Beam Search 及5种优化方法
Beam Search 及5种优化方法
1. Review Beam Search
参考:吴恩达 深度学习 笔记 Course 5 Week 3 Sequence Models
回顾beam search:
对greedy search进行了改进:扩大搜索空间,更容易得到全局最优解。beam search包含一个参数beam width \(B\),表示每个时间步保留得分最高的B个序列,然后下一时间步用这\(B\)个候选序列继续生成。
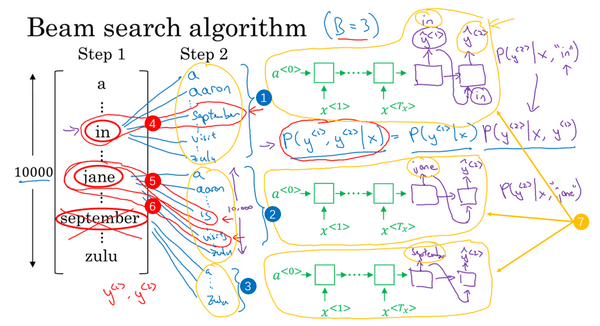

在sequence models中,input text \(\{x^{<1>},\dots,x^{<T_x>}\}\)输入Encoder,再通过Decoder,softmax层会输出词表大小\(|V|\)个输出概率值。
Beam Search的步骤:
- 找到第一个输出的概率值\(P(y^{<1>}|x)\),取最大的前\(B\)个单词保存。
- 分别计算前面\(B\)种情况下的Decoder输出\(P(y^{<2>}|x,y^{<1>})\),将会有\(B\cdot|V|\)个结果,最大化整个句子的概率\(P(y^{<1>},y^{<2>}|x)=P(y^{<1>}|x)P(y^{<2>}|x,y^{<1>})\),即第一个、第二个词对有最大的概率,从中选择概率最高的\(B\)个结果并保存。
- 每一步都有\(B\)个网络副本,来评估下一个单词的概率。继续计算并选择,直到出现句尾符号
<EOS>。
吴恩达的Andrew Ng的Coursera深度学习课程中提出了Beam Search的Refinement,如下面Normalization的第一部分。
Beam Search的优化方法有几类:
- Hypothesis filtering:对生成的候选序列进行过滤。
- Normalization:针对Beam Search得分函数的改进。
- Decoding with auxiliary language model:利用辅助语言模型改进decoder。
- Decoding with lexical constraints:添加对单词或短语的限制,decoder生成时需要参照限制词表。
- Search algorithms:优化搜索策略,寻找更高效的算法。
2. Beam Search Refinement
2.1 Hypothesis filtering
可以通过控制 (unkown words) 数量来对 beam search 生成的 hypotheses 进行 filtering. 当一个 hypothese 包含太多 时可以将其 drop 掉。需要注意的是,drop hypotheses 会暂时降低 beam size。
2.2 Normalization
主要是对beam search的得分函数进行改进,包括对输出句子的长度和coverage添加惩罚。
2.2.1 Length Normalization
参考:吴恩达 深度学习 笔记 Course 5 Week 3 Sequence Models
Beam Search 要最大化的概率\(P(y^{<1>},\dots,y^{<T_y>}|X)\),即衡量整个句子的概率,可以表示成条件概率的乘积:

