阅读论文笔记5-10
《一种利用差集的加权频繁项集挖掘算法 》提出了在研究概念格模型和差集 Diffsets 理论的基础上,构建一种利用差集的加权频繁项集格结构,该格结构通过差集性质快速计算加权支持度,满足向下封闭特性,更有利于高效生成加权频繁项集.。该方法能显著提高生成加权频繁项集的效率。
关联规则的挖掘是数据挖掘研究的重要内容之一,传统的关联挖掘算法往往忽略数据库中各个项目集的重要程度,因此,在实际分析数据时,利用加权关联规则是有意义的,它能发现那些出现频率较低但权值比较大的重要频繁项集.加权关联规则挖掘算法的总体性能主要由生成加权频繁项集的效率决定。文章提出一种新的加权频繁项集概念格结构,通过引入差集的概念和性质,在一定程度上缓解了加权支持度计算时间长的问题。差集运算过程中根据加权支持度的值进行升序排序,进一步减少了加权频繁项集格建立过程中的计算量。分析与实例表明,文章提出的算法仅扫描数据库一次,无需生成候选加权项集,差集运算的使用加快了算法的收敛速度。
1、加权事务数据库
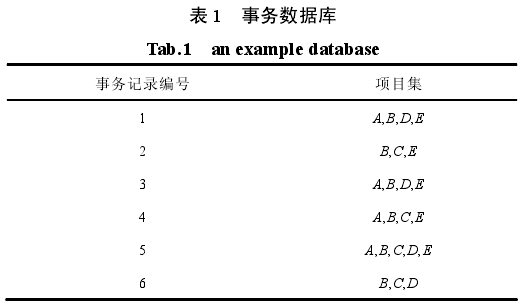
加权事务数据库 D={t1,t2,…,tk},式中,tj 为 D中的第 j 个记录;tj为项目属性的集合.项目属性集I={i1,i2,…,ik}由 k 个不同项目属性组成的集合,其中,每个项目属性 ij中都包含一个代表此项的重要程度非负实数的权值 w(j),0≤w( j)≤1. t(X)代表在事务数据库 D 中包含项目集 X 的记录集。例:表 1 中包含 5 个项目属性 I={A,B,C,D,E}的 6 条记录 D={t1,t2,…,t6},表 2 为每个项目属性所对应的权值 W={0.6,0.1,0.3,0.9,0.2}.

2、加权模型
定义4 事务数据库中记录tk的权tw(tk)指数据库D记录tk中各项目权重的平均值,即 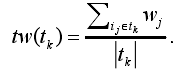
定义5 项集的权值ws(X)是事务数据库D中包含该项目的事务项集权值的汇总,即为 
例:根据表1、表2与定义4,计算交易事务项t1的权tw(t1)=0.45。表3为计算出表1的事务数据库D中所有事务项的权tw.

例:根据表1、表3与定义5,计算项集BD的权值ws(BD)=0.78 。
3、FWIL 数据结构
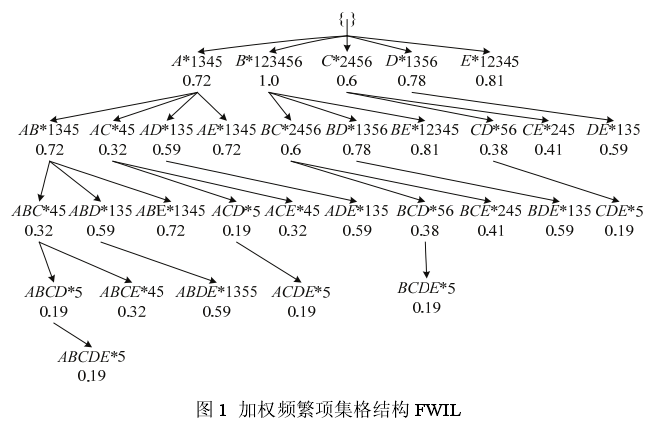
文章给出一种新的更有利于加权频繁项集提取的FWIL(Weighted Frequent Itemset Lattice)格结构,FWIL结构生成仅需扫描事务数据库一次,格结构中每一个结点定义为三元组Node(X,t(X),ws(X))表示,式中,X为事务数据库中包含的项目集;t(X) 为包含项目集X的记录构成的集合;ws(X) 为项目集X的加权支持度。例如下图:
4、利用差集生成加权频繁项集格
差集:
定义7 :假设两个项目集PX与PY是以P为前缀的等价类,PXY的差集d(PXY)=t(PX)-t(PY)。
定理 2 :已知两个项目集 PX、PY 与 d(PX)、d(PY),根据定义 7,易证明出 d(PXY)=d(PX)-d(PY) 。
定理 3 : 根据定义 7 与定理 2,通过 d(PXY)的值可以计算出 ws(PXY).公式为 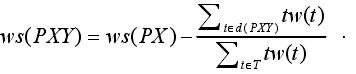
定理 4 : 如果 d(PXY)=∅,则 ws(PXY)= ws(PX) 。
基于差集diffsets的加权频繁项集格FWIL挖掘算法,不需要反复生成、验证候选项集,仅需扫描数据库一次,通过建立一个加权频繁项集格,将发现长频繁项集的问题转化为递归的发现一些有相同前缀的短项集,通过链接短项集的后缀来减少系统搜索开销,节约内存空间.此外通过diffsets差集的引入,可以通过定理3、定理4快速计算出新结点的加权支持度。基于diffsets差集的加权频繁项集格生成算法包括3个步骤:
(1)计算项目的加权支持度ws,对项目集依照ws值升序排序;
(2)对项目集结点进行链接,通过diffsets差集计算新结点ws值,从而构建加权频繁项集格;
(3)遍历FWIL格中所有结点,导出加权频繁项集(Weighted Frequent Itemsets,FWI).利用差集的加权频繁项集格FWIL-Diffsets构造算法;
例:以表 1、表 3 数据为例,根据上述介绍 FWIL- Diffsets()算法的实现步骤,假设 wminsup=0.4,格建立过程见图 2。

在构建 FWIL 格的过程中,计算每一个结点项目集所对应的加权支持度是相当耗时的工作,本文利用差集 Diffsets 的概念及其定理,达到简化计算加权支持度的过程.算法满足向下加权封闭性.通过存储 diffsets 代替存储完整的项目集也节省了大量存储空间.FWIL-Diffset()算法在加权支持度 ws 运算过程中根据 ws 的数目进行递增排序,进一步减少挖掘过程中计算 diffsets 的中间结果数量。文章利用已有的加权模型,提出了一种新的挖掘加权频繁项集的方法,该方法提出了构建新的概念加权频繁项集格FWIL,同时给出了相应的FWIL-Diff构造算法和在其上的FWI提取方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号