24.12.05
实验二:逻辑回归算法实现与测试
一、实验目的
深入理解对数几率回归(即逻辑回归的)的算法原理,能够使用Python语言实现对数 几率回归的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注 意同分布取样);
(2)使用训练集训练对数几率回归(逻辑回归)分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选 择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验二的 部分。
三、算法步骤、代码、及结果
1. 算法伪代码
1. 加载数据集 (例如,iris 数据集)
- 特征:X
- 标签:y
2. 拆分数据集为训练集和测试集
- 使用留出法 (例如,训练集占 2/3,测试集占 1/3)
- 使用随机种子确保结果可复现
3. 初始化逻辑回归模型
- 设置参数:最大迭代次数 (max_iter),正则化强度 (C),求解算法 (solver)
4. 在训练集上训练逻辑回归模型
- 使用训练数据 X_train 和标签 y_train
5. 进行五折交叉验证 (5-fold cross-validation)
- 对训练集进行划分
- 对每个折,训练模型并计算评估指标 (例如,准确度)
- 记录每一折的评估结果
6. 计算交叉验证的平均评估结果
- 计算准确度、精度、召回率和 F1 分数的平均值
7. 在测试集上进行预测
- 使用训练好的模型预测测试集 X_test 的标签
8. 计算测试集上的评估指标
- 准确度 (Accuracy)
- 精度 (Precision)
- 召回率 (Recall)
- F1 分数 (F1 Score)
9. 输出交叉验证结果和测试集评估结果
- 显示模型的性能
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 加载 iris 数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集拆分为训练集和测试集,测试集占 1/3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
# 初始化逻辑回归模型,设置最大迭代次数和求解算法
model = LogisticRegression(max_iter=200, solver='lbfgs', C=1.0)
# 训练模型
model.fit(X_train, y_train)
# 使用交叉验证计算准确度
cross_val_results = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
print(f'Cross-Validation Accuracy: {cross_val_results.mean()}')
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确度、精度、召回率和 F1 分数
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
print(f'Test Accuracy: {accuracy}')
print(f'Test Precision: {precision}')
print(f'Test Recall: {recall}')
print(f'Test F1 Score: {f1}')
函数参数说明: class sklearn.linear_model.LogisticRegression(
penalty='l2',
dual=False,
tol=0.0001,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver='lbfgs',
max_iter=100,
multi_class='auto',
verbose=0,
warm_start=False,
n_jobs=None,
l1_ratio=None
)
参数说明:
- penalty(默认值:
'l2'):指定正则化方式,可以选择'l2'(岭回归)或'l1'(lasso回归)。默认选择'l2'。 - dual(默认值:
False):选择对偶问题或原始问题,通常在solver='liblinear'时使用对偶问题。一般不需要更改。 - tol(默认值:
0.0001):优化的停止条件,控制算法收敛的精度。 - C(默认值:
1.0):正则化的强度。C值越小,正则化越强;值越大,正则化越弱。 - fit_intercept(默认值:
True):是否计算截距。如果设置为False,模型不考虑截距项。 - intercept_scaling(默认值:
1):仅在solver='liblinear'时使用,设置截距的缩放因子。 - class_weight(默认值:
None):类别的权重。可以设为balanced,或者提供一个字典来为每个类别设置权重。 - random_state(默认值:
None):随机种子,用于控制随机性的复现。 - solver(默认值:
'lbfgs'):优化算法的选择。常见的有: 'liblinear':适用于小数据集和L1正则化。'newton-cg','lbfgs':适用于L2正则化。'saga':支持大规模数据集和L1正则化。- max_iter(默认值:
100):最大迭代次数。如果模型没有在该次数内收敛,可能需要增加此参数。 - multi_class(默认值:
'auto'):控制多类分类的策略。'ovr'是一对多,'multinomial'是多项式逻辑回归,自动选择基于solver。 - verbose(默认值:
0):控制日志的详细程度。 - warm_start(默认值:
False):是否复用上次拟合的模型结果,适用于增量学习。 - n_jobs(默认值:
None):使用的CPU核心数。如果为None,则使用一个核心;设置为-1使用所有核心。 - l1_ratio(默认值:
None):用于弹性网正则化时的 L1 和 L2 正则化的比例。solver='saga'时才会生效。
sklearn.model_selection.cross_val_score(
estimator,
X,
y=None,
groups=None,
scoring=None,
cv=None,
n_jobs=None,
verbose=0,
fit_params=None,
return_train_score=False
)
参数说明:
- estimator:模型或估算器,通常是已初始化的学习算法对象(如
LogisticRegression)。 - X:训练数据,通常为一个二维数组或矩阵(形状为
[n_samples, n_features])。 - y:目标值(标签)。如果进行无监督学习,可以设置为
None。 - groups:用于分组的标签,仅在某些情况下使用,例如分层 K-fold 交叉验证。
- scoring:评估指标。可以是字符串类型的指标名称,如
'accuracy','precision','recall','f1',也可以是自定义的评分函数。 - cv(默认值:
None):交叉验证的折数。可以设置为k-fold的整数值,或者使用StratifiedKFold等交叉验证器。 - n_jobs(默认值:
None):并行运行的作业数。None表示不并行,-1表示使用所有处理器。 - verbose(默认值:
0):控制日志详细程度。 - fit_params(默认值:
None):拟合模型时的额外参数,通常不需要设置。 - return_train_score(默认值:
False):是否返回训练集的评分。设置为True时,返回训练集的准确度或其他评估指标。
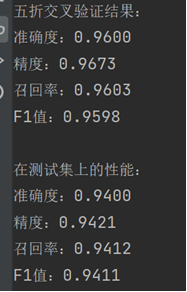
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
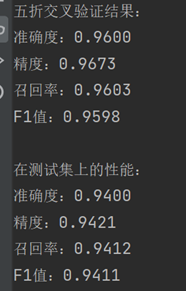
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
2. 对比分析
准确度(Accuracy):
五折交叉验证:0.9600
测试集:0.9400
分析:准确度略有下降,从训练数据的 96% 降到测试数据的 94%。虽然存在一些下降,但差距不大,表明模型在测试集上依然能够保持较高的准确性。这是可以接受的,因为模型在训练数据上可能存在一些过拟合,测试集的准确度通常略低。
精度(Precision):
五折交叉验证:0.9673
测试集:0.9421
分析:精度从 96.73% 降到了 94.21%。精度指标度量的是模型正确预测的正样本占所有预测为正样本的比例。精度略有下降,但差距并不大,说明模型预测为正样本的准确性在测试集上稍有减少,可能是因为测试集的正类样本有所不同。
召回率(Recall):
五折交叉验证:0.9603
测试集:0.9412
分析:召回率从 96.03% 降到 94.12%。召回率衡量的是所有正样本中被正确识别的比例。与精度类似,召回率在测试集上也有轻微的下降。这意味着模型对正类样本的捕获能力略有下降,可能是测试集上存在一些“难以识别”的正类样本。
F1值:
五折交叉验证:0.9598
测试集:0.9411
分析:F1值从 95.98% 降到了 94.11%。F1值是精度和召回率的调和平均值,它综合了这两个指标。F1值的略微下降表明,模型在测试集上总体的分类性能稍有下降。虽然差距不大,但还是表明测试集数据对模型稍具挑战性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号