因为每个条件概率都是小于1,多个小于1的数值相乘,会造成数值下隘(numerical underflow)。数值太小,导致电脑的浮点表示不能精确地存储,所以实践中不能最大化这个乘积,而是取\(log\)值。
最大化\(logP(y|x)\)求和的概率值,数值更稳定,不容易出现数值误差(rounding errors)或数值下溢。因为对数函数(\(log\)函数)是严格单调递增的函数,最大化\(logP(y|x)\)和最大化\(P(y|x)\)是等价的。实际工作中,我们总是记录概率的对数和(the sum of logs of the probabilities),而不是概率的乘积(the production of probabilities)。
总结对beam search的目标函数的改进:
- 对于beam search的原始目标函数
如果一个句子很长,那么这个句子的概率会很低,因为多个小于1的数字相乘得到一个更小的概率值。这个目标函数会倾向于短的输出,因为短句子的概率由更少数的小于1的数字乘积得到。
- 对于改进后的beam search的目标函数
每个概率\(P(y|x)\in(0,1]\),而\(log P(y|x)\)是负数。如果句子很长,加起来的项很多,结果越为负。所以这个目标函数也会影响较长的输出,因为长句子一直累加目标函数的值会十分小。
- 改进beam search:引入归一化,降低输出长句子的惩罚。
\(\alpha\in [0,1]\)是一个超参数,一般取\(\alpha=0.7\)。取值是试探性的,可以尝试不同的值,看哪一个能得到最好的结果。
- \(\alpha=0\),不归一化。
- \(\alpha=1\),标准的长度归一化。
在Beam Search最后使用上式选择一个最优的句子。

如何选择\(B\)?
- \(B\)越大(10~100),考虑的情况越多,得到更好的结果,计算量越大,速度越慢。
- \(B\)取小(1~10),得到的结果可能不够好,计算速度快。
- 一般选择\(B=10\)。
Beam Search与DFS/BFS不同,是近似搜索算法/启发式算法,不是找全局最优,而是找局部最优。
在实际项目中,如何发现是RNN模型出了问题,还是Beam Search出了问题?
增加\(B\)一般不会影响模型,就像增加数据集。


Beam Search中的误差分析:
在翻译任务中,\(y^*\)表示人工翻译结果,\(\hat{y}\)表示算法结果。
用RNN模型计算\(P(y^*|x)\)和\(P(\hat{y}|x)\),即比较期望值概率和输出概率的大小,来发现是RNN还是Beam Search的问题。
-
第一种情况:\(P(y^*|x)>P(\hat{y}|x)\),Beam Search出错。
期望值概率更高,但是Beam Search没有选择期望值,是Beam Search的问题,可以通过增加B来改善。
-
第二种情况:\(P(y^*|x)\le P(\hat{y}|x)\),RNN模型出错,需要在RNN模型上花更多时间。
RNN模型给出了错误的概率\(P(y^*|x)\),给一个好的句子小的概率。可以通过正则化,更大的训练数据,不同的网络结构等方法改进。
如果使用长度归一化,则需要用归一化后的值来判断。
误差分析过程如下图所示,先遍历development set,找出算法产生的错误。例如,\(P(y^*|x)=2\times 10^{-10}, P(\hat{y}|x)=1\times 10^{-10}\),属于第一种情况,Beam Search出错。后面依次标注错误类型,通过这个误差分析过程,得出Beam Search和RNN模型出错的比例是多少。如果发现Beam Search造成大部分错误,可以增大beam width。相反,如果发现RNN模型造成更多错误,可以进行更深层次的分析:是否需要增加正则化、获得更多训练数据、尝试一个不同的网络结构或其他方案。

