数据采集——第一次作业
作业1:打印爬取的大学排名信息
1)代码&结果截图
import urllib.request
from bs4 import BeautifulSoup
def gethtmltext(url):
try:
html=urllib.request.urlopen(url)
html=html.read()
html=html.decode()
return html
except:
return "error"
def data(html,num):
# 标题在'theard'的子节点'tr'下,但是感觉直接打印更方便hhh
print("排名","\t","学校名称","\t","省市","\t","学校类型","\t","总分")
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
# 通过F12根据网页高亮提示,查找到有关大学排名相关信息的tag在'tbody'的子节点'td'下
# 所以查找所有的td节点存到tds中
tds = tr.find_all("td")
# 直接将结果打印出来
# 使用 strip() 移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
# 注意:strip() 只能删除开头或是结尾的字符,不能删除中间部分的字符
# 不使用strip()无法正确打印大学名称
if num > 0:
print(tds[0].text.strip()+"\t"+tds[1].text.strip()+"\t"+tds[2].text.strip()+"\t"+tds[3].text.strip()+"\t"+tds[4].text.strip())
num = num-1
if __name__ == '__main__':
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=gethtmltext(url)
data(html,30) #取前三十的大学
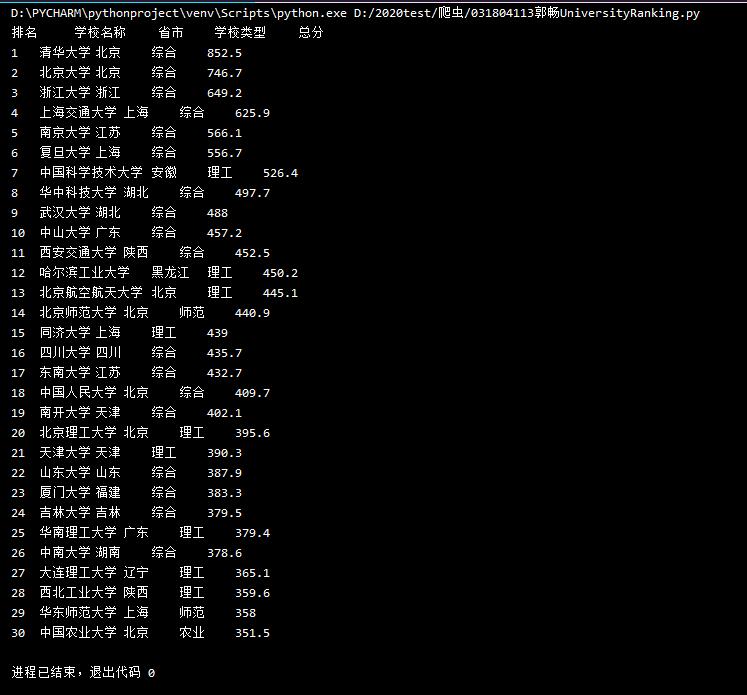
2)心得体会
第一次写爬虫,虽然最后的代码很短也看起来比较简单,但是还是需要花不少时间百度,进行代码改错是一方面,知道思路但是具体实现又是一方面(道理我都懂,但是emmmm)
刚开始在URL上出问题,查了半天,才发现之前那个地址已经不存在了hhh
在开发人员工具里寻找tag还是蛮有意思的
使用了findall,感觉还是蛮神奇的,好用的呀
在前面都还好,参考了网上的一些代码照猫画虎,但是在最后的输出出了问题,大学名称出不来,而且format格式也不正确,最后查找+询问下才知道要strip去掉空格才行(emmmm还是不太懂)
作业2:爬取商城商品名称及价格
1)代码&结果截图
import requests
import re
def getHTMLText(url):
try:
# 淘宝网有反爬机制,要使用headers解决
# headers理解:headers是解决requests请求反爬的方法之一,对反爬虫网页,设置一些headers信息,将自己模拟成浏览器取访问网站
header = {'cookie':'miid=871473411901751759; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5v3gzlT6TfC88%2B8VsR2LZeh0x0uZ2lavUunwk7FaQvkKtSF8tQ1fLpJrqsz14B%2FyobMQW8Exzoggkl4YwBJKriMzZBFIh%2FIQKv1FPsNnhV6P2HnGBVjbylCyWiAFwW1fvt3aOBQ3uoAwtp6Of66wJHZ8YPC4wCiq2449kBKT6ufwkDkOEQ0bb3%2BTywKDqprZHDdiDO7zqxULUBvZcPasjtJ6gwye5pjKqluzqIlGZw5KubUzluZEGHyoRYm; lLtC1_=1; t=da76da827c8812bfc2ef4d091ab75358; v=0; _tb_token_=3f7e30eaede6e; _m_h5_tk=55efe72e4a7e4752c144c9d9a52250c0_1600601808838; _m_h5_tk_enc=480b7ec5d4482475e3f5f76e0f27d20f; cna=ZgXuFztWFlECAdpqkRhAo4LI; xlly_s=1; _samesite_flag_=true; cookie2=13aa06fa1e7317d5023153e70e45e95f; sgcookie=E100jT6nEM5pUv7ZaP1urbIUwS5ucPPcz2pG%2FHs9VDYB91E14tzvEV8mMtRfZtLe4dg8rBjdN9PEuYVfhzjqARIFKQ%3D%3D; unb=2341324810; uc3=id2=UUtP%2BSf9IoxzEQ%3D%3D&nk2=t2JNBkErCYOaTw%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCufeJMlcWOvLCctE%3D; csg=6e737d42; lgc=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie17=UUtP%2BSf9IoxzEQ%3D%3D; dnk=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; skt=d79995fc094af782; existShop=MTYwMDU5MTk1Ng%3D%3D; uc4=id4=0%40U2l1DTh9%2F%2BK9Ym%2BCcxbZCceodFVg&nk4=0%40tRGCEUSTUyhwCCuPpi69tV6rFUkp; tracknick=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=%E6%89%8B09; _nk_=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie1=AVdDOYh1aRzl%2BX23%2BL5DKrLq3hm6%2F%2BaYgNDVsRdW80M%3D; enc=Amz2MhdAq1awG9cmHzc5MLNi%2Bing6y4cR5EbHVPlJhWJxNKvr0B40mznTsnKW0JcubOujE6qhizMA84u7mBq2Q%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=85_1; uc1=existShop=false&cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&cookie14=Uoe0bU1NOIsDOA%3D%3D&cookie21=WqG3DMC9Fb5mPLIQo9kR&pas=0&cookie15=UIHiLt3xD8xYTw%3D%3D; thw=cn; JSESSIONID=6ECE41F4DC42E868790A52C0B362FD3C; isg=BNTUg0Kud-Dz7-OsCcrIFwHdpRJGLfgXLSfdwW61YN_iWXSjlj3Ip4rbWVFBujBv; l=eBgY5g8rOF5Pi0CSBOfanurza77OSIRYYuPzaNbMiOCP9b1B5N21WZru8mY6C3GVh60WR3rZpo7BBeYBqQAonxv92j-la_kmn; tfstk=cyJcBsT6YI5jdt1kOx6XAqHF5iMdwE3VudJvULmsgZ-4urfcF7PEePnlzEvT1',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
r = requests.get(url, headers=header, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "error"
def parsepageandprintresult(result, html): # 查找结果并打印
try:
# 通过正则表达式获取html上所有的商品价格
price = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
# “view price\”来自于:点进任一商品页面,右键查看源代码,商品价格的html属性为view price,商品名称的属性为raw title
# ‘\"’匹配双引号
# ‘view_price’匹配view_price
# ‘\:’匹配冒号
# ‘\d\.’匹配一个整数加一个小数点
# ‘[]*’ *号匹配中括号内的正则表达式,商品名称同理
# (r'') r表示单引号内全为正则表达式符号
# 获取商品名称
title = re.findall(r'\"raw_title\"\:\".*?\"',html)
print("序号", "价格", "商品名称")
for i in range(len(title)):
goodsprice = eval(price[i].split(':')[1])
