Python第17天
今日内容大纲
1 自定义模块
模块:
抖音:20万行代码全部放在一个py文件中?
为什么不行?
1.代码太多,读取代码耗时太长
2.代码不容易维护,
所以我们怎么样?
一个py文件拆分100文件,100个py文件又有相似相同的功能。、冗余,此时你要将100个py文件中相似相同的函数提取出来,input功能,print()功能,time.time()。os.path放在一个文件,当你想用这个功能拿来即用,类似于这个py文件:常用的相似的功能集合模块
模块就是一个py文件,常用的相似的功能集合
2 为什么要有模块
拿来主义,提高开发效率
便于管理维护
什么是脚本?
脚本就是py文件,长期保存代码的文件
4 模块的分类
1 内置模块 200种左右 Python解释器自定的模块,time OS SYS hashlib等等
2 第三方模块 ,一些大神写的,非常好用的。pip install 需要这个指令安装的模块,Beautiful_soup,request,django flask 等等 6000等
3 自定义模块 自己写的一个py 文件
5 import的使用
import 模块 先要怎么样?
import tbjx 执行一次tbjx 这个模块里面的所有代码
print(111)
import tbjx
print(222)
111
from the tbjx.py
666
222
第一次引用tbjx 这个模块,会将这个模块里面的所有代码加载到内存,只要你的程序没有结束,接下来你在引用多少次,他会先
