Python第十一天
1 关键字 global nonlocal
2 函数名的运用
3 新特性:格式化输出
4 迭代器
可迭代对象
获取对象的方法
判断一个对象是否是可迭代对象
小结
迭代器
迭代器的定义
判断一个对象是否是迭代器
迭代器的取值
可迭代对象如何转化成迭代器
wilhe循环和for循环机制
小结
可迭代对象与迭代器的对比
1 关键字的陷阱
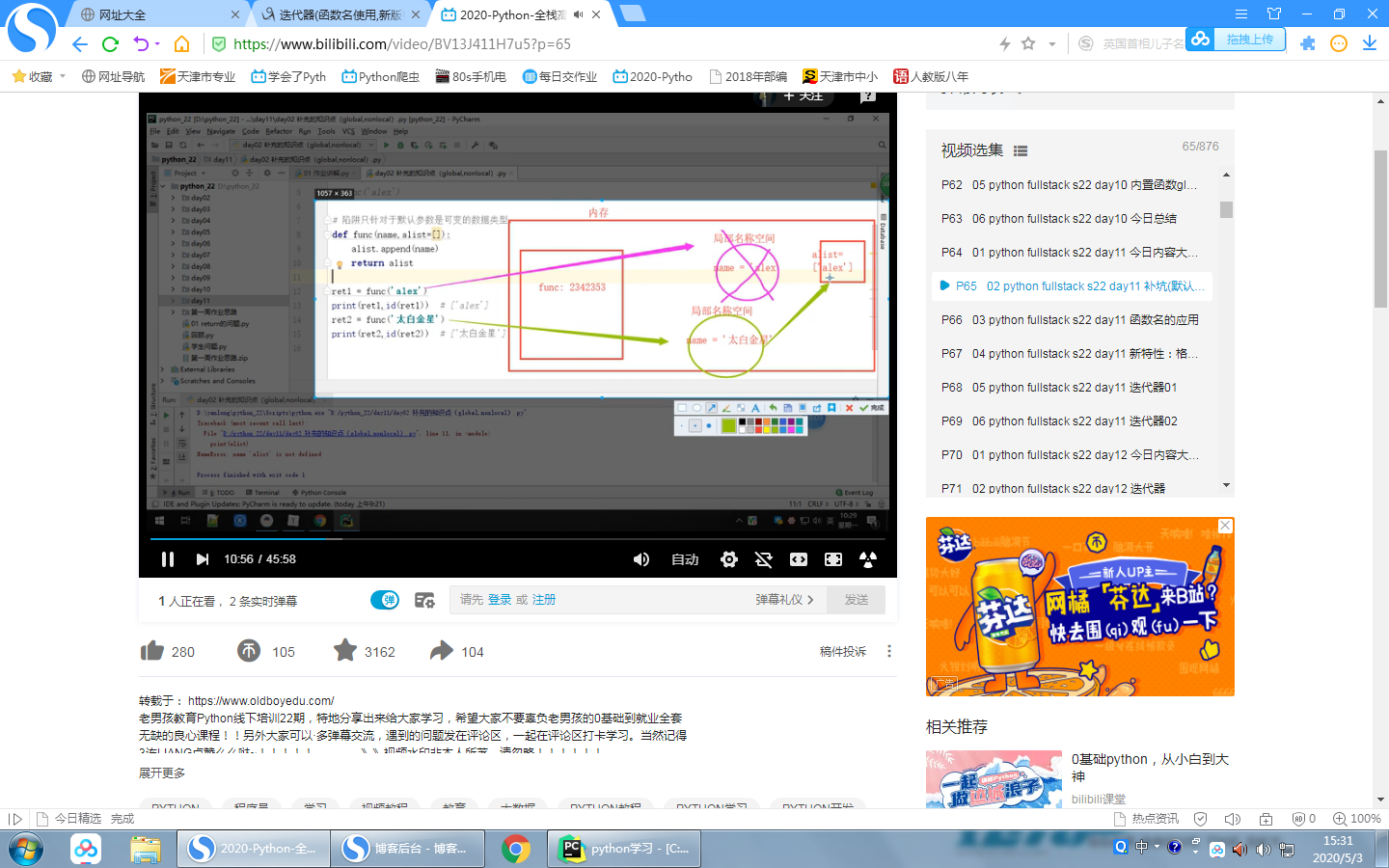
1 默认关键字的陷阱 陷阱只针对于默认参数是可变的数据类型
特殊的要记忆:如果你的默认参数指向的是可变的数据类型,那么你无论调用多少次这个默认参数,都是同一个
def func(name,alist=[]):
alist.append(name)
return alist
ret=func('al')
print(ret)#['al']
ret1=func('taib')
print(ret1)#['al', 'taib']
def func(a,list=[]):
list.append(a)
return list
print(func(10,))#[10]
print(func(20,[]))#[20]注意这个传的实参是20,[] 形参就接受20,[]代替了list[] 也就是新开辟了一个新空间
print(func(100,))#[10, 100]
def func(a,list=[]):
list.append(a)
return list
ret=func(10,)
ret1=func(20,[])
ret2=func(100,)
print(ret)#[10, 100]#程序执行到这ret和tet2都执行了 这是坑
print(ret1)#[20]
print(ret2)#[10, 100]
2 局部作用域的坑 在函数中 如果你定义了一个变量,但是在定义这个变量之前对其引用了,那么解释器认为语法错误
他认为你应该在使用之前先定义 如下面的第二个
下面两都报错
count=1
def func():
count+=2
print(count)
func()
# count=1
# def func():
#
# print(count)
# count=2
# func()
2 补充两个关键字 global nonlocal
global
1 在局部作用域声明一个全局变量
def func():
global name#在函数中声明全局变量
name='tai'
print(name)#tai
func()
print(name)#tai
def func():
global name
name='tai'
print(name)#函数没有执行 name变量没有声明成全局变量,先引用 报错
func()
2 修改一个全局变量
count=1
def func():
#print(count)
global count
count+=1
func()
print(count)
nonlocal
1不能够操作全局变量
cout=1
def func():
nonlocal count
count+=1
func()
print(cout)
2 局部作用域 内层函数对外层函数局部变量进行修改
def wrapper():
count=1
def inner():
nonlocal count
count+=1
inner()
wrapper()
2函数名的应用
函数名的定义和变量的定义几乎一致,在变量的角度,函数名其实就是一个变量,具有变量的功能:可以赋值,但是作为函数名他又有特殊的功能就是加上()就会执行对应的函数,所以我们可以把函数名当成一个特殊的变量。
1、函数名指向的是函数的内存地址
def func():
print(666)
print(func)#<function func at 0x009A18E8>
2、函数名就是变量 可以赋值给其他变量
def func():
print(66)
f=func
f1=f
f2=f1
