Transformer轻量化大揭秘:计算机视觉如何实现极致加速?
近年来,Transformer 架构在计算机视觉(CV)领域的崛起推动了视觉模型的性能革命。从 ViT(Vision Transformer)到 Swin Transformer,再到各种混合卷积-Transformer 模型,Transformer 以其卓越的建模能力被广泛应用于图像分类、检测、分割等任务。然而,这种架构的高计算和内存开销也成为其大规模部署的一大障碍。
本文将系统梳理 Transformer 在 CV 中的轻量化与加速策略,帮助开发者理解当前主流方案的优势、局限与演进方向。
一、Transformer 在视觉任务中的瓶颈
传统 Transformer 模型(如 ViT)中的注意力机制为全连接自注意力(Global Self-Attention),其计算复杂度为:
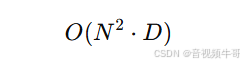
其中,N 为输入序列长度(图像分块后 patch 数),D 为特征维度。视觉任务中图像分辨率远高于 NLP 的 token 序列长度,因此当图像尺寸较大时,自注意力计算代价非常昂贵。此外,Transformer 模型对硬件缓存和并行性要求较高,也限制了其在边缘设备和移动端的部署。
二、轻量化与加速的主流策略
我们可以从以下五个方向系统性地总结视觉 Transformer 的优化策略:
1. 注意力机制优化
-
局部注意力(Local Attention)
如 Swin Transformer 引入窗口划分,限制注意力计算在局部区域(window)内,复杂度降低为线性:![]()
-
稀疏注意力(Sparse Attention)
如 Longformer、Linformer 等通过设置注意力 mask 或投影降维减少注意力连接,提升效率。 -
混合注意力(Hybrid Attention)
将局部+全局注意力结合,如 HaloNet、Focal Transformer 实现远近结合的建模策略。
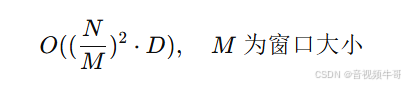
2. 结构剪枝与通道削减
-
Patch 数量削减:减少输入 patch 的数量,例如 MobileViT 使用可学习降采样。
-
Token 剪枝(Token Pruning):如 DynamicViT 通过训练出重要性评分,丢弃低重要性 patch。
-
通道剪枝(Channel Pruning):剪掉 transformer 层中对最终任务影响不大的通道。
这些策略能有效减少推理时的 FLOPs 与内存占用,适配小模型场景。
3. 低秩分解与矩阵近似
Transformer 中存在大量全连接层与矩阵乘操作,可采用:
-
Low-Rank Approximation:如 Linformer 将注意力矩阵近似为两个低秩矩阵乘积,显著降低计算成本。
-
Tensor Decomposition:如 Tucker、CP 分解等方式压缩 Q/K/V 权重张量。
4. 模型蒸馏与知识迁移
-
利用一个大型 teacher Transformer 模型训练轻量 student 模型,使得小模型学习其特征分布与注意力图;
-
如 DeiT(Data-efficient Image Transformer)在训练过程中引入 distillation token 以增强小模型表现。
这种方法虽然不会改变结构复杂度,但能在小模型中获取接近大模型的性能。
5. 硬件友好结构设计
-
替换 LayerNorm:将 LayerNorm 替换为更适合硬件优化的操作(如 RMSNorm、GroupNorm);
-
低精度量化(INT8/FP16):使用 TensorRT 或 ONNX Runtime 等引擎进行推理加速;
-
分组注意力(Grouped Attention):结合深度学习硬件如 NPU、GPU 特性设计 attention 格式。
这些策略可显著提升推理速度,特别适合部署于 ARM 芯片或嵌入式设备上。
三、典型轻量 Transformer 模型盘点
| 模型名称 | 核心优化策略 | 参数量 | 应用特点 |
|---|---|---|---|
| MobileViT | 卷积+小型Transformer融合 | <10M | 移动端部署、泛化能力强 |
| TinyViT | 高效设计+蒸馏 | <5M | 分类、检测、分割多任务 |
| LiteViT | Token 提取 + 稀疏注意力 | <4M | 视频帧分析、时空建模 |
| EfficientFormer | 重参数化结构 + CNN embedding | <6M | 兼容 CNN 加速平台 |
四、视觉 Transformer 的未来趋势
-
多模态协同轻量化:将图像与文本、语音等输入共同压缩建模,如 TinyCLIP。
-
统一架构泛化设计:使用同一套 Transformer 架构兼容多个视觉任务(Det、Seg、Track)。
-
自适应计算(Early Exit / Token Routing):根据输入复杂度动态选择计算路径,提升效率。
-
跨平台部署兼容性:面向 TensorRT、CoreML、NNAPI 等平台优化的 Transformer 加速库不断成熟。
五、结合大牛直播SDK等工业系统的落地思考
以大牛直播SDK为例,其在边缘计算、实时视频分析中的高性能要求,与轻量化 Transformer 模型可形成良好协同:
-
实时图像增强(画质增强、超分辨率)使用 MobileViT 等轻量模型提升流媒体体验;
-
在 RTSP/RTMP 推流过程中嵌入对象检测、动作识别等小型 Transformer;
-
将轻量 Transformer 模块与 GPU/OpenGL 渲染链路深度融合,实现解码-推理-渲染一体化。
这种“模型轻量化 + 解码渲染协同”架构将成为下一代智能视频系统的重要方向。
六、结语
Transformer 在视觉领域的轻量化与加速是一项系统工程,涵盖模型设计、结构优化、训练技巧与部署策略。随着硬件算力不断提升与模型优化技术的成熟,未来轻量 Transformer 将持续突破瓶颈,实现从云端到端侧的全面落地。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号