

Python × OpenCV × 大牛直播SDK:构建低延迟智能视频分析系统实战指南
在人工智能与计算机视觉技术迅猛发展的背景下,Python 与 OpenCV 已成为图像处理与智能分析领域的事实标准组合。凭借其开源、高效、易于集成等优势,这一组合被广泛应用于安防监控、工业质检、无人机巡检、智慧交通、医疗影像、机器人导航等多个关键场景,正在推动着传统行业向“智能化、自动化、实时化”转型。
然而,在实际工程部署中,一个长期存在的“断点”是:如何将实时视频流稳定、高效地接入到 Python + OpenCV 的处理链路中?
传统方式如使用摄像头采集、调用 ffmpeg 解码、使用 OpenCV 的 cv2.VideoCapture(),往往面临:
-
❌ 帧率不稳、延迟高;
-
❌ 不支持 RTSP/RTMP 等协议或兼容性差;
-
❌ 缺乏帧级精度控制和外部系统集成能力。
为了解决这一关键问题,本文引入 大牛直播SDK(Daniu Live SDK) ——一个专为高性能实时视频流接入设计的跨平台模块,支持 RTSP/RTMP 拉流、YUV/RGB 帧级回调、硬件解码与同步控制。它将作为**“视频入口层”**与 Python + OpenCV 的智能处理逻辑无缝衔接,构建出一个完整、可工程化部署的智能视觉分析链路。
RTMP|RTSP播放器回调RGB数据进行算法分析和二次推流
本文将围绕 “大牛直播SDK × Python × OpenCV” 这一组合,从架构设计、接口调用、图像处理实战到典型应用场景,全面介绍如何实现:
✅ 实时视频接入
✅ 高效图像分析
✅ 目标识别与追踪
✅ 数据回传与系统联动
帮助开发者在工业级项目中,真正打通从视频采集 → AI识别 → 智能响应的闭环,提升系统响应速度与智能化水平。
一、为何选择 “Python + OpenCV + 大牛直播SDK”?
在构建实时视频处理系统时,开发者通常面临以下三大核心挑战:
| 挑战 | 描述 |
|---|---|
| 🎥 视频接入不稳定 | 传统接口如 cv2.VideoCapture() 对网络 RTSP/RTMP 支持差、帧率抖动严重,难以满足工业级实时性要求 |
| 🧠 图像处理需高扩展性 | 图像分析逻辑需快速集成 AI 模型、OpenCV 算法,且要便于迭代与可视化调试 |
| ⚙️ 工程部署复杂 | 从视频采集到智能识别的流程需稳定、高效,并支持跨平台与系统对接能力 |
为此,“Python + OpenCV + 大牛直播SDK” 成为破解这一组合难题的理想技术路径:
✅ 1. Python:灵活、高效、AI生态丰富
-
快速开发,代码量小,开发周期短;
-
拥有庞大的图像处理、AI 推理库(如 OpenCV、PyTorch、TensorFlow);
-
易于与 C/C++ 底层模块交互,可作为系统集成的控制中枢。
✅ 2. OpenCV:工业级图像处理引擎
-
拥有强大的图像变换、边缘检测、目标跟踪、人脸识别等模块;
-
支持硬件加速(如 CUDA、OpenCL);
-
与视频帧处理无缝衔接,是构建图像分析逻辑的理想工具。
✅ 3. 大牛直播SDK:高性能视频通道组件
| 能力模块 | 描述 |
|---|---|
| 🎬 实时流媒体接入 | 支持 RTSP、RTMP、File、Camera 等多源拉流,帧率稳定、连接快速 |
| 🔄 YUV/RGB帧回调 | 支持精确帧级回调,零拷贝方式传递至 OpenCV/AI 模型 |
| 🚀 硬解加速与多平台 | 支持 GPU 硬解(如 NVDEC / MediaCodec),支持 Windows / Linux / Android / iOS |