f2()
def func():
print('in func')
def func1():
print('in func1')
func1=func
func1()#in func
3函数名可以作为容器类数据类型的元素
def func1():
print('in func1')
def func2():
print('in func2')
def func3():
print('in func3')
l1=[func1,func2,func3]
for i in l1:
i()#in func1
# in func2
# in func3
4. 、函数名可以作为函数的参数
def func():
print('in func')
def func1(x):
x()
func1(func)#in func
5、函数名可以作为函数的返回值
def func():
print('in func')
def func1(x):
return x
ret=func1(func)
ret()#in func
3、格式化输出f-string
%S format
name='taib'
age=18
msg='我叫%s,今年%s'%(name,age)
print(msg)
msg1='我叫{},今年{}'.format(name,age)
print(msg1)
新特性:格式化输出 f-string
name='taib'
age=18
msg=f'我叫{name},今年{age}'
print(msg)
可以加表达式
dic={'name':'alex','age':73}
msg=f'wojiao{dic["name"]},jinnian{dic["age"]}'
print(msg)#wojiaoalex,jinnian73
# count=3
# print(f'zuizhongjieguo:{count**2}')
name='barry'
msg=f'wodemingzishi {name.upper()}'
print(msg)
结合函数写
def sum1(a,b):
return a+b
msg=f'zuizhongjieguoshi:{sum1(1,2)}'
print(msg)
优点:1 结构简化 更清晰更简化
2 可以结合表达式,函数进行使用
3效率提升很多
4 迭代器
1可迭代对象
解释:(可以for循环)
字面意思:对象? Python中一切皆对象。一个实实在在存在的值就是对象
可迭代:更新迭代。重复的 循环的一个过程,更新迭代每次都有新的内容
可以进行循环更新的一个实实在在的值。
专业角度:可迭代对象 内部含有'_ _iter_ _'方法的对象,可迭代对象
目前学过的可迭代对象:str list tuple dic set range 文件句柄
2 获取对象的所有方法并且以字符串的形式表现:dir()把对象的所有方法以字符串的形式放到一个列表中返回
s1='dddddddddd'
print('__iter__'in dir(s1))
l1=[1,2,3]
print('__iter__' in dir(l1))
3 判断一个对象是否是可迭代对象的方法 ‘__iter__’ in dir()
4小结
字面意思:可以进行循环更新的一个实实在在的值
专业角度:内部含有‘__iter__’方法的对象
判断一个对象是否是可迭代对象:‘__iter__’ in dir()
str list tuple dic set range 文件句柄
优点:1 存储的数据直接能显示,比较直观
2 拥有的方法比较多,操作方便
缺点:1 占用内存
2 不能直接通过for循环,不能直接取值(除索引,切片)
5迭代器
迭代器的定义:
字面意思:更新迭代 器:工具 可以更新迭代的工具
专业角度:内部含有'__iter__'并且含有'__next__'方法的对象就是迭代器
可以判断是否是迭代器:''__iter__' and '__next__' 在不在dir(对象)
