b70b50263e0c,DISK], DatanodeInfoWithStorage[10.200.39.28:1004,DS-21d3927c-e42d-45ce-8e79-25c14202cbe5,DISK]], ignoredNodes = null
......
可以发现存在hbase数据block丢失的情况,而hbase的数据存储在hdfs上面的,hdfs有三副本策略,3份全丢状态就为 corrupt,日志中可以发现集群的三个节点上均找不到某个block,接下来对hbase数据目录做下检查,结果如下:
hdfs fsck /hbase/data
Connecting to namenode via http://vm3928.hadoop.com:9870/fsck?ugi=hbase&path=%2Fhbase%2Fdata
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7: CORRUPT blockpool BP-1135703146-10.200.39.28-1574043673848 block blk_1084998838
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7: CORRUPT 1 blocks of total size 2559961 B.
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/756ffcf3efd24971abe0195f8de5af1e: Under replicated BP-1135703146-10.200.39.28-1574043673848:blk_1084998837_11258152. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas_idx_mchnt_cd/72c126f1fa9cef3a0fdd8fcb5e49501e/d/a64f19e4dbfc47a991d919a5595b4e29: Under replicated BP-1135703146-10.200.39.28-1574043673848:blk_1084998835_11258150. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
Status: CORRUPT
Number of data-nodes: 3
Number of racks: 1
Total dirs: 3016
Total symlinks: 0
Replicated Blocks:
Total size: 114299895515 B
Total files: 2386
Total blocks (validated): 2406 (avg. block size 47506190 B)
********************************
UNDER MIN REPL'D BLOCKS: 1 (0.04156276 %)
dfs.namenode.replication.min: 1
CORRUPT FILES: 1
CORRUPT BLOCKS: 1
CORRUPT SIZE: 2559961 B
********************************
Minimally replicated blocks: 2405 (99.958435 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 2 (0.08312552 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.9970906
Missing blocks: 0
Corrupt blocks: 1
Missing replicas: 4 (0.055417012 %)
Blocks queued for replication: 0
The filesystem under path '/hbase/data' is CORRUPT
挑出其中的关键信息如下:
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7: CORRUPT 1 blocks of total size 2559961 B.
可以发现表名为tbl_glhis_hb_ct_settle_dtl_bas,region名为42a907b4ffafb72205d9e1d1fa5e8301,列族d的一份数据文件36cafb11c3a6455aaba1605b72bbb7c7存在缺失的block,可以猜测如果访问到了tbl_glhis_hb_ct_settle_dtl_bas表的42a907b4ffafb72205d9e1d1fa5e8301分区时,应该还会报错,果然,在hbase shell中直接count操作,一直数到了13224000行,需要访问42a907b4ffafb72205d9e1d1fa5e8301,开始报了NotServingRegionException错,如下所示,与预期一致。
Current count: 13224000, row: 4995600052377126-79799371-79799880787440-0119212559-269394-03014510-00092900-X-Q1#010
org.apache.hadoop.hbase.client.RetriesExhaustedException: Failed after attempts=8, exceptions:
Wed Oct 28 17:21:50 CST 2020, RpcRetryingCaller{globalStartTime=1603876909641, pause=100, maxAttempts=8}, org.apache.hadoop.hbase.NotServingRegionException: org.apache.hadoop.hbase.NotServingRegionException: tbl_glhis_hb_ct_settle_dtl_bas,5,1578557420156.42a907b4ffafb72205d9e1d1fa5e8301. is not online on vm3928.hadoop.com,16020,1603800273039
目前看来,可以猜测整个问题的大概原因:某张hbase表底层的hdfs数据块缺失,造成集群WAL切分任务一直失败无法完成,最终造成受影响的RegionServer上所有region都不可用(非region正在分裂或再均衡引起的不可用)。使用删除hdfs上切分目录的方法,使不存在丢失数据块的表可以正常访问,但真正丢失数据块的hbase表仍然存在部分region不可用的问题(测试环境中为什么会出现hdfs数据块丢失的情况还不确定)
5. 处理状态异常数据
查看目前的hbase数据状态
hdfs fsck /hbase/data
Connecting to namenode via http://vm3928.hadoop.com:9870/fsck?ugi=hbase&path=%2Fhbase%2Fdata
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7: CORRUPT blockpool BP-1135703146-10.200.39.28-1574043673848 block blk_1084998838
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7: CORRUPT 1 blocks of total size 2559961 B.
