Python第六天
1 is ==Id用法
2 代码块
3同一代码块的缓存机制
4不同代码块下的缓存机制(小数据池)
5总结
6集合()
7深浅copy
1 ID is ==
ID ID就是内存地址,只要创建了一个数据(对象)那么就在内存中开辟一个空间,将这个数据临时加载到内存中,那么这个空间是有唯一标识的,就好比是身份证号,标识这个空间的叫内存地址。也就是这个书记处(对象)的ID,用id(这里是变量名)去获取这个数据的内存地址
name=‘他’
print(id(name))# 15963331247
is
== 是比较两边的数值是否相等, is 是比较两边的内存地址是否相等。如果内存地址相等,那么两边其实是指向了同一个内存地址
i=100
i1=100
i2=100
print(i1==i2)# true 数值相等
print(i1 is i2) #false 不是同一个内存地址
内存地址相同,值一定相同
值相同,内存地址不一定相同
2 代码块
Python程序是由代码块构造的。块是一个Python程序的文本,他是作为一个单元执行的
代码块:一个模块 一个函数 一个类 一个文件都是一个代码块
注意 交互式输入的命令 一行就是一个代码块
一个文件中有两个函数
def func():
pass
def func1():
pass
这是两个代码块
3 同一代码块中的缓存机制
前提前提条件:在同一个代码块内
机制内容:Python在执行同一个代码块的初始化对象的命令时,会检查其值是否已经存在。如果存在,会将其重用。 就是 执行同一代码块时,遇到初始化对象的命令时,他会将初始化的变量与值存储在一个字典中,再遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值 如文件执行时(同一代码块)会把i1i2两个变量指向同一个对象, 满足缓存机制则它们在内存中只存在一个 就是ID相同
适用对象:int str bool 不可变的数据类型
具体细则: 所有的数字 bool 几乎所有的字符串
初始化对象 就是设置变量
先检查内存中的字典有无此数据
i1=100
i2=100
i3=100#内存地址是同一个
优点:节省内存 提升效率
4 不同代码块下的缓存机制
Python自动将-5——256的整数进行了缓存,当你将这些数据赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象
Python会将一定规则的字符串在字符串驻留池直观创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象,而是使用在字符串驻留池中创建好的对象
其实 无论是缓存还是字符串驻留池,都是Python做的一个优化,就是讲-5——256的整数,和一定规则的字符串,放在一个池(容器 或字典)中,无论程序中那些变量指向这些范围内地整数或字符串,那么他直接在这个池中引用 ,言外之意 局势内存中创建一个
