ELMO,BERT, GPT小记
ELMO BERT GPT
ELMO
ELMo首先想到了在预训练阶段为每个词汇集齐上下文信息,使用的是基于bi-LSTM的语言模型给词向量带上上下文语义信息:
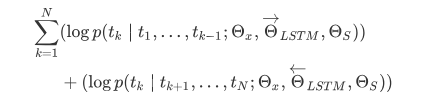
但ELMo使用的是RNN来完成语言模型的预训练,那么如何使用Transformer来完成预训练呢?
GPT
GPT(Generative Pre-Training),是OpenAI在2018年提出的模型,利用Transformer模型来解决各种自然语言问题,例如分类、推理、问答、相似度等应用的模型。GPT采用了Pre-training + Fine-tuning的训练模式,使得大量无标记的数据得以利用,大大提高了这些问题的效果。
GPT-1
GPT就是利用Transformer进行自然语言各种任务的尝试之一,主要有以下三个要点:
- Pre-Training的方式
- 单向Transformer模型
- Fine-Tuning与不同输入数据结构的变化
ELMo使用的是LSTM来完成语言模型的预训练,GPT使用单向的Transformer来完成预训练。
第一步:单向Transformer模型完成预训练任务:在Transformer中,提到了Encoder与Decoder使用的Transformer Block是不同的。在Decoder Block中,使用了Masked Self-Attention,即句子中的每个词,都只能对包括自己在内的前面所有词进行Attention,这就是单向Transformer。GPT使用的Transformer结构就是将Encoder中的Self-Attention替换成了Masked Self-Attention。
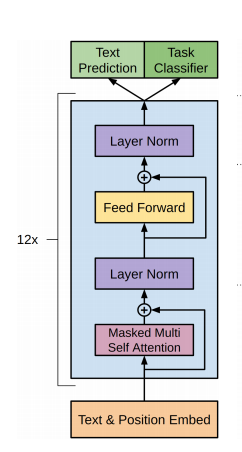
由于采用的是单向的Transformer,只能看到上文的词,所以语言模型:
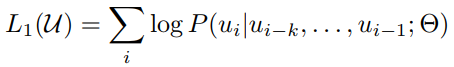
而训练的过程其实非常的简单,就是将句子n个词的词向量(第一个为

由于使用了Masked Self-Attention,所以每个位置的词都不会“看见”后面的词,也就是预测的时候是看不见“答案”的,保证了模型的合理性,这也是为什么OpenAI采用了单向Transformer的原因。
第二步,运用少量的带标签数据对模型参数进行微调。上一步中最后一个词的输出我们没有用到,在这一步中就要使用这一个输出来作为下游监督学习的输入。

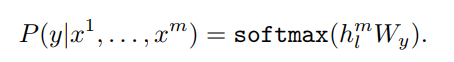
针对不同任务,需要修改输入数据的格式:

- Classification:对于分类问题,不需要做什么修改
- Entailment:对于推理问题,可以将先验与假设使用一个分隔符分开
- Similarity:对于相似度问题,由于模型是单向的,但相似度与顺序无关。所以需要将两个句子顺序颠倒后两次输入的结果相加来做最后的推测
- Multiple Choice:对于问答问题,则是将上下文、问题放在一起与答案分隔开,然后进行预测
GPT-1存在问题:
- 每个任务fine-tune的模型不通用;
- 每个任务都要有下游数据进行fine-tune;
GPT-2
GPT-2 可以处理最长 1024 个单词的序列。每个单词都会和它的前续路径一起「流过」所有的解码器模块。
GPT-2的transformer encoder block个数从12向24,36,48依次增长;model dimension从768向1024,1280,1600依次增长;参数增至15亿之多。
GPT-2问题:生成文本带有偏见
GPT-2 Chinese项目:https://github.com/Morizeyao/GPT2-Chinese
GPT API:https://talktotransformer.com/
GPT API:https://gpt2.ai-demo.xyz/
GPT生成接口:https://transformer.huggingface.co/doc/gpt2-large
Universal Adversarial Triggers for Attacking and Analyzing NLP, EMNLP2019
GPT-3
增加了更多的训练数据,没有很大创新:通过累加训练数据,希望模型越来越像人脑,去规避一些偏见、缺陷。
GPT-3问题:生成文本带有偏见
应用:14 Cool Apps Built on OpenAI's GPT-3 API
GPT系统总结
GPT想要应用一个语言模型解决所有NLP问题。通过大数据大模型来预训练抽取更大的语言学特征,对下游任务的特征进行补充,边界在哪儿。
BERT
BERT与GPT非常的相似,都是基于Transformer的二阶段训练模型,都分为Pre-Training与Fine-Tuning两个阶段,都在Pre-Training阶段无监督地训练出一个可通用的Transformer模型,然后在Fine-Tuning阶段对这个模型中的参数进行微调,使之能够适应不同的下游任务。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号