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/756ffcf3efd24971abe0195f8de5af1e: CORRUPT blockpool BP-1135703146-10.200.39.28-1574043673848 block blk_1084998837
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/756ffcf3efd24971abe0195f8de5af1e: CORRUPT 1 blocks of total size 40464 B.
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas_idx_mchnt_cd/72c126f1fa9cef3a0fdd8fcb5e49501e/d/a64f19e4dbfc47a991d919a5595b4e29: Under replicated BP-1135703146-10.200.39.28-1574043673848:blk_1084998835_11258150. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
Status: CORRUPT
Number of data-nodes: 3
Number of racks: 1
Total dirs: 2884
Total symlinks: 0
Replicated Blocks:
Total size: 122742037956 B
Total files: 2440
Total blocks (validated): 2519 (avg. block size 48726493 B)
********************************
UNDER MIN REPL'D BLOCKS: 2 (0.07939658 %)
dfs.namenode.replication.min: 1
CORRUPT FILES: 2
CORRUPT BLOCKS: 2
CORRUPT SIZE: 2600425 B
********************************
Minimally replicated blocks: 2517 (99.9206 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (0.03969829 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.996824
Missing blocks: 0
Corrupt blocks: 2
Missing replicas: 2 (0.02646553 %)
Blocks queued for replication: 0
The filesystem under path '/hbase/data' is CORRUPT
可以发现tbl_glhis_hb_ct_settle_dtl_bas表有两个数据块丢失,具体文件也显示出来了,另外tbl_glhis_hb_ct_settle_dtl_bas_idx_mchnt_cd表存在数据块只有一个副本,默认应该为3个副本,也是不健康的状态,这时去hbase web页面查看,显示一直有Hbase region in transition,涉及到的region为上述不健康的region,当访问到这些region数据时,也会遇到NotServingRegionException异常
什么是RIT状态?
As regions are managed by the master and region servers to, for example, balance the load across servers, they go through short phases of transition. This applies to opening, closing, and splitting a region. Before the operation is performed, the region is added to the “Regions in Transition” list on the WEB UI, and once the operation is complete, it is removed.
rit是Region在进入打开,关闭,分割,再均衡等操作前的一种状态,而我们的环境一直出现,猜测跟数据块损坏有关
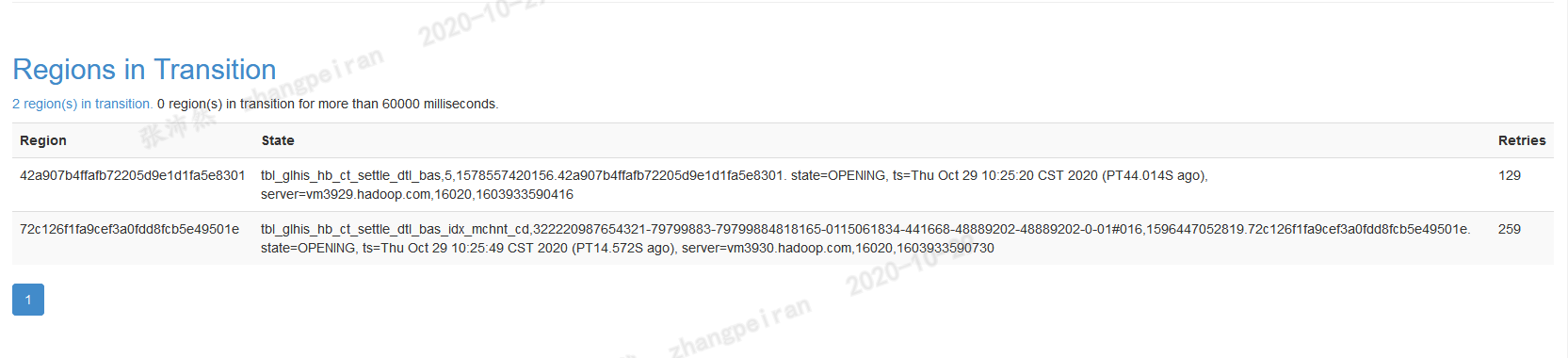
首先对丢失数据块的文件执行删除操作,执行后,查看RIT,tbl_glhis_hb_ct_settle_dtl_bas表涉及到region已经不在RIT列表里,再检查/hbase/data目录,已经没有缺失的数据块,状态为健康
hdfs fsck /hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/36cafb11c3a6455aaba1605b72bbb7c7 -delete
hdfs fsck /hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas/42a907b4ffafb72205d9e1d1fa5e8301/d/756ffcf3efd24971abe0195f8de5af1e -delete

hdfs fsck /hbase/data