从内存中查找有没有此模块,如果已将加载到内存了,就不重复加载
第一次导入模块,发生了三件事情
1 在内存中创建一个以tbjx 命名的名称空间
2 执行此名称空间所有的可执行的代码(将tbjx.py文件中所有的变量与值的对应关系加载到这个名称空间)
3 通过tbjx。的方式引用模块里面的代码(调用此模块的内容:变量,函数名,类名。。。)
import tbjx
print(tbjx.name)
from the tbjx.py
666
太白金星
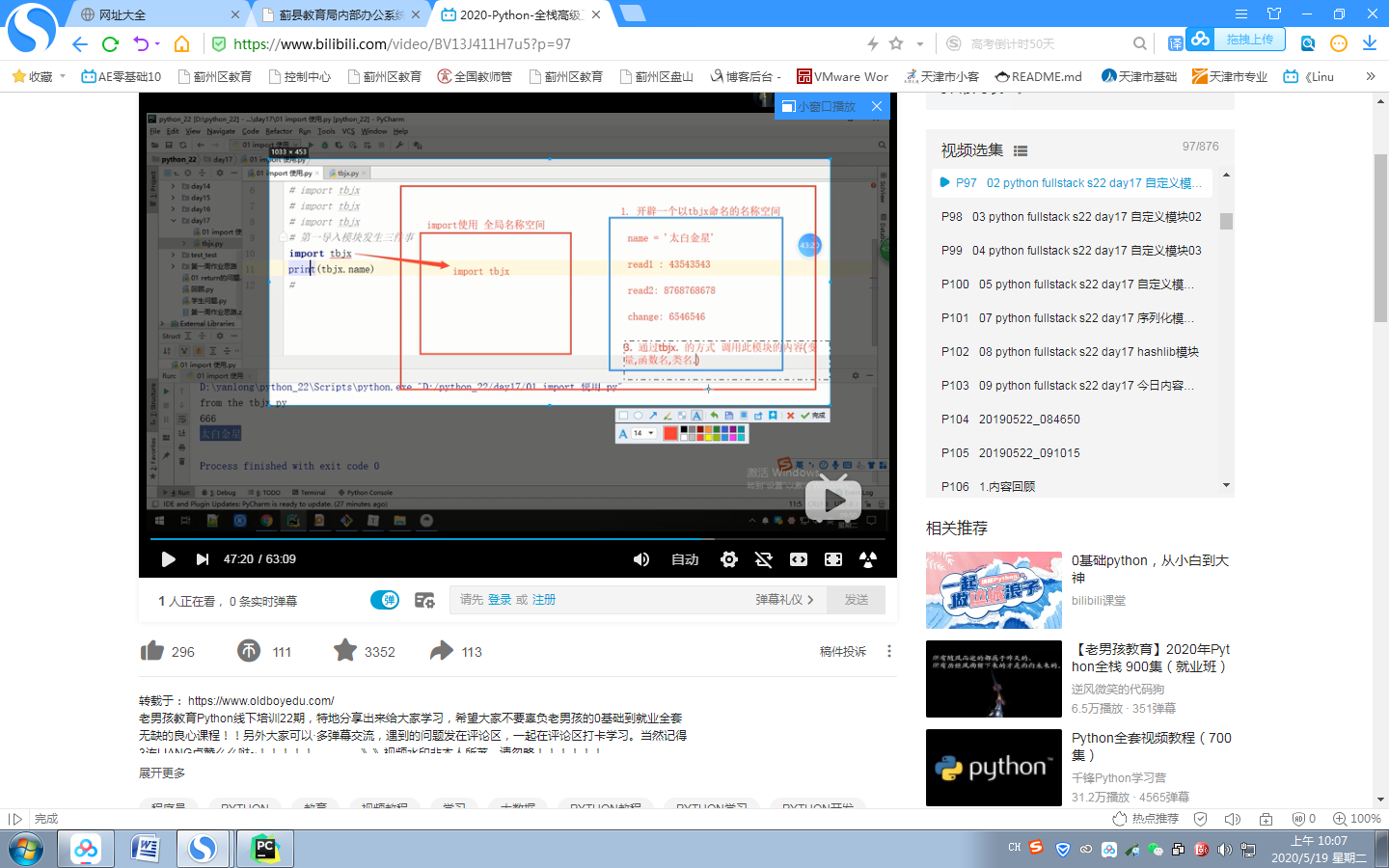
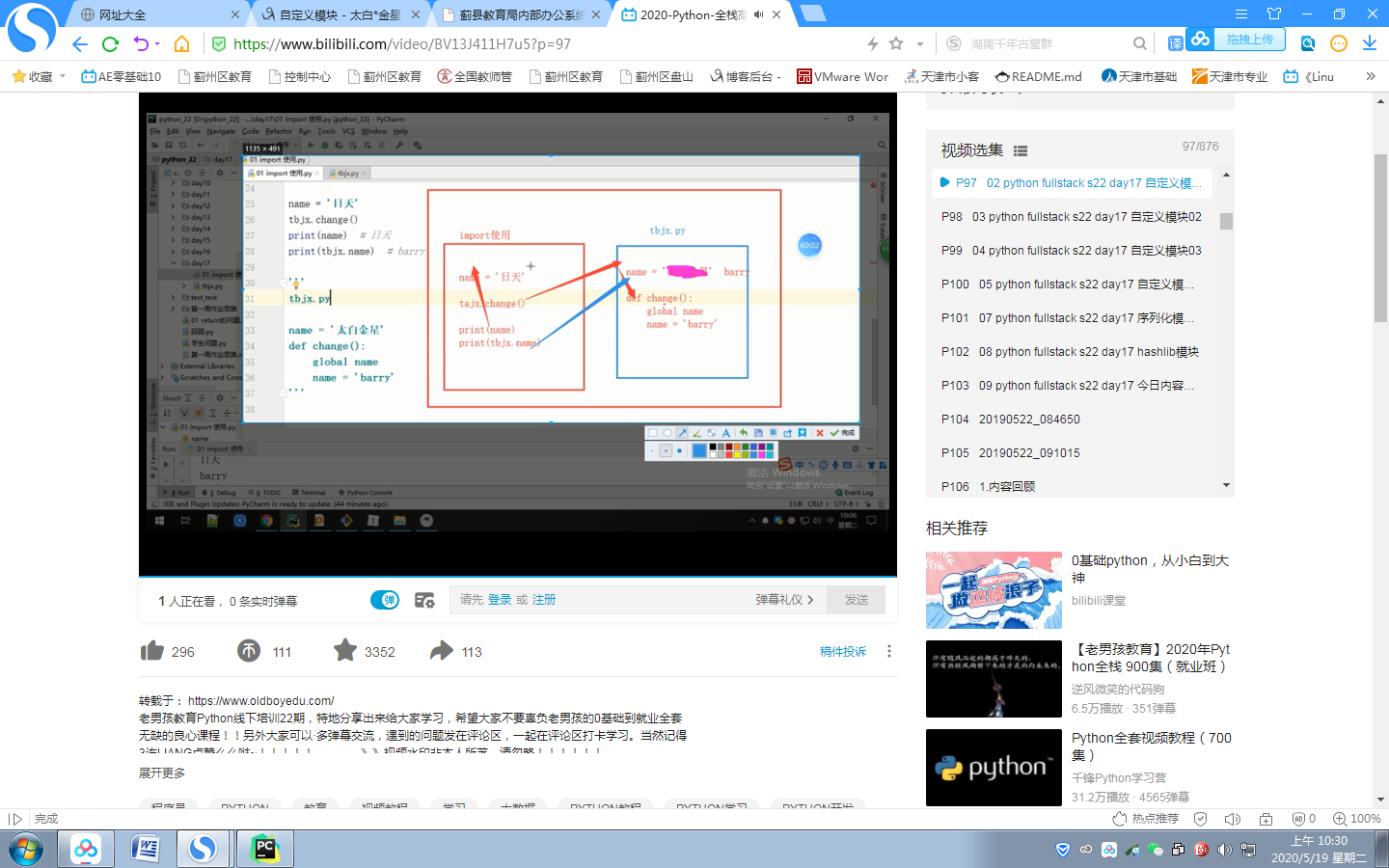
导入模块的文件是自己的名称空间 被导入的模块有独立的名称空间
#tbjx.py
print('from the tbjx.py')
name='太白金星'
def read1():
print('tbjx模块:',name)
def read2():
print('tbjx模块')
read1()
def change():
global name
name = 'barry'
print(666)
# from the tbjx.py
# 666
# 太白金星
import tbjx