适用对象:int str bool
不同的代码块 交互式命令时出现(例子)
i1=1000
i2=1000
i3=1000
print(id(i1))
print(id(i2))
print(id(i3))同一代码块是同一内存地址
交互式命令
i1=1000
i2=1000
i3=1000
print(id(i1))
print(id(i2))
print(id(i3))不同代码指向的不是同一内存地址
具体细则:在-5 -256中就是同一个小数据池 bool 满足规则的字符串(了解即可)
5 总结
1面试题考
2回答时一定分清楚 同一代码块下适用一个缓存机制 不同的代码块下适用另一个缓存机制(小数据池)
3小数据池 数字是-5-256
4优点: 提升性能 节省内存
6 集合
容器型的数据类型 要求它里面的元素是不可变的数据 但是它本身是可变的数据类型 集合是无序的 不重复的 {}里面放的是无序的就是集合 放键值对的是字典
集合的作用:列表的去重 关系测试:交集 并集 差集
# set1=set({1,3,'tau',False,'alex'})
# # set={1,3,'tau',False,'alex'}
# # print(set)
#
# print({},type({}))#空字典
# set1=set()
# print(set1)#空集合
1 集合的有效性测试
# set ={[1,2,3],'name',{'name':'value'}}
# print(set)
set={'taib','nvsh','wuda','alex'}
2 增 add
# set.add('xx')
# print(set)#{'nvsh', 'alex', 'taib', 'wuda', 'xx'}只增加一个
#
# #update迭代着增加
# set.update('fdsfffag')
# print(set)#{'f', 'd', 'alex', 's', 'g', 'nvsh', 'a', 'taib', 'wuda', 'xx'}去重增加迭代
3 删 remove 按照元素删
# set.remove('wuda')
# print(set)#{'alex', 'taib', 'nvsh'}
#随机删除 pop
# set.pop()
# print(set)
4 变相改 先删除 还增加 集合应该无法改
set.remove('taib')
set.add('namsheng')
print(set)
5 集合的交集
# set1={1,2,3,4,5}
# set2={4,5,6,7,8}
# print(set1 & set2)#{4, 5}
#
6#并集
# print(set1 | set2)#{1, 2, 3, 4, 5, 6, 7, 8}
#
7 #差集