Connecting to namenode via http://vm3928.hadoop.com:9870/fsck?ugi=hbase&path=%2Fhbase%2Fdata
/hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas_idx_mchnt_cd/72c126f1fa9cef3a0fdd8fcb5e49501e/d/a64f19e4dbfc47a991d919a5595b4e29: Under replicated BP-1135703146-10.200.39.28-1574043673848:blk_1084998835_11258150. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
Status: HEALTHY
Number of data-nodes: 3
Number of racks: 1
Total dirs: 2787
Total symlinks: 0
Replicated Blocks:
Total size: 122670925814 B
Total files: 2437
Total blocks (validated): 2512 (avg. block size 48833967 B)
Minimally replicated blocks: 2512 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (0.039808918 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.999204
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 2 (0.026539277 %)
Blocks queued for replication: 0
The filesystem under path '/hbase/data' is HEALTHY
继续对副本数不够的文件,执行如下修复操作,设置副本数为3
hadoop fs -setrep -w 3 /hbase/data/default/tbl_glhis_hb_ct_settle_dtl_bas_idx_mchnt_cd/72c126f1fa9cef3a0fdd8fcb5e49501e/d/a64f19e4dbfc47a991d919a5595b4e29
但是,在我们环境里,这个操作一直是waitting状态,查看了namenode节点上的日志如下,发现一直在报java.io.EOFException异常,看起来时datanode之间同步副本异常,暂时还没解决。。。
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: vm3928.hadoop.com:1004:DataXceiver error processing READ_BLOCK operation src: /10.200.39.29:57166 dst: /10.200.39.28:1004
java.io.EOFException
at java.io.DataInputStream.readShort(DataInputStream.java:315)
at org.apache.hadoop.hdfs.server.datanode.BlockMetadataHeader.readHeader(BlockMetadataHeader.java:139)
at org.apache.hadoop.hdfs.server.datanode.BlockMetadataHeader.readHeader(BlockMetadataHeader.java:153)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsVolumeImpl.loadLastPartialChunkChecksum(FsVolumeImpl.java:1137)
at org.apache.hadoop.hdfs.server.datanode.FinalizedReplica.loadLastPartialChunkChecksum(FinalizedReplica.java:157)
at org.apache.hadoop.hdfs.server.datanode.BlockSender.getPartialChunkChecksumForFinalized(BlockSender.java:444)
at org.apache.hadoop.hdfs.server.datanode.BlockSender.<init>(BlockSender.java:265)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.readBlock(DataXceiver.java:598)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opReadBlock(Receiver.java:152)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:104)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:291)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号