# tbjx.read1()
# name='alex'
# print(name)
# print(tbjx.name)
# from the tbjx.py
# 666
# tbjx模块: 太白金星
# alex
# 太白金星
# def read1():
# print(666)
# tbjx.read1()
# from the tbjx.py
# 666
# tbjx模块: 太白金星
name='日天'
tbjx.change()
print(name)
print(tbjx.name)
# from the tbjx.py
# 666
# tbjx模块: 太白金星
为模块起别名
1 简单,便捷
2 有利于代码的简化
# result=input('qingshuru')
# if result == 'mysql':
# import mysql1
# mysql1.mysql()
# elif result == 'oricle':
# import oricle1
# oricle1.oricle()
result = input('qingshuriu:')
if result == 'mysql':
import mysql1 as sm
elif result == 'oricle':
import oricle1 as sm
from import
from tbjx import name
from tbjx import read1
print(name)
print(globals())
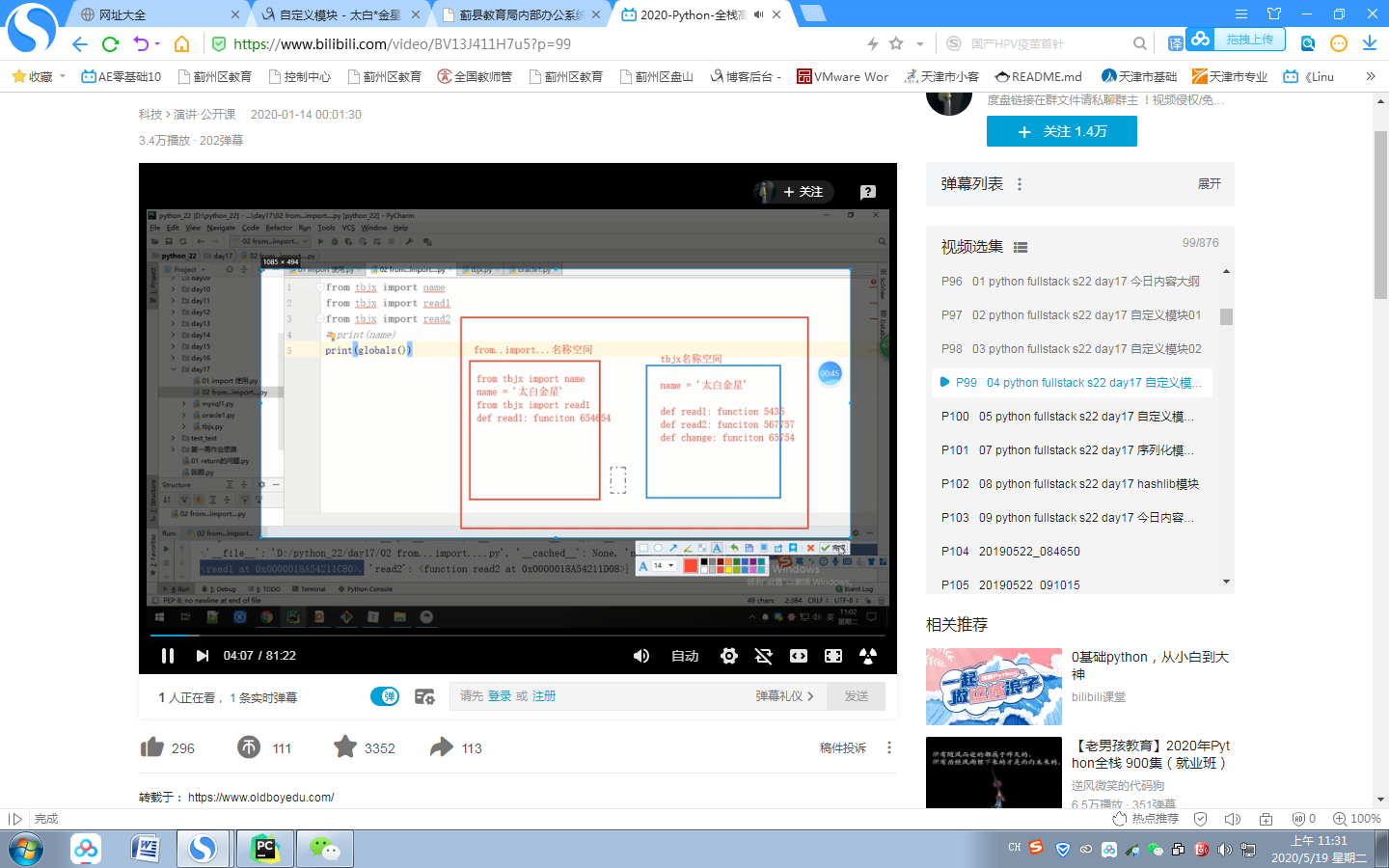
