阅读论文笔记
《垂直数据格式挖掘频繁项集算法的改进》提出了一种基于三角矩阵和差集的垂直数据格式挖掘频繁项集的挖掘算法。该算法利用差集解决了对稠密数据集进行频繁项集挖掘时的 tid集可能很大的问题,并且利用一种前提方法判断是否有必要连接产生候选频繁k+1项集,减少时间的开销,而且在存储上用三角矩阵的数据结构可以进一步节省存储空间。
垂直数据格式算法分析该算法执行整个过程中只扫描一次数据库,采用垂直格式明显比Apriori的水平格式在时间效率上有很好的优越性,节省了多次扫描数据库的时间开销。但还存在一些不足:(1)若有 1000个频繁1-项集就会做50000次连接运算,而且在做连接运算之前回溯判断所有的候选集,都会增加时间的开销。(2)对于长模式的 tid 集,对内存的开销无可厚非是个瓶颈,而且两项相交比较的次数也会增加时间的开销。因此,针对以上的不足,该文提出了采用差集代替交集,提前判断是否有必要做连接运算而不必浏览侯选集的每个子集,并且利用三角矩阵的数据结构存储,减少算法执行的时间,降低内存的开销。
差集:在挖掘频繁项集时,通过取频繁k-项集的交,生成对应(k+1)-项集。唯一的不足是 tid集可能很大。为了进一步降低存储 tid 集合的开销,使用一种称为差集(diffset)的技术,仅记录(k+1)项集的tid 集与一个对应的k项集的tid集之差。例如,表 1 中,{I1}= {T1,T4,T5,T7,T8,T9}和{I1,I2}={T1,T4,T8,T9}。两者的差集diffset({I1,I2},{I1})={T5,T7}。这样不必记录构成{I1}和{I2}交集的4个 tid,可以使用差集只记录代表{I1}和{I1,I2}差集的两个tid,既减少了存储 tid 集的存储空间,又节约了原算法对 tid 集求交的时间。在某些情况下,对于稠密数据集,该技术可以显著地降低频繁项集垂直格式挖掘的总开销。
文章改进算法步骤:
(1)扫描数据库D,生成垂直数据格式;
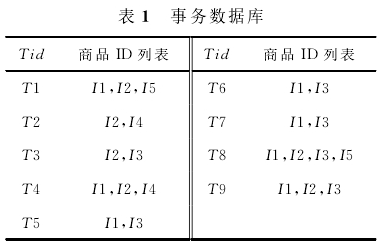 ====>
====> 
(2)构建三角矩阵M,矩阵M中的元素M[k]记录了任意两项之间tid差集元素的个数,如图所示,都大于最小支持度,并生成候选频繁2-项集;
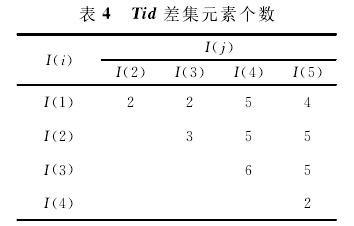
(3)利用差集性质二(diffset(I(K+1),I(K))差集为频繁(k+1)项集与频繁k项集支持度计数之差),得到候选频繁项集支持度计数,从而得到频繁2项集L2,L2={{I(1),I(2)},{I(1),I(3)},{I(1),I(5)},{I(2),I(3)},{I(2),I(4)},{I(2),I(5)}}。

(4)在{I(1),I(2)},{I(1),I(3)}连接之前利用相关性质 判断是否有必要连接,因为I(1),I(2)},{I(1),I(3)}都是频繁2-项集,所以只判断{I(2),I(3)}是否为频繁2-项集即可,从表5可以得出{I(2),I(3)}的支持度计数为4>2,所以可以连接。同理得到候选频繁3-项集L3= {{I(1),I(2),I(3)},{I(1),I(2),I(5)}}。
(5)因为{I(3),I(5)}的支持度计数=1<2,无候选频繁4项集,算法终止。
文章分析了目前基于垂直数据格式算法存在的缺点,提出了改进的算法,该算法引入差集弥补稠密数据集tid集很大的缺陷,用三角矩阵的存储结构和前提方法方便了剪枝与判断是否连接,通过实验对比与分析表明,该算法的执行效率和在内存空间占用上比原算法都有改善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号