# eval()将字符串str当成有效的表达式来求值并返回计算结果
# price[i].split(':')[1] 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型,用":"隔开,此式是将数组price的第i个字符串进行分割。
goodstitle = eval(title[i].split(':')[1])
print(i,goodsprice,goodstitle) # 直接将结果进行打印
except:
print("error")
def main():
# 只做到打印当前页的商品信息
goods = '笔记本'
url = 'https://s.taobao.com/search?q=' + goods
result = []
html = getHTMLText(url)
parsepageandprintresult(result, html)
main()
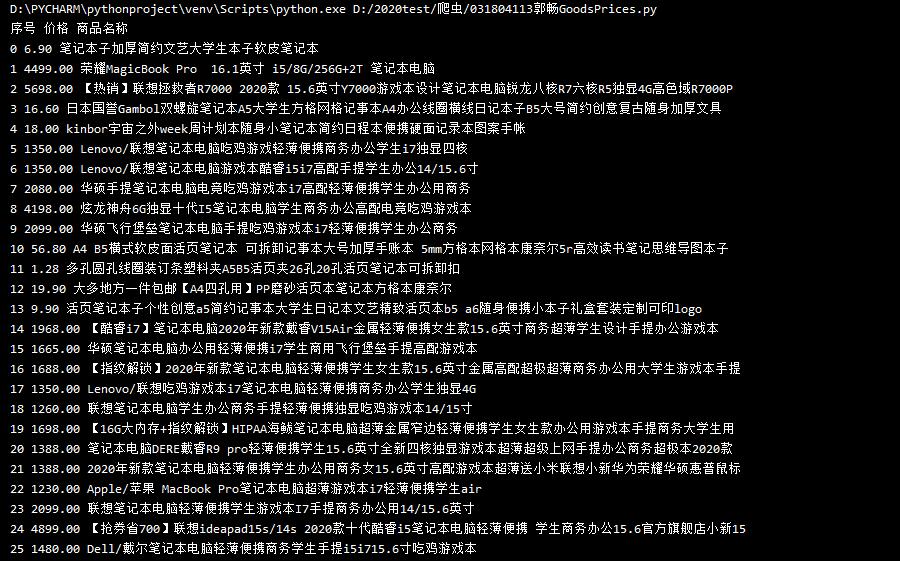

2)心得体会
第二次写爬虫,emmm,用正则表达式好像跟第一次没啥关系了555
这次被headers跟正则表达式里的属性难住了
淘宝网的反爬机制解决要用headers也是百度了才知道,以及使用格式,我觉得getHTMLText()函数算是固定的叭,直接放上去就可了
正则表达式里的view_price和raw_title这两个HTML属性,始终没找到在哪里555,在网上有查,但是还是不懂怎么做,只能借鉴网上的了
总的来说,这次的作业还是收获满满的,在查阅的过程中也扩展一些知识,在最后代码运行结果出来以后,感觉真的很好的说
(幸亏在最后想起来修改博客,之前的view_price和raw_title属性已经成功找到啦,之前好像是浏览器搜索有点奇怪——9.30)
作业3:爬取网页的jpg图片
1)代码&结果截图
import urllib.request
import re
url = "http://xcb.fzu.edu.cn/"
webPage=urllib.request.urlopen(url)
data = webPage.read()
data = data.decode('UTF-8')
#处理网页提取图片链接
k = re.split(r'\s+',data)
s = []
sp = []
si = []
for i in k :
# match()函数只检测RE是不是在string的开始位置匹bai配
# search()会扫du描整zhi个string查找匹配,会扫描整个字符串并返回第一个成功的匹配
# 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
if (re.match(r'src',i) or re.match(r'href',i)):
# 使用正则表达式进行每步寻找图片信息
# 将每步结果打印出来,可以更加显式的看出来是否提取正确
# print(i)
if (not re.match(r'href="#"',i)):
# print(i)
if (re.match(r'.*?jpg"',i)):
# print(i)
if (re.match(r'src',i)):
if("http" in i):
# 查询到该网站最下面一行是链接的图片不是,略过
continue
else:
s.append(i)
for it in s :
if (re.match(r'.*?jpg"',it)):
sp.append(it)
#获取图片链接并保存到本地
print("031804113")
for it in sp:
m = re.search(r'src="(.*?)"',it)
iturl = m.group(1) # 列出第一个括号匹配部分
print(iturl)
tag1 = iturl.replace("/", " ")
img = url + iturl
urllib.request.urlretrieve(img, 'D:/2020test/爬虫/picture/' + tag1)
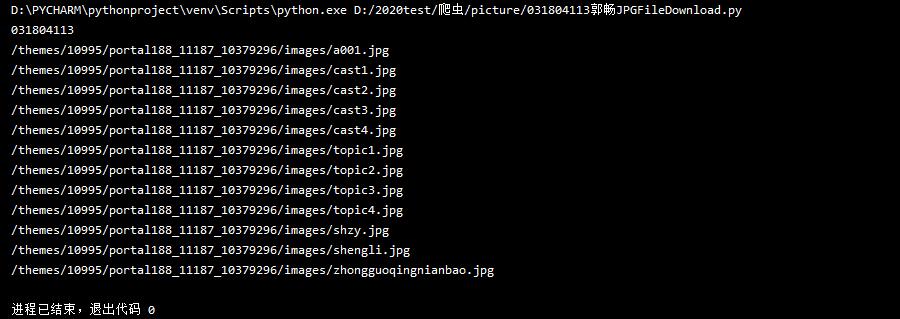
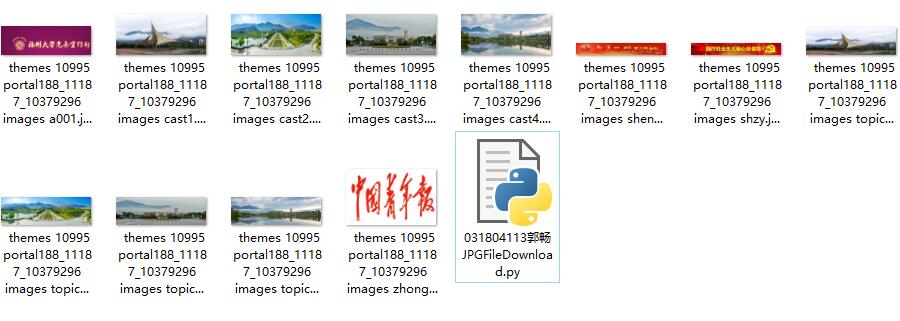
2)心得体会
这次爬取指定网页的所有jpg图片,有了前两次的收获,感觉会更加明朗
这次使用正则表达式一层一层进行筛选,最后获得图片的路径
在该网站的最后一行是其他网页的链接图片,没有进行爬取
这次没有使用函数,直接把代码写下来,看起来会散一些
这次任务最特殊的地方就是对图片地址的处理,以及将图片保存到本地
将图片保存到本地的代码感觉第一次接触知道了原理,还是是有意思的
。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号