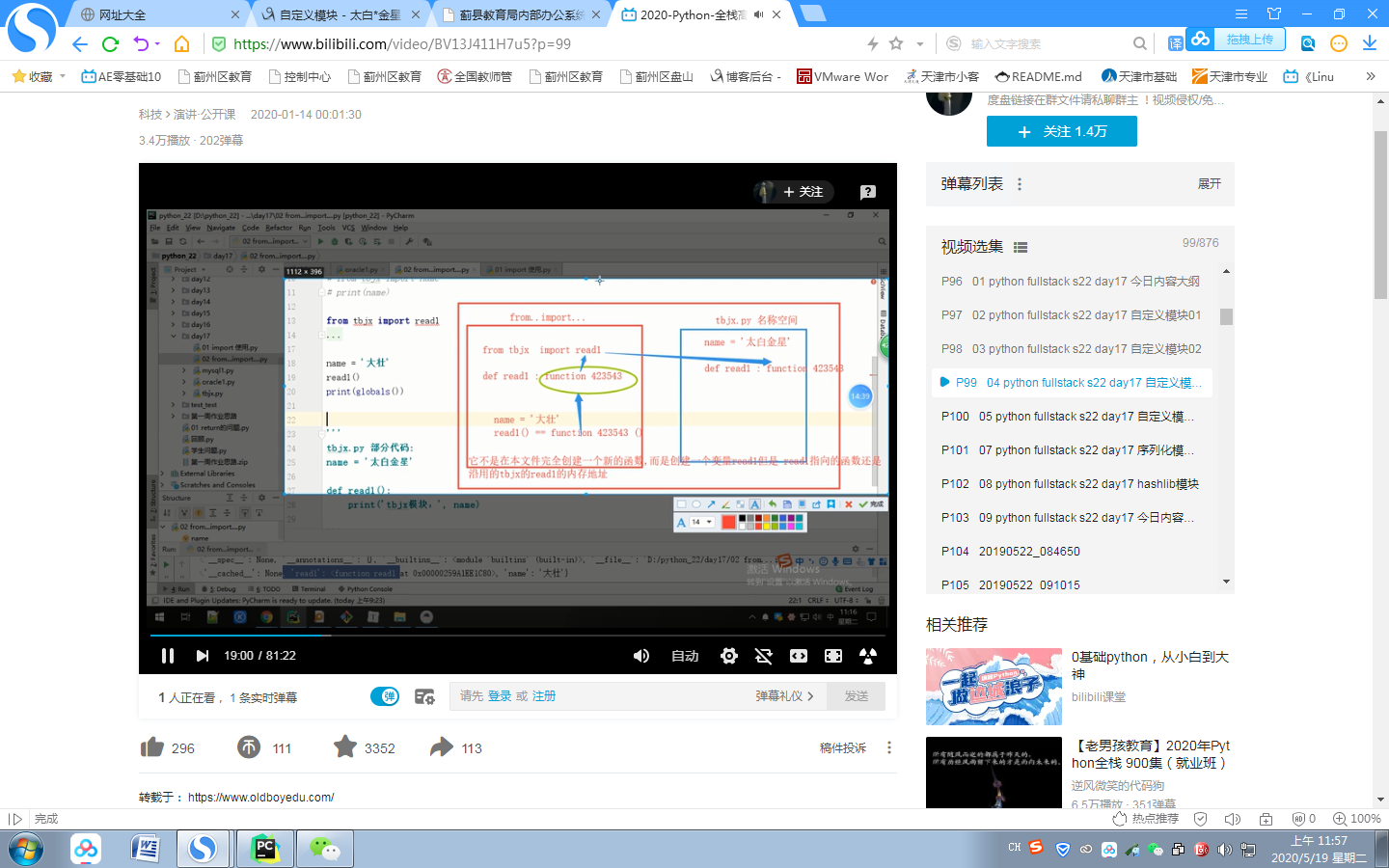
import和from import 的对比
1 from import 用起来更方便
2 from import 容易与本文件的名字产生冲突 后者将前者覆盖
# from tbjx import name
# from tbjx import read1
# print(name)
# print(globals())
# name='alex'
# from tbjx import name
#
# print(name)
from tbjx import change
name='alex'
print(name)
change()
from tbjx import name
print(name)
# def read1():
# # print(666)
# name='dazhuang'
# read1()

3 当前位置使用read1和read2,执行时,仍然以tbjx.py文件全局名称空间
一行导入多个
from tbjx import name,read1,read2 不好
from tbjx import name
from tbjx import tead1
from tbjx import *
__all__=['','']与*配合使用 在被调用个模块中
py文件的两个功能
1 要么自己使用 脚本 --name-- ==__main__
2要么被调用 模块使用 当tbjx.py被别引用时:__name__==tbjx
if __name__=‘main‘’
——name---根据文件扮演的角色(脚本、模块)不同而得到不同的结果
1 模块需要调试时,加上if __name__=‘main‘’
2作为项目的启动文件需要用
模块的搜索路径
import SM
1 他会先从内存中寻找有没有已经存在的以sm命名名称空间
2 他会从内置的模块中找,os sys time等
3 他会从sys.path中去找
内存中没有,内置没有,只能操作sys.path
import sys
sys.path.append(r'C:\Users\Administrator\Desktop\.idea\python1\aa')下划线是另一个文件的路径, append追加
sys.path会自动将你的当前目录的路径加载到列表中,自定义的模块,如果要引用自己自定义模块
将这个模块放到当前目录下面,要不就手动添加到sys.path中
总结:
import 模块 三件事 ,import的名字如何调用,模块名。的方式调用
from import 用起来方便容易与本文件产生冲突
from 模块 import 的使用
当前位置直接使用read1和read2,执行时,仍然以tbjx .py 文件全局名称空间
7 json pickle 模块
序列化模块:将一种数据结构(list tuple dict。。。)转化成特殊的序列。
为什么存在序列化?