| 🔗 跨模块集成 | 支持将图像结果反馈回 RTSP/RTMP 推流,构建闭环系统链路 |
✅ 大牛直播SDK弥补了 Python 与 OpenCV 在**“高性能视频采集与解码”**方面的短板,为实时视频感知系统构建了稳定、高效、可控的视频输入层。
📌 核心优势汇总表
| 模块 | 优势 | 作用 |
|---|---|---|
| Python | 快速开发、AI集成方便 | 控制逻辑、模型推理、数据输出 |
| OpenCV | 图像算法丰富、效率高 | 图像分析、特征提取、目标识别 |
| 大牛直播SDK | 流媒体稳定、支持帧回调 | 构建视频输入与接入管道 |
通过这一组合,开发者可以将来自摄像头、RTSP网络流或无人机图传的数据,高效接入 Python 环境,并立即进行图像分析与智能处理,为后续的预警、检测、识别、反馈等模块打下坚实基础。
二、基于大牛直播SDK构建高性能视频接入通道
在传统视频处理系统中,Python 端通常通过 cv2.VideoCapture() 或 ffmpeg 解码方式接入视频流。然而,在面对工业现场或智能分析场景时,这类方式常暴露出诸如连接不稳定、帧率抖动、延迟不可控、协议兼容差等问题。
为此,我们采用 大牛直播SDK 提供的 “YUV / RGB 回调 + 零拷贝共享” 机制,实现从 RTSP/RTMP 拉流 → 原始帧获取 → 高效送入 Python 环境的完整闭环。
✅ 2.1 架构总览
┌─────────────┐ RTSP/RTMP/FILE ┌───────────────┐
│ 摄像头 / IPC │ ───────────────────→ │ 大牛直播SDK播放器 │
└─────────────┘ └────┬────────────┘
│ 原始帧(YUV/RGB)回调
▼
┌──────────────────────────┐
│ Python + OpenCV层 │
│ - YUV转BGR处理 │
│ - 图像识别/检测 │
└──────────────────────────┘
⚙️ 2.2 常见像素格式说明(与 OpenCV 适配)
| 格式 | SDK支持 | OpenCV兼容性 | 是否需转换 |
|---|---|---|---|
| YUV420P | ✅ | 部分支持(需手动转换) | 是 |
| RGB24 | ✅ | ✅ 完美兼容 | 否 |
| NV12/NV21 | ✅ | ❌ OpenCV不直接支持 | 是(推荐转为 YUV420 或 RGB) |
🧩 小结
大牛直播SDK 为图像处理与 AI 识别系统提供了一个稳定、高性能、灵活可控的视频输入通道,远远优于传统的采集方式。通过其帧回调能力与 Python/OpenCV 的结合,开发者可以:
-
快速接入多种视频源;
-
精准控制每一帧数据处理;
-
与 AI 模型高效联动,构建完整的实时分析链路。
三、基于 OpenCV 与 AI 模型的图像识别实战
在完成了视频流的高性能接入后,下一步就是围绕图像帧开展智能分析任务。常见需求包括:
-
🔍 人脸识别 / 车牌识别(Haar / DNN / 深度模型)
-
🎯 目标检测(YOLOv5/YOLOv8)
-
🚶 多目标跟踪(DeepSort)
-
🚦 行为分析(站立、跌倒、越线)
本节将展示如何将从大牛直播SDK回调的视频帧数据,传入 OpenCV 与 AI 模型中进行处理,并实时输出识别结果。
✅ 3.1 框架流程图(视频感知链路)