2.2.2 Coverage Normalization
论文1:Coverage-based Neural Machine Translation
论文2:Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation
这里将Beam Search 的目标函数称为Beam Search得分函数score。采用对数似然作为得分函数,如下所示,Beam Search会倾向于更短的序列。引入length normalization对长度进行归一化可以解决这一问题。
2016年华为诺亚方舟实验室的论文1提到,机器翻译的时候会存在over translation or undertranslation due to attention coverage 。作者提出了coverage-based atttention机制来解决coverage 问题。
Google’s Neural Machine Translation System 的论文2<7. Decoder>提出了 length normalization 和 coverage penalty。coverage penalty 主要用于使用 Attention 的场合,通过 coverage penalty 可以让 Decoder 均匀地关注于输入序列 x 的每一个 token,防止一些 token 获得过多的 Attention。
论文2把对数似然、length normalization 和 coverage penalty 结合在一起,可以得到新的beam search得分函数,如下面的公式所示,其中\(X\)是source,\(Y\)是当前target, \(lp\) 是 length normalization,\(cp\) 是 coverage penalty,\(p_{i,j}\)是第\(j\)个target对应第\(i\)个输入的Attention值。超参数\(\alpha\)和\(\beta\)分别控制length normalization 和 coverage penalty。如果\(\alpha=0 \;\& \;\beta=0\),Decoder就退回普通的Beam Search。
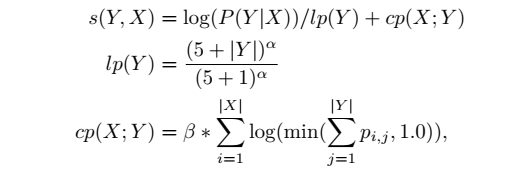
2.2.3 End of sentence Normalization
参考:Beam search
有时Decoder生成序列很难停止,此时需要对最大生成长度进行控制,可以采用下面的公式进行约束:
其中 \(|X|\)是source的长度,\(|Y|\)是当前target的长度,\(\gamma\)是End of sentence normalization的系数。那么由上式可知,target长度越长的话,上述得分越低,这样就会防止出现生成序列不停止的情况。
对于得分函数的改进方法,还有很多,例如有论文《 A Diversity-Promoting Objective Function for Neural Conversation Models》采用最大化互信息MMI(Maximum Mutual Information)作为目标函数,也可以作为Beam Search的得分函数。
2.3 Decoding with auxiliary language model
Beam search 还可以利用一个辅助的 language model 来定义 score function, 例如 “Shallow Fusion”:
其中\(s_{LM}(Y)\)是输出序列\(Y\)的语言模型\(LM\)的对数概率,\(\beta\)是一个超参数。需要注意的是语言模型\(LM\)不能使用双向RNN,需要与翻译模型$TM $共享相同的词汇表(标记和特征)。
2.4 Decoding with lexical constraints
添加词表的限制,使得beam search只要在输入端找到对应的source token,那就限制词语或短语的生成。在论文Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search中描述了Grid Beam Search方法,接受简单的one-token constraints。
2.5 Search algorithms
论文《Best-First Beam Search》关注于提升 Beam Search 的搜索效率,提出了 Best-First Beam Search 算法,Best-First Beam Search 可以在更短时间内得到和 标准Beam Search 相同的搜索结果。论文中提到 Beam Search 的时间和得分函数调用次数成正比,如下图所示,因此作者希望通过减少得分函数的调用次数,从而提升 Beam Search 效率。
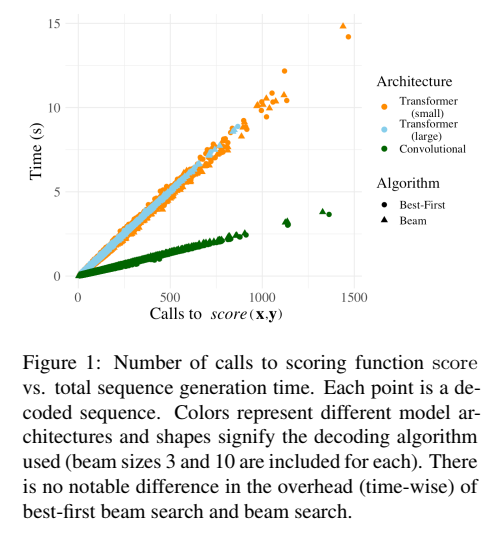
Best-First Beam Search 使用了优先队列并定义新的比较运算符,从而可以减少调用得分函数的次数,更快停止搜索。
3. References
Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation
吴恩达 深度学习 笔记 Course 5 Week 3 Sequence Models
Modeling Coverage for Neural Machine Translation
COVERAGE-BASEDNEURALMACHINETRANSLATION
Coverage-based Neural Machine Translation
A Diversity-Promoting Objective Function for Neural Conversation Models
A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号