数据------》bytes
只用字符串类型和bytes可以互换
dicti ,list。。。-----》str 《---------------》bytes
数据存储在文件中,str形式存储,比如字典
数据通过网络传输(bytes类型),str不能还原回去
特殊的字符串:序列化
序列化模块:
1 json( 重点)
2pickle
json:将数据结构转化成特殊的字符串,并且可以反转
两对四种方法
网络传输:dumps loads 主要是用于网络传输 但是也可以读写文件
dic={'name':'taibai'}
import json
st =json.dumps(dic,ensure_ascii=False)
print(st,type(st))
dic1=json.loads(st)
print(dic1,type(dic1))
写入文件
with open('json2',encoding='utf-8') as f2:
st=f2.read()
l1=json.loads(st)
print(l1,type(l1))
dump load只能写入文件,只能写入一个数据结构
l1=[1,2,3,{'name':'alex'}]
# with open('json3',encoding='utf-8',mode='w') as f1:
# json.dump(l1,f1)
with open('json2',encoding='utf-8') as f1:
l1=json.load(f1)
print(l1,type(l1))
#正确写法
dic1={'name':'alex'}
dic2={'name':'taib'}
dic3={'name':'dazhuang'}
# with open('json2',encoding='utf-8',mode='w') as f1:
# f1.write(json.dumps(dic1)+'\n')
# f1.write(json.dumps(dic2)+'\n')
# f1.write(json.dumps(dic3)+'\n')
with open('json2',encoding='utf-8') as f1:
for i in f1:
print(json.loads(i))
pickle 只有Python才有的
#
# l1=[1,2,3,{'name':'alex'}]
#dumps loads 只能用于网络传输
# import pickle
# st=pickle.dumps(l1)
# print(st)
#
# l2=pickle.loads(st)
# print(l2,type(l2))
#dump load用于写入文件
import pickle
# dic1={'name':'oldboy1'}
# dic2={'name':'oldboy2'}
# dic3={'name':'oldboy3'}
#
# f=open('pick_duoshujv',mode='wb')
# pickle.dump(dic1,f)
# pickle.dump(dic2,f)
# pickle.dump(dic3,f)
# f.close()
# f=open('pickduoshujv',mode='rb')
# print(pickle.load(f))
# print(pickle.load(f))
# print(pickle.load(f))
# f.close()
def func():
print('in func')
# f=open('pickduxiang',mode='wb')
# pickle.dump(func,f)
# f.close()
f=open('pickduxiang',mode='rb')
ret=pickle.load(f)
f.close()
8 hashlib模块
加密模块:包含很多的加密算法,MD5 , sha系列256 512
用途:
1 密码加密,不能以明文的形式存储密码,密文的形式
2 文件的校验
用法:
1 将bytes类型字符转化成固定长度的16进制数字组成的字符串
2 不同的bytes利用相同的算法(MD5)转化成的结果一定不同
3 相同的bytes类型利用相同的算法(MD5)转化陈的结果一定相同
4 hashlib 算法不可逆
# import hashlib
# def MD5(pwd):
# ret=hashlib.md5()
# ret.update(pwd.encode('utf-8'))
# return ret.hexdigest()
# def register():
# username=input('qingshuru:').strip()
# password=input('qingshuru:').strip()
# password_md5=MD5(password)
# with open('register',encoding='utf-8',mode='a') as f1:
# f1.write(f'\n{username}|{password_md5}')
# register()
# def login():
# uersname=input('qingshuru:').strip()
# password=input('qingshuru:').strip()
# password_md5=MD5(password)
# login()
普通的加密
#普通的加密
1 开机
2 加载内容
3 加密
import hashlib
s1='kdkkkkddkkddffff'
ret=hashlib.md5()开机
ret.update(s1.encode('utf-8'))加内容
print(ret.hexdigest())#6dae21d1fb8e209d2ba728136a15acb1加密
加盐(过程复杂)
#加盐
import hashlib
s1='19890425'
ret=hashlib.md5('taibai'.encode('utf-8'))
ret.update(s1.encode('utf-8'))
print(ret.hexdigest())
动态的盐
#动态的加盐
import hashlib
s1='19890425'
ret=hashlib.md5('taibai'[::2].encode('utf-8'))
ret.update(s1.encode('utf-8'))
print(ret.hexdigest())
sha系列
一般公司用不到,只有金融类 安全类用
#sha系列
#随着sha系列数字越高,加密越复杂,但是耗时越长
s1='ssddddddllllllllllfdfdfffffffffff'
ret=hashlib.sha3_512()
ret.update(s1.encode('utf-8'))
print(ret.hexdigest())
文件的校验
linux中一切都是文件:文本文件 非文本文件 音频 视频图片。。。
无论你下载的视频,还是软件(国外的软件)往往都会有一个MD5值
今日总结
1 import 三件事 import 的名字如果调用,模块名。的方式调用
2 from 。。。 import 容易产生冲突,独立的空间
3 --name--问题
4 模块的搜索路径
内存 内置 SYS。path
5 序列化模块:json 最常用的(两对四个方法) 一定掌握 pickle
6 hashlib
1 MD5值
2 文件的校验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号