┌──────────────┐
│ 大牛直播SDK │ ←──── 视频流拉取(RTSP / RTMP)
└────┬─────────┘
│ 帧级数据回调(YUV / RGB)
▼
┌──────────────────────────┐
│ Python 接收帧(共享内存 / Pipe) │
└────┬─────────────────────┘
▼
┌──────────────────────────┐
│ OpenCV + AI 模型(YOLO/Haar) │ ←──── 加载模型 & 预处理
└────┬─────────────────────┘
▼
┌──────────────────────────┐
│ 实时识别结果:目标框、类别、置信度 │ → 可用于报警、联动推流、后端存储
└──────────────────────────┘
🧩 小结
通过将 OpenCV + AI 模型 与 大牛直播SDK 获取的视频帧结合,开发者可以实现从低延迟采集到高精度识别的完整流程:
-
无需开发复杂采集系统,直接使用 SDK 获取每一帧;
-
利用 OpenCV / PyTorch / ONNX 等工具进行图像分析;
-
实现毫秒级的识别与响应,为工业智能注入“实时感知能力”。
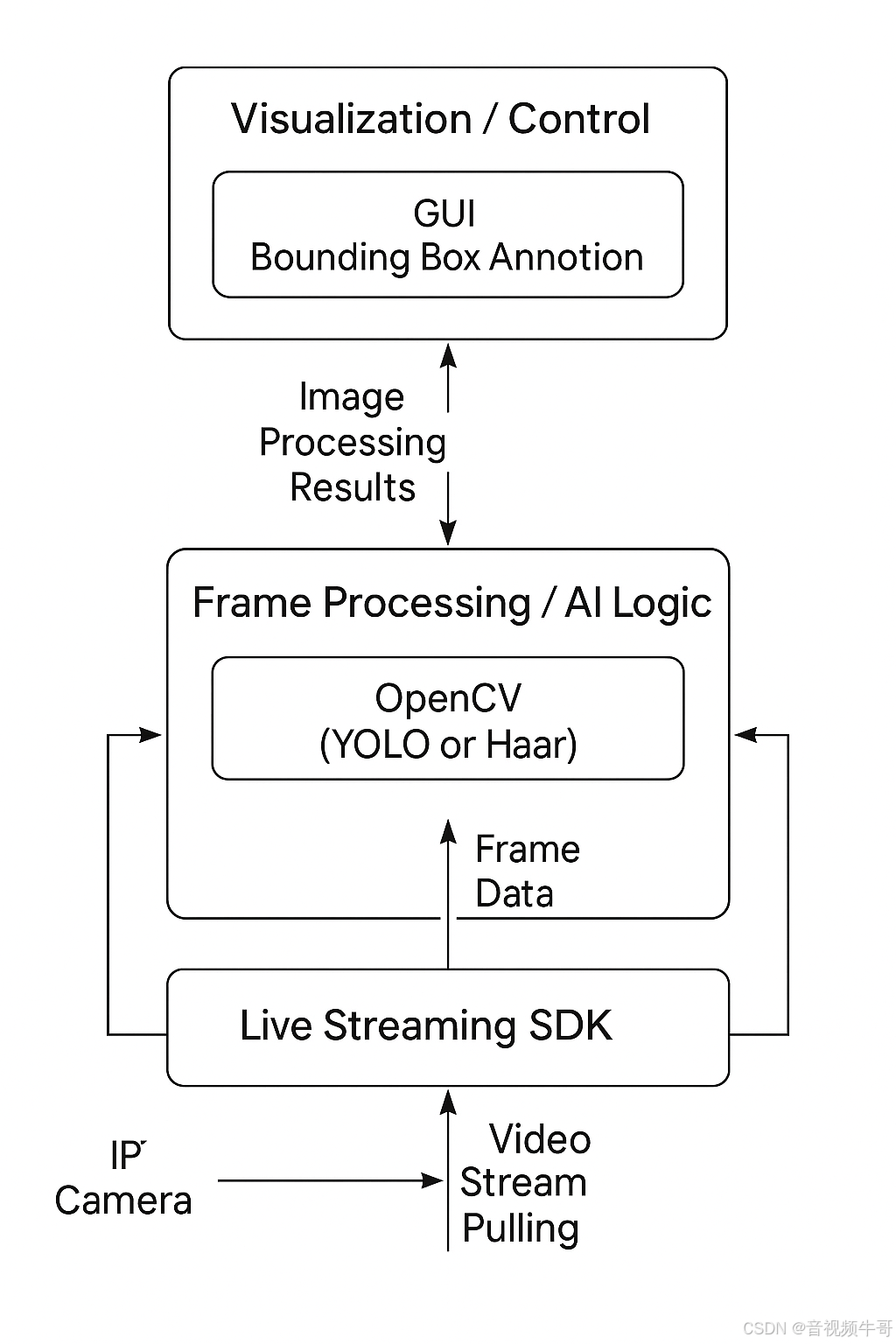
四、构建可部署的智能视频分析系统架构
当你完成了视频流采集、帧级图像处理与目标识别后,下一步便是将这些模块整合为一套工程级可部署系统,支撑实际项目中对可靠性、响应速度、界面交互与数据联动的高要求。
✅ 4.1 系统架构图(模块分层)
┌─────────────────────────────────────────────┐
│ 上层控制 / UI 层 │
│ - 实时画面展示(OpenCV窗口 / PyQt5 / WebUI) │
│ - 识别框标注 / 状态指示 / 报警按钮 │
└─────────────────────────────────────────────┘
▲
│ 图像处理结果、推理结果
▼
┌─────────────────────────────────────────────┐
│ Python 图像处理 / AI 逻辑层 │
│ - YUV/RGB 接收与解码 │
│ - OpenCV 图像预处理 │
│ - YOLO/ONNX 模型推理 │
│ - 多目标跟踪 / 状态识别 │
└─────────────────────────────────────────────┘
▲
│ 帧数据传输(ZeroMQ / Pipe / 共享内存)
▼
┌─────────────────────────────────────────────┐
│ 大牛直播SDK 视频采集层 │
│ - RTSP/RTMP拉流 │
│ - YUV/RGB 回调 │
│ - 视频元数据(分辨率/时间戳) │
└─────────────────────────────────────────────┘
🔄 4.2 跨进程/跨模块数据通信机制
为实现解耦与高并发,推荐以下几种跨模块通信方式:
| 通信方式 | 特点 | 适用场景 |
|---|---|---|
multiprocessing.Queue | 简单易用,进程安全 | 同一机器、轻量系统 |
共享内存 mmap | 高性能,零拷贝 | 大图像帧数据传输 |
ZeroMQ / nanomsg | 多平台支持,支持异步 | 多组件、分布式部署 |