可迭代对象可以转化成迭代器
# with open('E:\student_msg',encoding='utf-8',mode='a') as f1:
# f1.write('sssss')
#
# print(('__iter__' in dir(f1)) and ('__next__'in dir(f1)))这个是
#
# s1='ffffffffffffffff'
# print(('__iter__' in dir(s1)) and ('__next__'in dir(s1)))这个不是
迭代器的取值
next()
# s1='ddddddddd'
# obj=iter(s1)
# print(('__iter__' in dir(obj)) and ('__next__'in dir(obj)))
#
# print(next(obj))
l1=[11,22,33,44,55,66]
obj=iter(l1)
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
可迭代对象如何转化成迭代器
iter(可迭代对象)
小结:
迭代器的优点:1 节省内存 2 惰性机制 next一个 取一个值 绝不多取
有一个迭代器模式可以很好的解释上面这两条:迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项, 这就是迭代器模式
迭代器的缺点:速度慢 不走回头路
下面这个是可迭代对象 每次取值从头开始
l1=[11,22,33,44,55,66,77,88,99]
# count=0
# for i in l1:
# if count==3:
# break
# else:
# print(i)
# count=count+1
#
# count=0
# for i in l1:
# if count==6:
# break
# else:
# print(i)
# count=count+1
迭代器 每次重新取值 会记住上次后的位置
l1=[11,22,33,44,55,66,77,88,99]
obj=iter(l1)
for i in range(4):
print(next(obj))
for i in range(3):
print(next(obj))
可迭代对象和迭代器的对比
可迭代对象是一个操作方法比较多 比较直观 存储数据相对少的一个数据集
用处:当你侧重于对于数据可以灵活处理,并且内存空间足够,将数据集设置为可迭代对象是明确的选择
迭代器
是一个非常节省内存,可以记录取值位置,可以直接通过循环+next方法取值,但是不直观 操作方法单一的数据集
用处:当你的数据量过大,大到足以撑爆你的内存或者你以节省内存为首选时,将数据集设置为迭代器是一个不错的选择
数据相对少:几百万个数据 8个G内存时可以是迭代对象
5 while循环模拟for循环的机制
l1=[11,22,33,44,55,66,77,88,99]
obj=iter(l1)#将可迭代对象转化成迭代器
while 1:
try:
print(next(obj))
except StopIteration:
break
利用while循环模拟for循环对可迭代对象取值的进制
作业
def func1():
# print('in func1')
# def func2(x):
# print('in func2')
# return x
# def func3(y):
# print('in func3')
# return y
# ret=func2(func1)
# ret()
# ret2=func3(func2)
# ret3=ret2(func1)
# ret3()
# 运行结果
# in func2
# in func1
# in func3
# in func2
# in func1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号