# print(set1 -set2)#{1, 2, 3}
# print(set2-set1)#{8, 6, 7}
#
8 #反交集
# print(set1^set2)#{1, 2, 3, 6, 7, 8}
set1={1,2,3,4,5}
set2={1,2,3,4,5,6,7,8}
9子集
print(set1<set2)#True
10 超集
print(set2>set1)
11列表的去重 不保留原来顺序用这种方法
l=[1,1,2,2,2,3,4,5,6,6,6]#用列表转化集合去做简单
set1=set(l)# 数据转化成谁用谁包起来
l=list(set1)#转化成列表用list包起来
print(l)
#用处是;数据之间的关系 列表去重
7 深浅copy
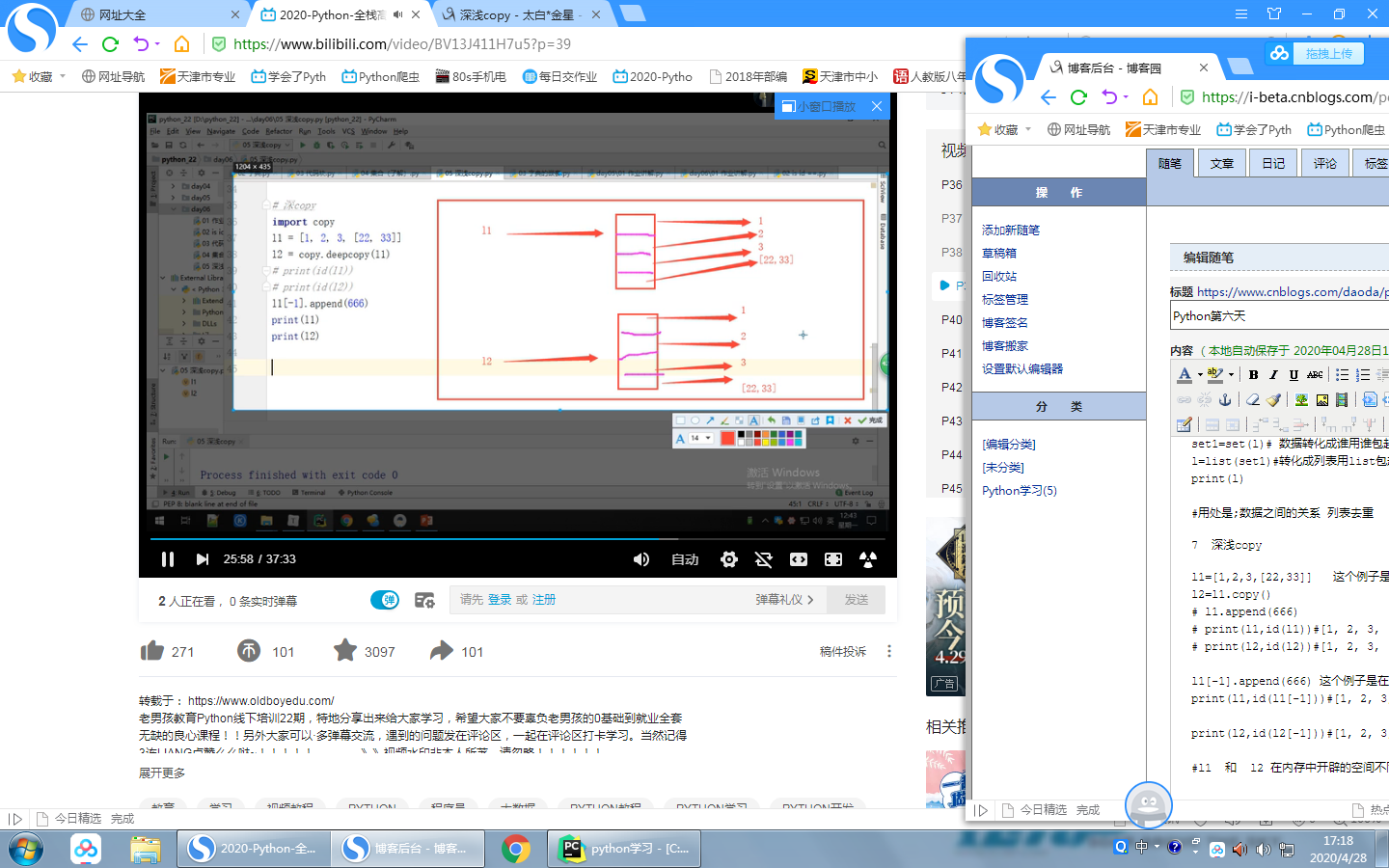
l1=[1,2,3,[22,33]] 这个例子是在l1 中增加新元素了 l2 不增加
l2=l1.copy()
# l1.append(666)
# print(l1,id(l1))#[1, 2, 3, [22, 33], 666] 19941976
# print(l2,id(l2))#[1, 2, 3, [22, 33]] 20301384 是两个列表 注意和上边赋值的区别
l1[-1].append(666) 这个例子是在l1 原有元素中增加 l2同样增加
print(l1,id(l1[-1]))#[1, 2, 3, [22, 33, 666]] 6899192
print(l2,id(l2[-1]))#[1, 2, 3, [22, 33, 666]] 6899192
#l1 和 l2 在内存中开辟的空间不同,但指向的数据列表里的元素相同
对下图中的解释:仔细看图

浅copy只是copy一个外壳 里面的所有内容都指向一个
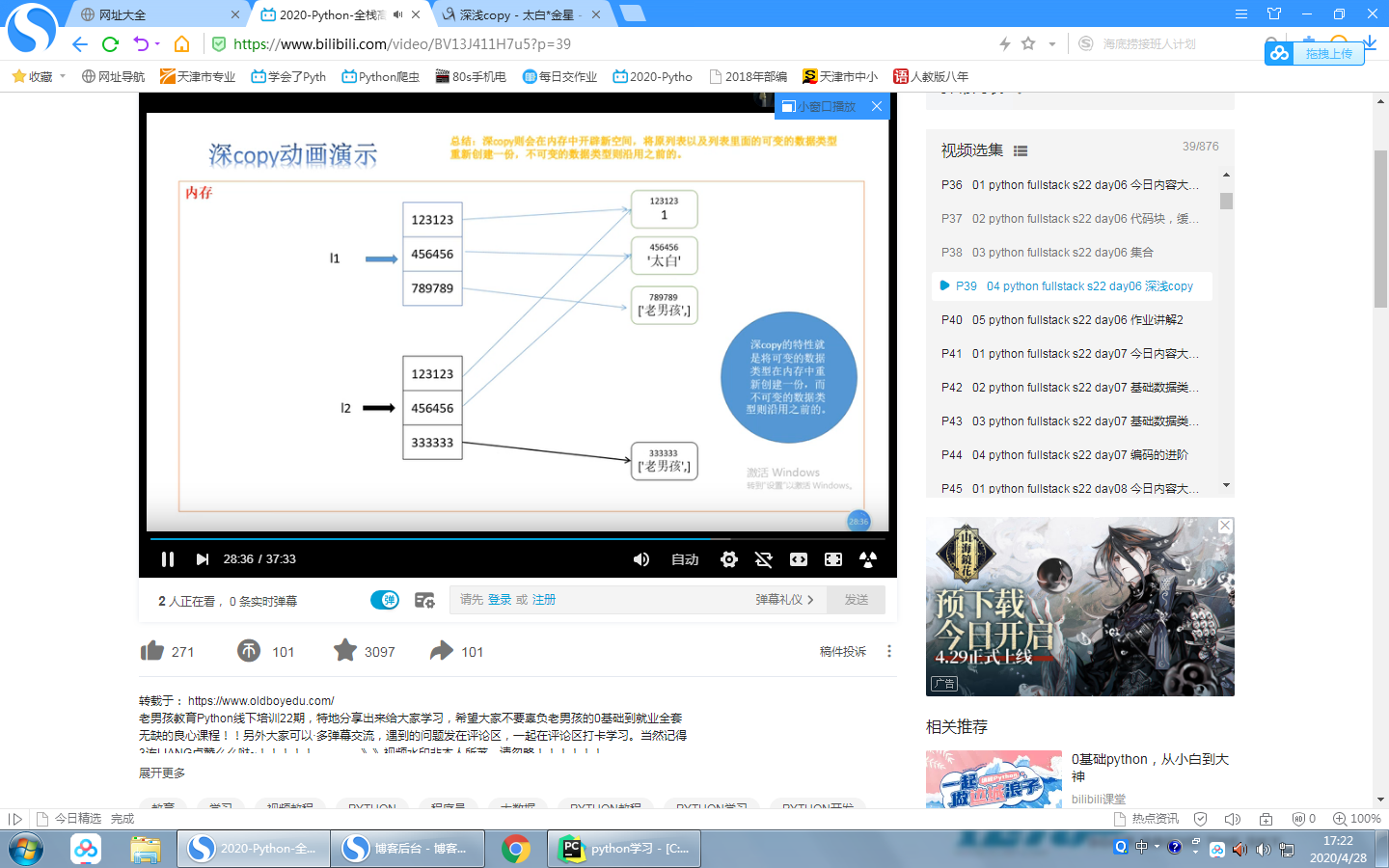
深copy
Python对深copy做了优化 对不可变的数据类型沿用同一个,可变的数据类型各自是各自的互补影响
#深copy
import copy
l1=[1,2,3,[22,33]]
l2=copy.deepcopy(l1)
l1[-1].append(666)
print(l1)#[1, 2, 3, [22, 33, 666]]
print(l2)#[1, 2, 3, [22, 33]]
l1=[1,2,3,[22,33]]
l2=l1[:]# 可变的数据类型共用一个就是浅copy 可变数据类型不共用就是深 全切片是浅copy
l1[-1].append(666)#浅copy:list dictionary :嵌套的可变类型是同一个
#深copy:list dictionary :嵌套的可变类型不是同一个
print(l1)
print(l2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号