WebSocket | 前端交互友好 | 推理结果实时推送前端 |
✅ 建议:将大牛SDK部分放在独立线程或子进程中运行,通过共享内存或消息队列传帧给 Python AI 模块,避免阻塞主逻辑。
五、典型落地案例解析:从技术组合到场景闭环
为了进一步理解“大牛直播SDK + Python + OpenCV + AI 模型”的实战价值,本节将通过多个行业技术方案,展示这一技术组合如何在真实场景中发挥作用,打通从实时采集 → 智能识别 → 数据联动的全流程。
🎯 案例一:目标检测 + 实时警报触发(安防监控)
✅ 场景描述
在厂区、仓库、边界围栏等敏感区域,通过 RTSP 摄像头实时监控,一旦检测到非法入侵(人/车),立即触发本地警告或上报云端安防平台。
🧱 技术链路
RTSP摄像头 → 大牛直播SDK拉流 → YOLOv5识别人形目标 → 置信度>0.8 → 调用报警接口(如 MQTT / HTTP)
📌 技术亮点
-
视频延迟 < 200ms;
-
实时叠加识别框,自动标注入侵时间;
-
可将图像与报警事件绑定存入 MongoDB / ElasticSearch。
💡 拓展能力
-
增加识别黑名单人脸比对;
-
结合声光报警设备联动。
🎥 案例二:多路视频接入 + 多目标跟踪(交通管控)
✅ 场景描述
城市路口部署多路摄像头,接入多个视频流,通过识别+跟踪算法对不同方向车辆、行人进行轨迹分析,用于车流统计与异常行为预警。
🧱 技术链路
多路RTSP视频流 → 多实例大牛SDK解码 → Python多线程处理 → YOLO + DeepSort 跟踪目标 → 实时展示轨迹+方向
📌 技术亮点
-
支持多路高分辨率流数据实时处理;
-
多目标持续跟踪 + 运动轨迹预测;
-
可输出 Excel / JSON 统计报表。
💡 拓展能力
-
配合 GIS 地图系统显示位置;
-
检测闯红灯 / 占道 / 逆行等行为。
🚁 案例三:远程巡检 + 图像标注上传(无人机/机器人)
✅ 场景描述
在电力巡线、园区安防、石油管道等场景中,部署无人机或机器人,搭载 RTMP 图传系统将现场图像实时推流,后台系统接收后进行 AI 分析与人工辅助标注。
🧱 技术链路
无人机RTMP图传 → 大牛直播SDK接入 → OpenCV + 目标检测 → 人工审阅界面(PyQt / Web) → 标注图像上传平台📌 技术亮点
-
支持帧级暂停、图像裁剪与标签标注;
-
标注结果自动关联 GPS 坐标、时间戳;
-
后端可统一存入对象存储(如 MinIO / OSS)。
💡 拓展能力
-
结合 Transformer 实现自动标注建议;
-
与调度系统对接,生成“巡检任务回执”。
🧪 案例四:工业缺陷检测 + 图像留档(生产线)
✅ 场景描述
在 SMT、钢板、瓶盖等生产线中,接入工业相机,对每一帧图像进行缺陷检测,检测到异常图像时自动截图、存储并发出报警。
🧱 技术链路
USB Camera / File输入 → 大牛SDK拉流(或 OpenCV采集) → 图像预处理 + CNN识别 → 存图 + 记录 + 本地声光反馈📌 技术亮点
-
工业相机 + 多线程图像分析处理;
-
支持图像编号、缺陷位置标注;
-
可接入企业 MES / ERP 系统。
🧩 小结:通用能力 × 多元落地
| 场景 | 采集方式 | 分析任务 | 反馈机制 |
|---|---|---|---|
| 安防监控 | RTSP 摄像头 | 入侵检测、人脸识别 | 实时报警、日志上传 |
| 交通分析 | 多路 NVR | 目标检测 + 跟踪 | UI轨迹展示、统计输出 |
| 智能巡检 | RTMP 图传 | 缺陷/事件检测 + 标注 | 云端上传、任务回执 |
| 工业检测 | USB/工业相机 | OCR / 缺陷识别 | 本地告警、系统对接 |
总结
通过以上典型案例可以看到,大牛直播SDK + Python + OpenCV + AI 模型构建的智能视频系统具备极高的适应性与工程可落地性。无论是单路实时识别,还是多路调度管理,都可通过模块化拼装完成部署:
-
具备 平台无关性(支持 Windows / Linux / 嵌入式);
-
实现 功能组合灵活(采集、识别、回传、显示);
-
满足 工业级实时性与稳定性要求(帧率稳定、延迟可控);
六、总结与展望:让每一帧视频都具备“智能决策力”
在智能视觉系统快速发展的时代背景下,从视频中获取高价值信息,已经成为安防、工业、交通、巡检等领域的核心诉求。
通过本篇文章,我们以“大牛直播SDK + Python + OpenCV + AI 模型”为主线,系统展示了一条完整的智能视频分析工作流:
| 能力层 | 技术实现 | 说明 |
|---|---|---|
| 视频采集层 | 大牛直播SDK | 支持 RTSP/RTMP/本地流,低延迟、高稳定 |
| 帧级回调层 | RGB/YUV 输出 | 精准对接 Python/AI 模型,毫秒级响应 |
| 图像分析层 | OpenCV + YOLO/Haar | 支持人脸识别、目标检测、行为分析等 |
| 数据联动层 | HTTP/MQTT/Webhook | 实现报警、可视化、系统联动反馈 |
| 系统部署层 | 多进程/共享内存/Web UI | 适配边缘/本地/云端多种部署方式 |
这一组合不仅具备高实时性、高扩展性,更具备工程可落地性,为开发者打造“采→识→用”的智能通路提供了坚实底座。
🔭 展望未来:更强的融合、更广的落地
随着 Transformer、YOLO-NAS、SAM 等新一代模型的普及,以及工业端对实时性和安全合规要求的不断提升,未来的智能视频系统将朝着:
-
更低延迟的数据通道(如 GPU 直通渲染)
-
更强大的模型压缩部署(如 ONNX + TensorRT)
-
更智能的联动反馈机制(事件流、自动决策)
-
更开放的边云协同结构(微服务+MQ流转)
演进升级。
而大牛直播SDK + Python 架构,正好处于“连接视觉数据与智能决策”的关键接口位置,适合作为 AI 视频系统的通用感知入口。
🔧 推荐开源工具与框架
| 名称 | 说明 | 地址 |
|---|---|---|
| OpenCV | 图像处理与视觉分析核心库 | https://opencv.org |
| PyTorch | AI模型推理与训练框架 | https://pytorch.org |
| YOLOv5/v8 | 通用目标检测框架 | https://github.com/ultralytics/yolov5 |
| ONNX + TensorRT | 高性能模型部署优化 | https://onnx.ai / https://developer.nvidia.com/tensorrt |
| FastAPI + WebSocket | 实时数据服务 + UI推送 | https://fastapi.tiangolo.com |
| ZeroMQ / Nanomsg | 高效进程间通信 | https://zeromq.org |
📎 CSDN官方博客:音视频牛哥-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号